
ホームページ >バックエンド開発 >Python チュートリアル >Python動的クローラーの共有例
Python動的クローラーの共有例

- 小云云オリジナル
- 2018-03-30 16:41:113978ブラウズ
この記事では、主に Python 動的クローラーの例を紹介します。Python を使用して従来の静的 Web ページをクロールする場合、HTML ページ全体を取得するために urllib2 がよく使用され、HTML ファイルから対応するキーワードが単語ごとに検索されます。以下に示すように:
#encoding=utf-8
import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"up=urllib2.urlopen(url)#打开目标页面,存入变量upcont=up.read()#从up中读入该HTML文件key1='<a href="http'#设置关键字1key2="target"#设置关键字2pa=cont.find(key1)#找出关键字1的位置pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找)urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据)print urlx
ただし、動的ページでは、表示されるコンテンツは HTML ページを通じて表示されないことが多く、js やその他のメソッドを呼び出すことによってデータベースからデータが取得され、Web ページにエコーされます。
国家発展改革委員会の Web サイトにある「登録情報」(http://beian.hndrc.gov.cn/) を例として、このページの提出項目の一部をキャプチャしたいと思います。たとえば、「http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518」などです。
次に、ブラウザでこのページを開きます:
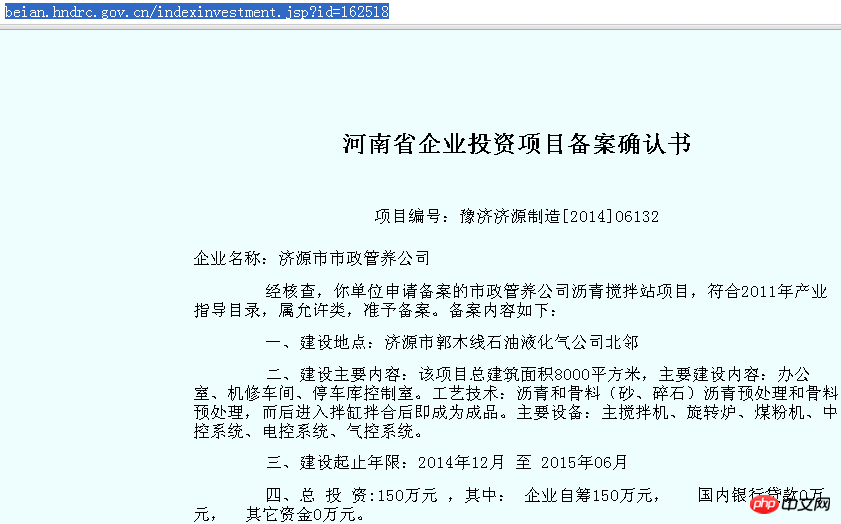
関連情報が完全に表示されますが、以前の方法:
up=urllib2.urlopen(url) cont=up.read()
に従う場合、上記のコンテンツをキャプチャすることはできません。
このページの対応するソースコードを見てみましょう:

