
ホームページ >データベース >mysql チュートリアル >MySQL クエリ ステートメントの複雑なクエリ
MySQL クエリ ステートメントの複雑なクエリ
- 赶牛上岸オリジナル
- 2018-03-06 15:37:129209ブラウズ
MySQL はリレーショナル データベース管理システムであり、リレーショナル データベースはすべてのデータを 1 つの大きなウェアハウスに置くのではなく、異なるテーブルに保存するため、速度と柔軟性が向上します。 MySQL には多くの複雑なクエリが存在することが多く、みんなの時間を節約するために、エディターは一般的に使用される複雑なクエリをいくつかまとめました。
MySQL複雑なクエリ
1. グループクエリ:
1. キーワード: GROUP
による 2. 使用法: グループ BY ステートメントは、合計関数 (SUM など) を結合して、1 つ以上の列に従って結果セットをグループ化するために使用されます。多くの場合、合計関数を追加する必要があります。 GROUP BY ステートメント。
次の 2 つのテーブルが指定されています。1 つは emp で、もう 1 つは dept です。以下に示すように、これら 2 つのテーブルを次のクエリで操作します。 1つ目: emp
テーブル
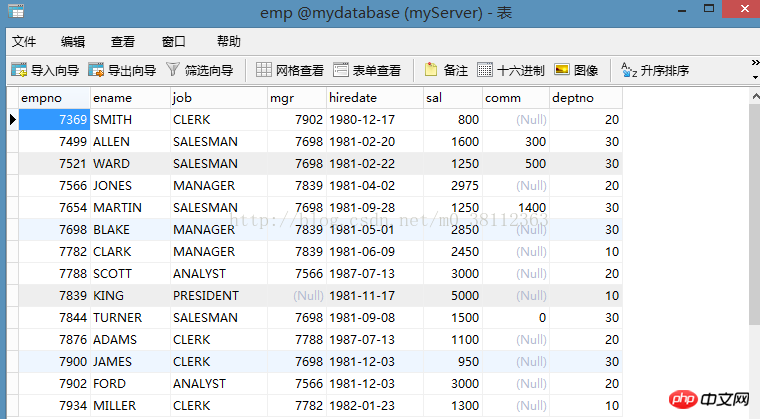
2つ目:
deptテーブル
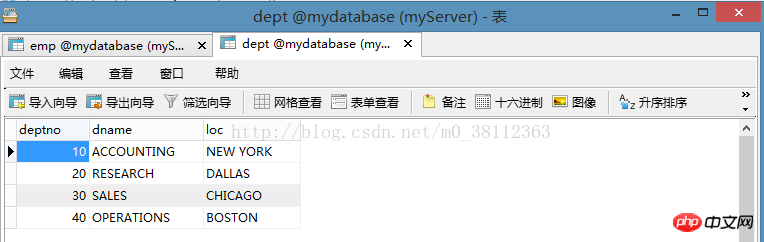
従業員の各部門の給与総額をクエリします。ステートメントは次のとおりです: SELECT deptno,SUM(sal)FROM emp GROUP BY deptno; 注: ここでは給与総額をクエリします ( sal) は各部門の部門番号 (deptno) に従ってグループ化する必要があるため、合計には sum() が使用されます。
3 、次のようになります。 whereとhavingは両方とも条件判断ですhavingを紹介する前に、whereとhavingの違いを見てみましょう
 where
where
はクエリ結果を決定するために使用されます。グループ化する前に、以下の行を削除してください。 where 条件を満たさない場合、つまり、条件に集計関数を含めることはできず、where 条件を使用して特定の行を表示します。 havingの機能は、条件を満たすグループをフィルタリングすることです。つまり、条件には集計関数が含まれることがよくあります。havingを使用します。
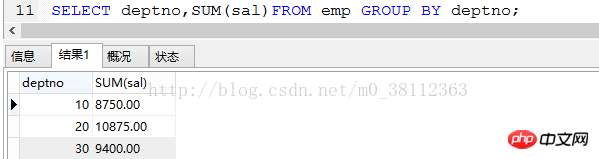
条件には特定のグループが表示されます。また、複数のグループ化基準を使用してグループ化することもできます。 例: 合計給与が 10,000 を超える emp テーブル内の部門番号をクエリしたいとします。ステートメントは次のとおりです: SELECT
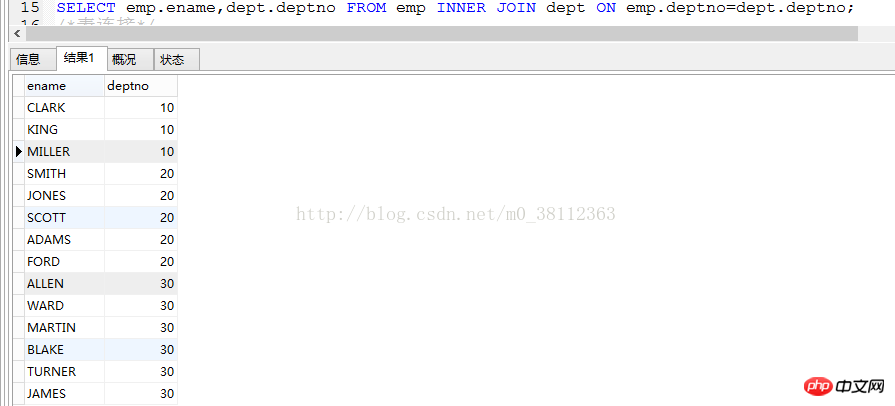
deptno,SUM(sal)FROM emp GROUP BY deptno HAVING SUM(sal)>10000; 結果は次のとおりです: これ調べ方は、給与総額が10,000を超える部門番号は20です(給与総額も分かりやすく表示されています)。 2. テーブルの結合クエリ: これらのテーブルの列間の関係に基づいて、2 つ以上のテーブルのデータをクエリします。 1. 内部結合。 (内部結合): 構文: select フィールド名 1, フィールド名 2 from table1 [INNER] join table2 ON table1.フィールド名=テーブル2.フィールド名; 注: 内部結合は、接続されている他のテーブルに一致する行がないすべての行を結果から削除します。クエリできるのは接続されたテーブルが所有する情報 のみであるため、内部結合では情報が失われる可能性があり、内部では可能性があります。省略します。 例: emp テーブルと dept テーブルを結合し、ename と deptno をクエリすると、ステートメントは次のようになります: SELECT emp.ename,dept.deptno FROM emp INNER JOIN dept ON emp。 deptno=dept .deptno; 別の書き方もあります: SELECT emp.ename,dept.deptno from emp,dept where emp.deptno=dept.deptno; 注: dept テーブルに 40 の deptno があることがわかりますが、クエリ後には存在しません。 