
ホームページ >バックエンド開発 >PHPチュートリアル >分散型リアルタイム ログ分析ソリューション ELK 導入アーキテクチャ
分散型リアルタイム ログ分析ソリューション ELK 導入アーキテクチャ

- 不言オリジナル
- 2018-05-05 15:10:124842ブラウズ
ELK は現在最も人気のある集中ログ ソリューションとなっており、主に Beats、Logstash、Elasticsearch、Kibana などのコンポーネントで構成されており、リアルタイム ログの収集、保存、表示などのワンストップ ソリューションを共同で実行します。この記事では主に、分散型リアルタイム ログ分析ソリューションの ELK 導入アーキテクチャについて紹介します。必要な方はぜひご覧ください
おすすめコース→:「Elasticsearch 全文検索の実践」(実践ビデオ)
1. 概要
ELK は現在最も人気のある集中ログ ソリューションとなっており、主に Beats で構成されています。 Logstash、Elasticsearch、Kibana リアルタイム ログの収集、保存、表示などのワンストップ ソリューションを共同で完成させるための他のコンポーネントで構成されています。この記事では、ELK の一般的なアーキテクチャを紹介し、関連する問題を解決します。
Filebeat: Filebeat は、サービス リソースをほとんど消費しない軽量のデータ収集エンジンです。ELK ファミリの新しいメンバーであり、アプリケーション サーバー側のログ収集エンジンとして Logstash を置き換えることができ、収集されたデータの収集をサポートします。データを Kafka、Redis、およびその他のキューに出力します。
Logstash: Filebeat よりも重いデータ収集エンジンですが、多数のプラグインが統合されており、豊富なデータ ソースの収集をサポートしており、収集されたデータはフィルタリング、分析、ログ形式でのフォーマットが可能です。 。
Elasticsearch: Apache
Lucene に基づいて実装された分散データ検索エンジンはクラスター化可能で、データの一元的なストレージと分析に加え、強力なデータ検索と集計機能を提供します。Kibana: データ視覚化プラットフォーム。この Web プラットフォームを通じて、Elasticsearch の関連データをリアルタイムで表示し、豊富なチャート統計機能を提供できます。
2. ELK 共通デプロイメント アーキテクチャ
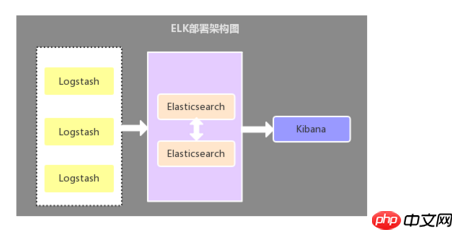
2.1. ログ コレクターとしての Logstash
このアーキテクチャは、Logstash コンポーネントがログ コレクターとして各アプリケーション サーバーにデプロイされ、その後データが配置されます。 Logstash によって収集されたデータは、Elasticsearch ストレージに送信される前にフィルタリング、分析、フォーマットされ、最後に視覚的な表示に Kibana が使用されます。このアーキテクチャの欠点は、Logstash がサーバー リソースを消費するため、アプリケーション サーバーの負荷が増大することです。
2.2. ログコレクターとしての Filebeat
このアーキテクチャと最初のアーキテクチャの唯一の違いは、アプリケーション側のログ コレクターが Filebeat に置き換えられ、使用するサーバー リソースが少なくなることです。したがって、Filebeat をアプリケーション サーバー上のログ コレクターとして使用します。一般に、Filebeat は Logstash と一緒に使用され、現在最も一般的に使用されているアーキテクチャでもあります。
