
ホームページ >ウェブフロントエンド >jsチュートリアル >Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします

- 小云云オリジナル
- 2018-03-07 14:01:354194ブラウズ
1. はじめに
クローラー プログラムを使用して Web ページをクロールする場合、静的ページのクロールは一般に比較的簡単であり、これまでにかなりの数のケースを作成しました。しかし、js を使用して動的に読み込まれたページをクロールするにはどうすればよいでしょうか?
動的 js ページにはいくつかのクロール方法があります:
selenium+phantomjs によって実装されます。
phantomjs はヘッドレス ブラウザであり、selenium は自動テスト フレームワークです。ヘッドレス ブラウザを通じてページをリクエストし、js がロードされるのを待ってから、自動テスト Selenium を通じてデータを取得します。ヘッドレス ブラウザは大量のリソースを消費するため、パフォーマンスが不足します。
Scrapy-splash フレームワーク:
Splash は、JS レンダリング サービスとして、Twisted と QT に基づいて開発された軽量ブラウザ エンジンであり、ダイレクト http API を提供します。高速かつ軽量な機能により、分散開発が容易になります。
スプラッシュ クローラー フレームワークとスクレイピー クローラー フレームワークは統合されており、この 2 つは相互に互換性があり、クローリング効率が向上します。
2. Splash環境の構築
Splashサービスはdockerコンテナをベースとしているため、最初にdockerコンテナをインストールする必要があります。
2.1 Docker のインストール (Windows 10 Home バージョン)
Win 10 Professional バージョンまたは他のオペレーティング システムの場合、Windows 10 Home バージョンに Docker をインストールするには、ツールボックスを介してインストールする必要があります (最新)ツールです。
docker のインストールについてはドキュメントを参照してください: WIN10 に Docker をインストール
2.2 Splash のインストール
docker pull scrapinghub/splash
2.3 Splash サービスを開始
docker run -p 8050:8050 scrapinghub/splash
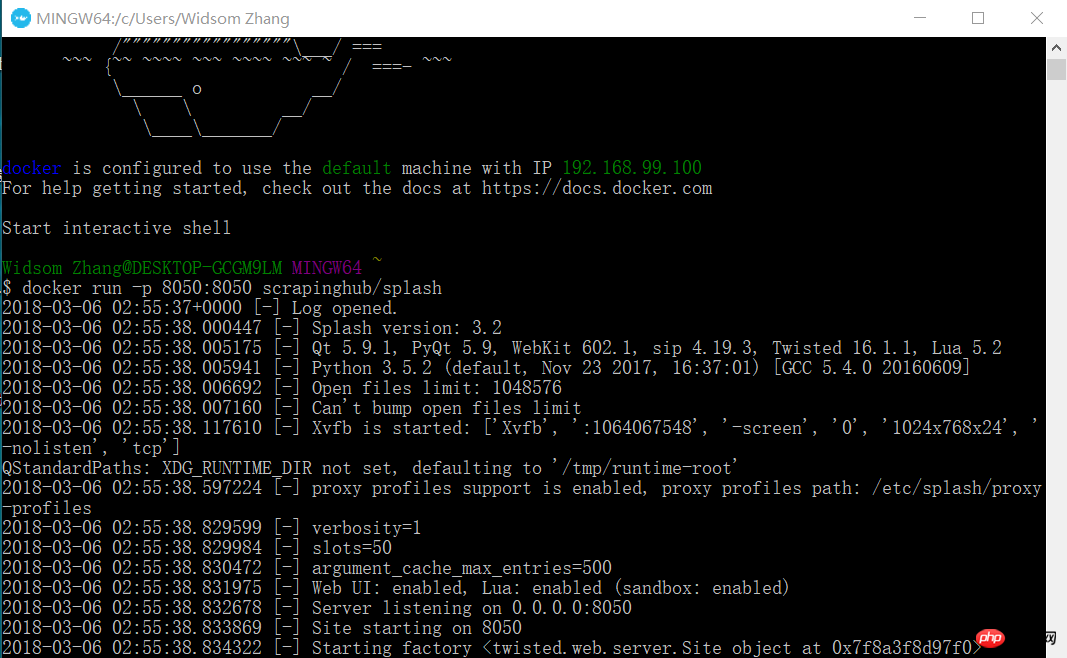
このとき、ブラウザを開いて 192.168.99.100:8050 と入力し、このようなインターフェースが表示されます。