emp の deptno フィールドに値 40 がないため、内部結合を使用して接続します。 dept テーブル内の deptno フィールド値が 40 のレコードは自動的に削除されます。 2. 外部結合: 2.1: 左外部結合: 結果セットには、左側のテーブルのすべての行が保持されますが、最初のテーブルに一致する 2 番目のテーブルの行のみが含まれます。 2 番目のテーブルの対応する空の行は NULL 値に入れられます。 2.2: 右外部結合: 結果セットには、右テーブルのすべての行が保持されますが、最初のテーブルに一致する 2 番目のテーブルの行のみが含まれます。 2 番目のテーブルの対応する空の行は NULL 値に入れられます。 左外部結合と右外部結合を使用して 2 つのテーブルの位置を交換しても、同じ効果を達成できます。 ここで、グループ化を使用してテーブルを結合するクエリを実行します 例: 各部門の給与総額をempにクエリし、その部門に対応させたいとします。部門テーブルの名前 この文を解析します: クエリ フィールドは emp の各部門の sal (給与総額) です。ここではグループ クエリを使用する必要がありますが、部門名 (dname) もクエリする必要があります。 dname は dept テーブルにあるため、emp テーブルと dept テーブルを接続する必要があります アイデア 1: まず必要なフィールドをすべてクエリしてからグループ化します。ステートメントは次のとおりです: SELECT e.deptno,d.dname,SUM(e.sal) FROM emp e INNER JOIN dept d ON e.deptno=d.deptno GROUP BY d.deptno;) (ここでは が使用されていることに注意してください。emp の別名は e、dept の別名は d です) 2 番目の書き方: SELECT e.deptno,d。 dname,SUM(e.sal) FROM emp e,dept d WHEREe.deptno=d.deptno GROUP BY d.deptno; これら 2 つの書き込み方法の結果は、次のように同じです。 アイデア 2: emp の各部門の給与総額をクエリし、この結果セットをテーブル (ここではテーブル 1 と呼びます) として扱い、次に、テーブル 1 を dept テーブルに接続して、対応する部門名 (dname ) をクエリします。 ステップ 1: SELECT deptno,SUM(sal) FROM emp GROUP BY deptno; このステートメントは、各部門の合計給与をクエリします。次に、emp テーブルを dept テーブルと比較します。 接続: =d.deptno ;このようにして、目的の結果がクエリされます。ここでの xin は次のとおりです。
このコードは非常に長いです。実際、このアイデアは非常に明確です。間違いを犯すのは簡単ではありません。練習すれば、上手に書けるようになります。 3. ページネーション: キーワード: LIMIT 構文: select * from tableName 条件制限 現在のページ番号 * ページ容量 - 1、ページ容量 一般制限は によるオーダーと一緒に使用されます。たとえば、部門番号の昇順に並べられた emp テーブルのレコード 5 ~ 10 をクエリし、1 ページに 5 件のレコードを表示するには、ステートメントは次のようになります。 このように、必要な結果をクエリできます。最後のパラメータ 5 はページ容量であり、このページに表示される行数 (つまり、先頭からのレコード バーの数) であることに注意してください。このページの最後まで)。 たとえば、17 ページのレコードをクエリしたい場合、各ページには 10 レコードが表示されます: LIMIT 17*10-1,10; Four: IN キーワード: In サブクエリの戻り値の結果に複数の条件がある場合は、IN を使用する必要があります。 関連する推奨事項: MySQL5.7 で my.ini ファイルが見つからない問題を解決する方法 mysql max と where の間の実行の問題について MySQL 統計 詳細な概要

以上がMySQL クエリ ステートメントの複雑なクエリの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。