ソースコードから、この「提出確認レター」は「空白を埋める」形式であることがわかり、HTML はテキストを提供しますjs は、さまざまな ID に応じてさまざまな変数を提供し、テキスト テンプレートに「記入」して、特定の「提出確認レター」を形成します。したがって、この HTML を取得するだけでは、いくつかのテキスト テンプレートのみを取得できますが、特定のコンテンツは取得できません。
では、それらの特定のコンテンツを見つけるにはどうすればよいでしょうか? Chrome の「デベロッパー ツール」を使用すると、実際のコンテンツ プロバイダーを確認できます。
Chrome ブラウザを開き、キーボードの F12 を押してこのツールを呼び出します。以下に示すように:
このとき、「ネットワーク」ラベルを選択し、アドレスバーにこのページ「http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518」と入力し、ブラウザーはこの応答のプロセス全体を分析します。赤いボックス内のファイルは、この応答内のブラウザーと Web バックエンド間のすべての通信です。
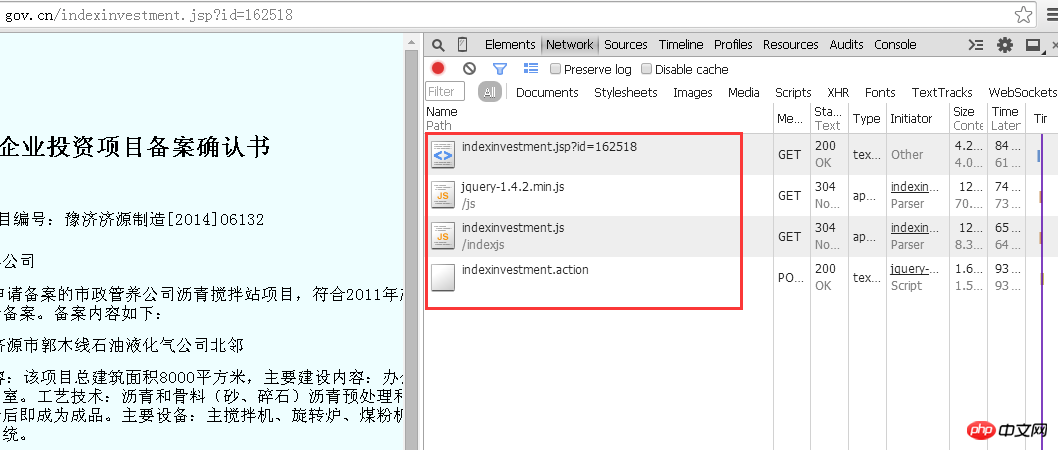
異なる企業に対応する異なる情報を取得したいため、ブラウザからサーバーに送信されるリクエストには現在の企業IDに関連するパラメータが含まれている必要があります。
では、パラメータとは何でしょうか? URL には「jsp?id=162518」があり、疑問符はパラメータが呼び出されることを示し、その後に呼び出されるパラメータである ID 番号が続きます。これらのファイルを分析すると、「indexinvestment.action」ファイルに企業情報が存在することがわかります。
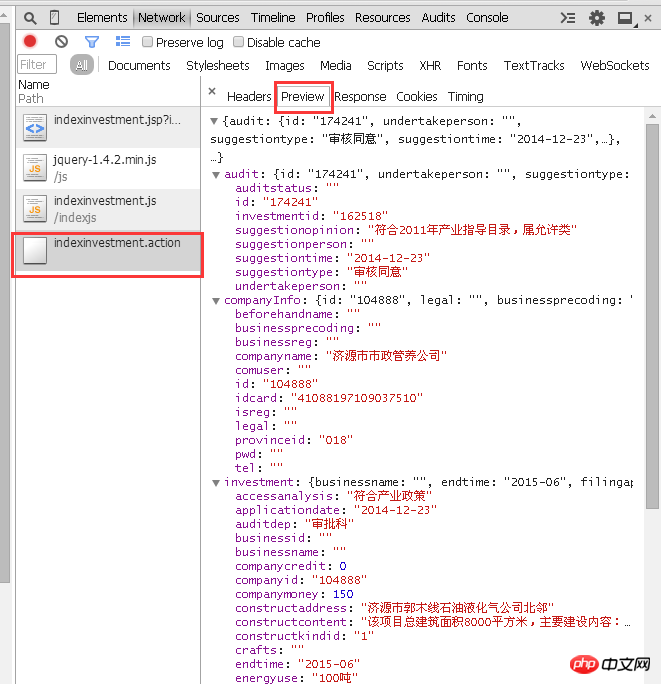
ただし、このファイルをダブルクリックして開くと、企業情報は取得されず、大量のコードが取得されます。表示する情報の数を示す対応するパラメーターがないためです。図に示すように:

それでは、どのようにパラメータを渡せばよいのでしょうか?この時点では、まだ F12 ウィンドウを見ています:
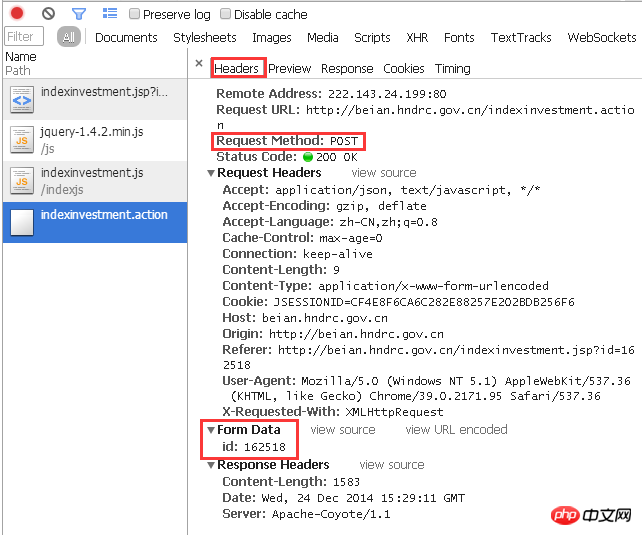
