
ホームページ >バックエンド開発 >PHPチュートリアル >スレッドと httpclient を使用してページビューを増やす方法
スレッドと httpclient を使用してページビューを増やす方法

- 小云云オリジナル
- 2018-03-05 10:50:041941ブラウズ
ここでリクエストを考えているところですが、リクエストを一度確認すると、ビュー数が 1 増加します。そこでF5を押して更新しましたが、実際には毎回増えず、再度F5を押すと1ずつ増えることが分かりました。基本的な機能分析が完了しました。何かアイデアはありますか?ここで、ページをリクエストし、返された HTML を取得して文字列を解析するだけの以前のクローラーについて考えてみます。そこで私もこの考えに学び、サーバーを使用してリンクをリクエストしました。後は待ち時間だけです。無視して閲覧を続けると、悪意のあるリクエストの疑いが持たれ、アカウントが停止される可能性があります。では、このシナリオに適したテクノロジーは何か考えたことはありますか?はい、スレッドを使用して、各リクエスト後のスリープ時間を設定できます。
すると、一般的な考え方は明らかです。httpClient がリクエストを送信し、スレッドが一時停止時間を制御します。早速、コードの説明に入りましょう:
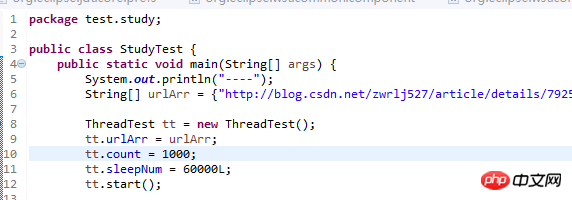
皆さんは上記のメインについてよく知っているはずです。ここでの私の考えは、スレッド クラスには 3 つの変数があるということです。これを使用する前に、変数を設定します。 new は便宜上、後のスレッド実行メソッドで使用されます。ここで、マルチスレッドを実装する 4 つの方法を追加したいと思います。これは以前のブログ投稿で言及されているようです。
マルチスレッドを実装するには 4 つの方法があり、そのほとんどは戻り値のない最初の 2 つです。
1. Thread クラスを継承してスレッドを作成する
Thread クラスは、本質的には Runnable インターフェイスを実装し、スレッドのインスタンスを表すインスタンスです。スレッドを開始する唯一の方法は、Thread クラスの start() インスタンス メソッドを使用することです。 start() メソッドは、新しいスレッドを開始して run() メソッドを実行するネイティブ メソッドです。この方法でマルチスレッドを実装するのは非常に簡単です。独自のクラスを通じて Thread を直接拡張し、run() メソッドをオーバーライドすることで、新しいスレッドを開始し、独自に定義した run() メソッドを実行できます。例:
public class MyThread extends Thread { public void run() { System.out.println("MyThread.run()") } } MyThread myThread1 = new MyThread myThread2 = new MyThread(); myThread1 .start(); myThread2.start();
2. Runnable インターフェイスを実装してスレッドを作成する
クラスが別のクラスを拡張している場合、現時点では、Runnable インターフェイスを直接実装できません。
public class MyThread extends OtherClassimplements Runnable { public void run() { System.out.println("MyThread.run()"); }
MyThread を開始するには、まずスレッドを作成し、独自の MyThread インスタンスを渡します:
MyThread myThread = new MyThread(); Thread thread = new Thread(myThread);
実際、Runnable ターゲット パラメータが Thread に渡されると、スレッドの run() メソッド target.run() が呼び出されますので、JDK のソースコードを参照してください:
public void run() { if (target != null) { target.run(); }
3. FutureTask ラッパーを介した Callable インターフェイス スレッドの作成
Callable インターフェイス (メソッドも 1 つだけあります) は次のように定義されます。 V> extends OtherClassimplements Callable
oneCallable = new SomeCallable
4. ExecutorService、Callable、および Future を使用して、結果を返すスレッドを実装します
ExecutorService、Callable、および Future の 3 つのインターフェイスは、実際には Executor フレームワークに属します。結果を返すスレッドはJDK1.5で導入された新機能です。この機能を使用すると、戻り値を取得するために面倒な作業を行う必要がなくなりました。また、たとえ自分で実装したとしても、抜け穴がたくさんある可能性があります。
値を返すことができるタスクは、Callableインターフェースを実装する必要があります。同様に、値を返さないタスクは Runnable インターフェイスを実装する必要があります。
Callable タスクを実行した後、オブジェクトに対して get を呼び出して、Callable タスクによって返されるオブジェクトを取得できます。
注: get メソッドはブロックされています。つまり、スレッドは結果を返さず、get メソッドは永久に待機します。
スレッド プール インターフェイス ExecutorService と組み合わせると、結果を返す伝説的なマルチスレッドを実現できます。
本題に戻りますが、値を返す必要がないため、ここでは最初のものを使用しています。
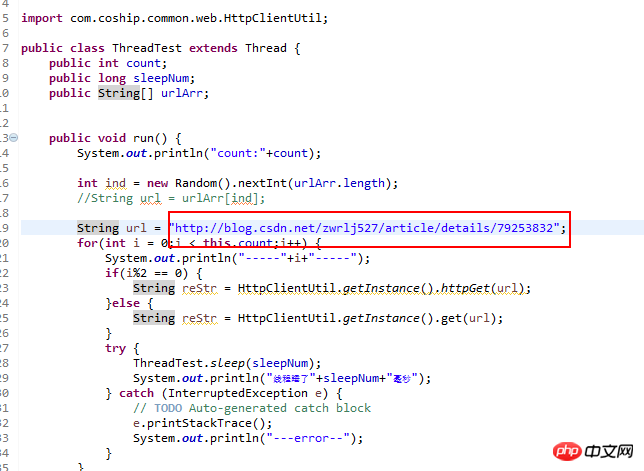
ここに追加されたのは、毎回同じリクエストメソッドを使用することを避け、悪意のあるリクエストとしてリストされるリスクを回避するために、複数のアドレスと奇数偶数リクエストメソッドをブラッシングするというアイデアです。システム。そしてスリープ時間はメインで設定できます。更新前の読み取り量を見てみましょう:
昨夜これを書いてから寝ましたが、コンピューターの電源がオフになっていませんでした。今夜リクエストが何回受信されたかを見てみましょう:
次に、次のリストページを更新して、読書量をもう一度見てみましょう:
元々は 300 以上だった読書量が、現在 600 を超えているのがわかりますか。
IPがずっとこれなので、途中のスリープ時間が少し長くなりますが、切り替え用のIPがあり、切り替えロジックを追加すると効果が高くなります。
理論的に言えば、もちろん、クライアントが同じ IP を複数回要求して 1 回の読み取りとしてカウントするなどの厳密な戦略を実装していない限り、この方法ですべての読み取り量を増やすことができます。 Baidu Wenku のこれらの記事を優れたドキュメントとして評価する方法はわかりませんが、おそらくリクエストの数と関係があると思います。機会があれば、このアイデアを試してみてください。これを変更して 2 つのスレッドを作成し、それらを交互に作成して、1 つのスレッドで 1 つの Web サイトをブラッシングすることもできます (笑)。
でも、あなたのアカウントが禁止されても私を責めないでください(笑)。
関連する推奨事項:
thinkPHP+ajax を使用して統計的なページの pv ビューを達成する方法
以上がスレッドと httpclient を使用してページビューを増やす方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。