2.3. キャッシュキューを導入するデプロイメントアーキテクチャ
このアーキテクチャは、Filebeat によって収集されたデータを Kafka に送信するための 2 番目のアーキテクチャに基づいて Kafka メッセージキュー (他のメッセージキューでも可) を導入します。 Logstasth を介して Kafka でデータを読み取ります。このアーキテクチャは主に、大規模なデータ量でのログ収集ソリューションを解決するために使用され、データのセキュリティを解決し、Logstash と Elasticsearch の負荷圧力のバランスをとるために使用されます。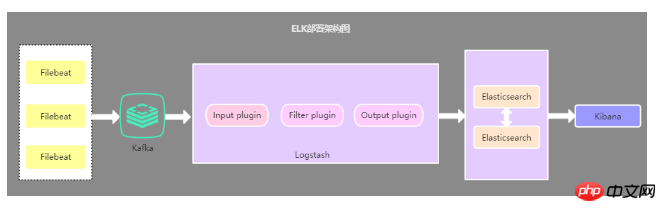
1 番目のデプロイメント アーキテクチャは、リソース占有の問題により、現在最も使用されていると個人的に感じています。データ量が大きい場合、Filebeat は圧力に敏感なプロトコルを使用して Logstash または Elasticsearch にデータを送信するため、他の要件がない限り、デプロイメント アーキテクチャにメッセージ キューを導入する必要はありません。 Logstash がデータの処理でビジー状態の場合、Filebeat に読み取り速度を下げるように指示します。輻輳が解決されると、Filebeat は元の速度に戻り、データの送信を続けます。
コミュニケーションと学習グループをお勧めします: 478030634。上級アーキテクトが記録したいくつかのビデオを共有します: Spring、MyBatis、Netty ソース コード分析、高同時実行性、高性能、分散型、マイクロサービス アーキテクチャ、JVM パフォーマンスの最適化などの原則。建築家に必要な知識体系。無料の学習リソースを受け取ることもでき、これまでに多くのメリットがあります:
 3. 問題と解決策
3. 問題と解決策
システム アプリケーションのログは通常、特定の形式で出力されます。そのため、ELK を使用してログを収集する場合は、同じログに属する複数行のデータを結合する必要があります。 解決策: Filebeat または Logstash で複数行の複数行マージ プラグインを使用して、次のことを実現します。 複数行の複数行マージ プラグインを使用する場合は、ELK デプロイメント アーキテクチャが異なる場合があるという事実に注意する必要があります。これがこの記事の場合、最初のデプロイメント アーキテクチャの場合は、マルチラインを構成して Logstash で使用する必要があります。2 番目のデプロイメント アーキテクチャの場合、マルチラインを構成して Filebeat で使用する必要があります。 Logstash で複数行を構成する必要があります。 1. Filebeat で複数行を設定する方法: パターン: 正規表現 negate: デフォルトは false で、パターンに一致する行は前の行にマージされます。 true は、パターンに一致しない行が前の行にマージされることを意味します match: 平均が前の行の最後にマージされた後、平均が前の行の先頭にマージされる前 例: pattern: '[' この設定は、パターン pattern に一致しない行を前の行の末尾にマージすることを意味します 2. Logstash で複数行を設定する方法 (1) Logstash で設定されている属性の値は前であり、Filebeat での after に相当し、Logstash で設定されている属性の値は次であり、Filebeat での before に相当します。 