「ヘッダー」列には、この応答のプロセスが明確に示されています:
ターゲット URL の場合、ID 162518 のパラメーターが POST 経由で渡されます。
まず手動でやってみましょう。 jsはどうやってパラメータを呼び出すのでしょうか?はい、上で述べたように、疑問符 + 変数名 + 等号 + 変数に対応する数値です。つまり、ID 162518 のパラメーターをページ「http://beian.hndrc.gov.cn/indexinvestment.action」に送信する場合は、URL の後に
"?id=162518" を追加する必要があります。
「http://beian.hndrc.gov.cn/indexinvestment.action?id=162518」。
この URL をブラウザに貼り付けて見てみましょう:

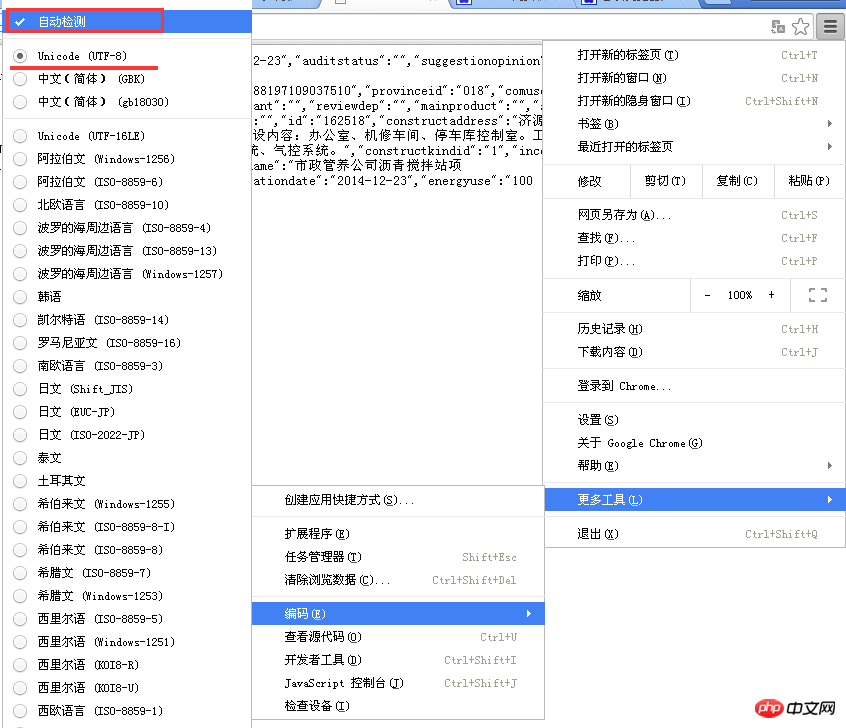
コンテンツがあるようですが、すべて文字化けしています。どうすれば壊れますか?詳しい友人なら、これがエンコードの問題であることが一目で分かるかもしれません。これは、応答で返されたコンテンツがブラウザのデフォルトのエンコーディングと異なるためです。 Chrome の右上隅にあるメニュー - その他のツール - コーディング - 「自動検出」に移動するだけです。 (実際には、これは UTF-8 エンコーディングであり、Chrome のデフォルトは簡体字中国語です)。以下に示すように:
さて、実際の情報ソースは掘り出されました。残っているのは、Python を使用してこれらのページの文字列を処理し、それらを切り取ってつなぎ合わせて新しい「プロジェクト ファイリング ブック」を再構築することだけです。
次に、for、while などのループを使用して、これらの「登録書類」をバッチで取得します。
「静的 Web ページ、動的 Web ページ、シミュレートされたログインなどのいずれであっても、まずロジックを分析して理解し、それからコードを記述する必要があります」と同じように、プログラミング言語は単なるツールであり、大切なのは問題を解決するという考え方です。アイデアが得られたら、問題を解決するためのツールを探すことができます。
以上がPython動的クローラーの共有例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。