
ホームページ >バックエンド開発 >Python チュートリアル >Python の DataFrame は Excel を結合した cells_python を実装します
Python の DataFrame は Excel を結合した cells_python を実装します

- 不言オリジナル
- 2018-04-02 16:19:2110060ブラウズ
この記事では主に Excel のセル結合を実装するための DataFrame を紹介します。興味のある方は参考にしてください。仕事で Excel にデータを出力する必要があることがよくあります。たとえば、以下のテーブルでは、列 B と C の対応するセルを列 A の値に基づいてマージする必要があります。 pandas の to_excel メソッドはインデックスのみをマージできますが、 xlsxwriter では merge_range メソッドを使用できます。が提供されていても、それは基本的な方法にすぎず、最終的に調整するために毎回面倒なテストを書く必要があり、うまく再利用できません。そこで、dataframeとmerge_rangeを組み合わせたメソッドを自分で書きたいと思います。一般的なアイデアは次のとおりです:
1. MY_DataFrame クラスを定義し、DataFrame クラスを継承します。これにより、データ構造を自分で再編成することなく、パンダの多くの機能を活用できます。2. my_mergewr_excel メソッドを定義します。パラメータは、Excel を出力するパス、結合する必要があるかどうかを決定するために使用される key_cols リスト、およびカプセル化する必要があるセルの列を示すために使用されるリストです。 MY_DataFrame を My_Module モジュールとして再利用します。 
2。グループをマージする必要があります。それ以外の場合、グループ (行) をマージする必要はありません (CN=1 は、グループ データ行が一意であり、マージする必要がないことを意味します)
3.マージされた場合、現在の列が指定されたパラメーター [列のマージ] にあるかどうかを判断します。そうである場合は、マージを使用して Excel セルを書き込みます。それ以外の場合は、通常どおり Excel セルを書き込みます。
4. 結合する必要がある列で、RN=1 の場合、merge_range を呼び出して CN セルを一度に書き込みます。RN=1 の場合、セルは結合されて書き込まれているためです。 erge_range が繰り返し呼び出される場合、Excel ドキュメントを開くときにエラーが報告されます。
写真付きの説明は次のとおりです:
具体的なコードは次のとおりです:
# -*- coding: utf-8 -*-
"""
Created on 20170301
@author: ARK-Z
"""
import xlsxwriter
import pandas as pd
class My_DataFrame(pd.DataFrame):
def __init__(self, data=None, index=None, columns=None, dtype=None, copy=False):
pd.DataFrame.__init__(self, data, index, columns, dtype, copy)
def my_mergewr_excel(self,path,key_cols=[],merge_cols=[]):
# sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True):
self_copy=My_DataFrame(self,copy=True)
line_cn=self_copy.index.size
cols=list(self_copy.columns.values)
if all([v in cols for i,v in enumerate(key_cols)])==False: #校验key_cols中各元素 是否都包含与对象的列
print("key_cols is not completely include object's columns")
return False
if all([v in cols for i,v in enumerate(merge_cols)])==False: #校验merge_cols中各元素 是否都包含与对象的列
print("merge_cols is not completely include object's columns")
return False
wb2007 = xlsxwriter.Workbook(path)
worksheet2007 = wb2007.add_worksheet()
format_top = wb2007.add_format({'border':1,'bold':True,'text_wrap':True})
format_other = wb2007.add_format({'border':1,'valign':'vcenter'})
for i,value in enumerate(cols): #写表头
#print(value)
worksheet2007.write(0,i,value,format_top)
#merge_cols=['B','A','C']
#key_cols=['A','B']
if key_cols ==[]: #如果key_cols 参数不传值,则无需合并
self_copy['RN']=1
self_copy['CN']=1
else:
self_copy['RN']=self_copy.groupby(key_cols,as_index=False).rank(method='first').ix[:,0] #以key_cols作为是否合并的依据
self_copy['CN']=self_copy.groupby(key_cols,as_index=False).rank(method='max').ix[:,0]
#print(self)
for i in range(line_cn):
if self_copy.ix[i,'CN']>1:
#print('该行有需要合并的单元格')
for j,col in enumerate(cols):
#print(self_copy.ix[i,col])
if col in (merge_cols): #哪些列需要合并
if self_copy.ix[i,'RN']==1: #合并写第一个单元格,下一个第一个将不再写
worksheet2007.merge_range(i+1,j,i+int(self_copy.ix[i,'CN']),j, self_copy.ix[i,col],format_other) ##合并单元格,根据LINE_SET[7]判断需要合并几个
#worksheet2007.write(i+1,j,df.ix[i,col])
else:
pass
#worksheet2007.write(i+1,j,df.ix[i,j])
else:
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
#print(',')
else:
#print('该行无需要合并的单元格')
for j,col in enumerate(cols):
#print(df.ix[i,col])
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
wb2007.close()
self_copy.drop('CN', axis=1)
self_copy.drop('RN', axis=1)
 コールコード:
コールコード:
import My_Module
DF=My_DataFrame({'A':[1,2,2,2,3,3],'B':[1,1,1,1,1,1],'C':[1,1,1,1,1,1],'D':[1,1,1,1,1,1]})
DF
Out[120]:
A B C D
0 1 1 1 1
1 2 1 1 1
2 2 1 1 1
3 2 1 1 1
4 3 1 1 1
5 3 1 1 1
DF.my_mergewr_excel('000_2.xlsx',['A'],['B','C'])
効果は次のとおりです:
A 列と B 列を結合するように設定することもできます:
DF.my_mergewr_excel('000_2.xlsx',['A'],['A','B'])
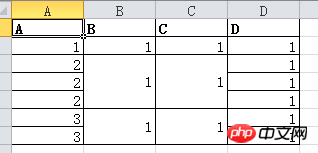 その効果は次のとおりです:
その効果は次のとおりです:
以上がPython の DataFrame は Excel を結合した cells_python を実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。