質問: Kibana に表示されるログの時間フィールドをログ情報の時間に置き換えるにはどうすればよいですか? デフォルトでは、Kibana で表示される時刻フィールドはログ情報の時刻と一致しません。デフォルトの時刻フィールドの値はログが収集された時点の時刻であるため、このフィールドの時刻を現在の時刻に置き換える必要があります。ログ情報の時刻。 解決策: grok 単語セグメンテーション プラグインと日時書式設定プラグインを使用して、次のことを実現します Logstash 構成ファイルのフィルターで grok 単語セグメンテーション プラグインと日時書式設定プラグインを次のように構成します。 CUSTOMER_TIME %{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME} 質問: Kibana に渡す方法データを表示するためにさまざまなシステム ログ モジュールを選択します 解決策: さまざまなシステム モジュールを識別する新しいフィールドを追加するか、さまざまなシステム モジュールに基づいて ES インデックスを構築します ここでの説明には、2 番目のデプロイメント アーキテクチャが使用されます。 Filebeat の構成内容は次のとおりです。システム モジュール設定 ES インデックスを作成し、Kibana で対応するインデックス パターン マッチングを作成します。ページ上のインデックス パターン ドロップダウン ボックスから、さまざまなシステム モジュール データを選択できます。 この記事では主に、ELK リアルタイム ログ分析の 3 つのデプロイメント アーキテクチャと、さまざまなアーキテクチャが解決できる問題について紹介します。これらの 3 つのアーキテクチャのうち 2 番目のデプロイメント方法は、現在最も一般的で一般的に使用されています。最後に、ログ分析における ELK の問題と解決策をいくつか紹介します。最後に、ELK は分散ログ データの集中クエリと管理に使用できるだけでなく、プロジェクト アプリケーションやサーバー リソースの監視、その他のシナリオにも使用できます。 。 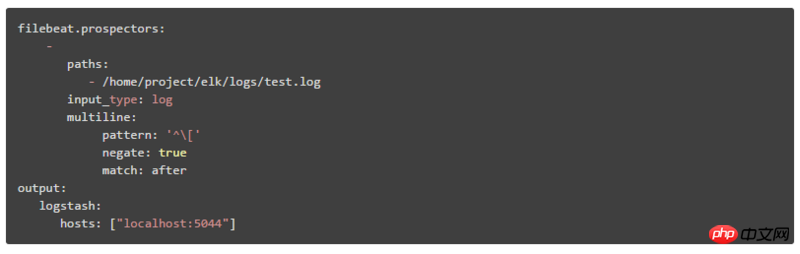
negate: true
match: after
(2) pattern => "%{LOGLEVEL}s*]" "%{LOGLEVEL}s*]" の LOGLEVEL は、Logstash の事前に作成された規則的なマッチング パターンです。詳しくは、以下を参照してください。参照してください: https://github.com /logstash-p...
注: 内容の形式は次のとおりです: [カスタム式名] [正規表現]
Then logstash では次のように引用できます: 

ここでは 2 番目のデプロイメント アーキテクチャについて説明します。これは 2 つのステップに分かれています: 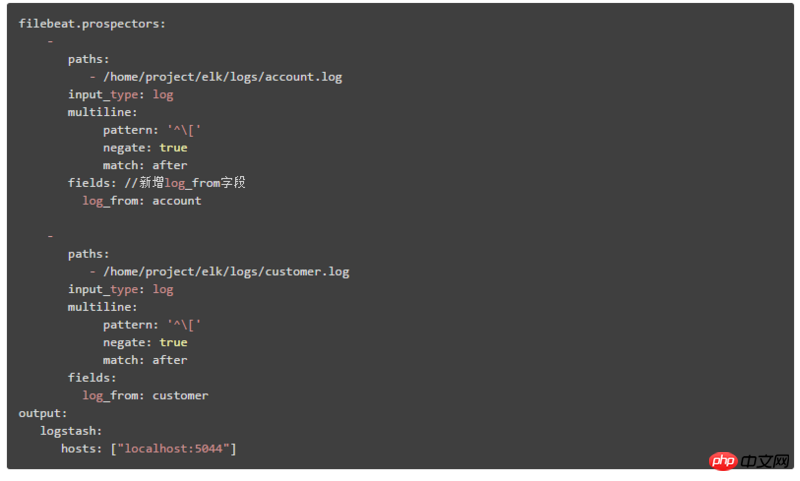
② Logstash の出力構成コンテンツを次のように変更します:
出力にインデックス属性を追加します。%{type} は、さまざまな document_type 値に従って ES インデックスを構築することを意味しますIV. 概要
以上が分散型リアルタイム ログ分析ソリューション ELK 導入アーキテクチャの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。