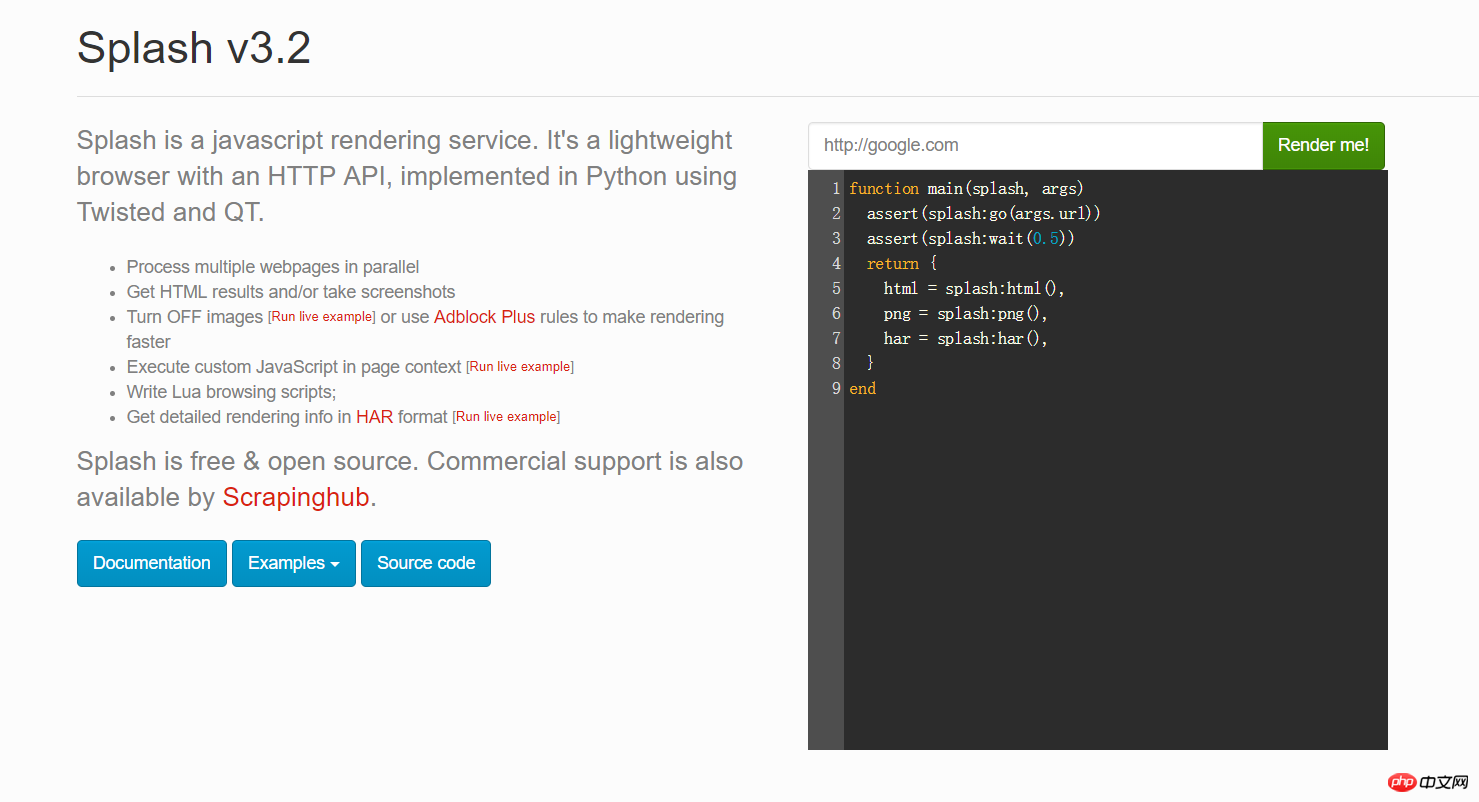
上の画像の赤いボックスに任意の URL を入力し、[レンダリングしてください] をクリックして、レンダリング後の様子を確認します
2.4 Python の Scrapy-splash パッケージをインストールします
pip install scrapy-splash
3。 Google ニュースを例としてテストを行います。
ビジネス上の必要により、Google ニュースなどの一部の海外ニュース ウェブサイトをクロールします。しかし、実際には js コードであることがわかりました。そこで私はscrapy-splashフレームワークを使い始め、Splashのjsレンダリングサービスと連携してデータを取得しました。具体的には、次のコードを確認してください:
3.1 settings.py 構成情報
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 items フィールド定義
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 Spider コード
Spider ディレクトリに、次の内容を含む new_spider.py ファイルを作成します:
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードしますUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url'] = Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードしますUrl
item['action_url'] = actionUrl
item['source'] = source yield item3.4 パイプライン .py コード
は、項目データを mysql データベースに保存します。
db_newsデータベースを作成する
CREATE DATABASE db_news
tb_newsテーブルを作成する
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;NewsPipelineクラス
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 スクレイピークローラを実行する
コンソールで実行します:
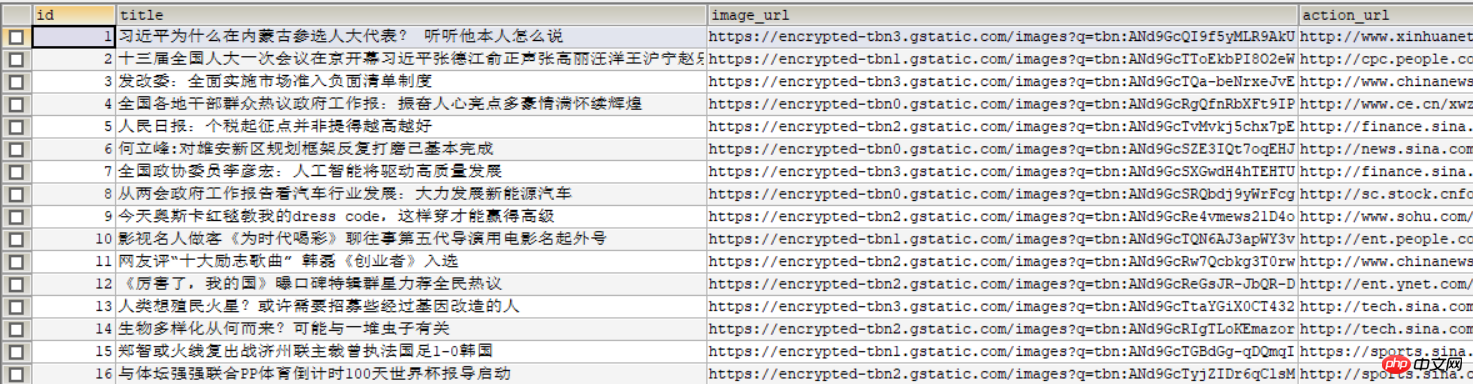
そうです次の画像がデータベースに表示されます:
関連する推奨事項:
以上がScrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。