



この記事では主に React の起源と開発について説明します。お役に立てれば幸いです。
キャラクター スプライシング時代 - 2004 年
2004 年当時、マーク ザッカーバーグはまだ寮で Facebook のオリジナル バージョンを開発していました。
今年は、誰もが PHP の文字列連結機能を使用して Web サイトを開発しています。
$str = '
- ';
foreach ($talks as $talk) {
$str += '
- ' . $talk->name . ' '; } $str += '
この Web サイト開発方法は、バックエンド開発であろうとフロントエンド開発であろうと、あるいは開発経験がまったくなくても、この方法を使用して大規模な Web サイトを構築できるため、当時は非常に正しいように思えました。
唯一の欠点は、この開発方法では XSS インジェクションやその他の セキュリティ問題 が簡単に発生する可能性があることです。 $talk->name に悪意のあるコードが含まれており、保護措置が講じられていない場合、攻撃者は任意の JS コードを挿入する可能性があります。これにより、「ユーザー入力を決して信頼しない」というセキュリティ ルールが生まれました。
これに対処する最も簡単な方法は、ユーザーからの入力を escape (エスケープ) することです。ただし、これには別の問題も伴います。文字列を複数回エスケープする場合、アンチエスケープの数も同じでなければなりません。そうしないと、元の内容が取得できなくなります。 HTML タグ (マークアップ) を誤ってエスケープすると、HTML タグがユーザーに直接表示され、ユーザー エクスペリエンスが低下します。
XHP 時代 - 2010 年
2010 年、より効率的にコーディングし、HTML タグのエスケープエラーを回避するために、Facebook は XHP を開発しました。 XHP は PHP の 構文拡張 で、開発者は文字列を使用する代わりに PHP で HTML タグを直接使用できるようになります。
$content =
この場合、すべての HTML タグは PHP とは異なる構文を使用しており、どのタグをエスケープする必要があり、どのタグをエスケープする必要がないのかを簡単に区別できます。
その後すぐに、Facebook のエンジニアは、カスタム ラベル も作成でき、カスタム ラベルを組み合わせることで大規模なアプリケーションの構築に役立つ可能性があることを発見しました。
そして、これはまさにセマンティック Web と Web コンポーネントの概念を実装する 1 つの方法です。
$content = <list></list>;
foreach ($talks as $talk) {
$content->appendChild(<talk></talk>);
}
その後、Facebook はクライアントとサーバー間の遅延を減らすために、JS でさらに新しい技術的手法を試みました。クロスブラウザ DOM ライブラリやデータ バインディングなどですが、これらは理想的ではありません。
JSX - 2013
2013 年まで待って、ある日突然、フロントエンド エンジニアの Jordan Walke がマネージャーに、XHP の拡張機能を JS に移行するという大胆なアイデアを提案しました。当時誰もが楽観的だった JS フレームワークと互換性がないため、最初は誰もが彼を気違いだと思っていました。しかし、最終的に彼はマネージャーを説得して、アイデアをテストするために 6 か月の猶予を与えるようにしました。ここで私は、Facebook の優れたエンジニアリング管理哲学は賞賛に値するものであり、学ぶ価値があると言わなければなりません。
添付: Lee Byron 氏が Facebook エンジニアの文化について語る: なぜツールに投資するのか
XHP の拡張機能を JS に移行するには、最初のタスクは、JS が XML 構文をサポートできるようにする拡張機能が必要であることです。この拡張機能は JSX と呼ばれます。当時、Node.js の台頭により、Facebook 内では JS を変換するためのエンジニアリングの実践がすでにかなり行われていました。そのため、JSX の実装は簡単で、わずか 1 週間しかかかりませんでした。
const content = (
<talklist>
{ talks.map(talk => <talk></talk>)}
</talklist>
);
React
それ以来、React の長い行進が始まり、さらに大きな困難がまだ待っています。その中でも最も難しいのは、PHP で更新メカニズムを再現する方法です。
PHP では、データが変更されるたびに、PHP によってレンダリングされた新しいページにジャンプするだけで済みます。
開発者の観点から見ると、この方法でのアプリケーションの開発は非常に簡単です。変更について心配する必要がなく、インターフェイス上のユーザー データが変更されるとすべてが同期されるためです。
データに変更がある限り、ページ全体が再レンダリングされます。
単純で粗雑ではありますが、この方法の欠点も特に顕著です。それは、非常に遅いということです。
「良い状態になる前に状態が必要」とは、移行計画の実現可能性を検証するために、開発者は当面のパフォーマンスの問題に関係なく、使用可能なバージョンを迅速に実装する必要があることを意味します。
DOM
PHP からインスピレーションを得た、JS で再レンダリングを実装する最も簡単な方法は、コンテンツが変更されたときに DOM 全体を再構築し、古い DOM を新しい DOM に置き換えることです。

この方法は機能しますが、シナリオによっては適していません。
たとえば、現在フォーカスされている要素とカーソル、およびページの現在の状態であるテキスト選択とページスクロール位置が失われます。
言い換えると、DOM ノードには状態が含まれます。

状態が含まれているので、古いDOMの状態を記録して、それを新しいDOMに復元するだけで十分ではないでしょうか?
しかし、残念ながら、この方法は実装が複雑なだけでなく、すべての状況をカバーできるわけではありません。
OSX コンピューターでページをスクロールするとき、ある程度のスクロールの慣性が発生します。ただし、JS には、スクロール慣性の読み取りまたは書き込みに対応する API が提供されていません。
iframe を含むページの場合、状況はさらに複雑になります。別のドメインからのものである場合、ブラウザーのセキュリティ ポリシーの制限により、コンテンツを復元することはおろか、その中のコンテンツを表示することはまったく許可されません。 iframe 的页面来说,情况则更复杂。如果它来自其他域,那么浏览器安全策略限制根本不会允许我们查看其内部的内容,更不用说还原了。
因此可以看出,DOM 不仅仅有状态,它还包含隐藏的、无法触达的状态。
既然还原状态行不通,那就换一种方式绕过去。
对于没有改变的 DOM 节点,让它保持原样不动,仅仅创建并替换变更过的 DOM 节点。
这种方式实现了 DOM 节点复用(Reuse)。
至此,只要能够识别出哪些节点改变了,那么就可以实现对 DOM 的更新。于是问题就转化为如何比对两个 DOM 的差异。
Diff
说到对比差异,相信大家马上就能联想到版本控制(Version Control)。它的原理很简单,记录多个代码快照,然后使用 diff 算法比对前后两个快照,从而生成一系列诸如“删除 5 行”、“新增 3 行”、“替换单词”等的改动;通过把这一系列的改动应用到先前的代码快照就可以得到之后的代码快照。
而这正是 React 所需要的,只不过它的处理对象是 DOM 而不是文本文件。
难怪有人说:“I tend to think of React as Version Control for the DOM” 。
DOM 是树形结构,所以 diff 算法必须是针对树形结构的。目前已知的完整树形结构 diff 算法复杂度为 O(n^3) 。
假如页面中有 10,000 个 DOM 节点,这个数字看起来很庞大,但其实并不是不可想象。为了计算该复杂度的数量级大小,我们还假设在一个 CPU 周期我们可以完成单次对比操作(虽然不可能完成),且 CPU 主频为 1 GHz 。这种情况下,diff 要花费的时间如下:

整整有 17 分钟之长,简直无法想象!
虽然说验证阶段暂不考虑性能问题,但是我们还是可以简单了解下该算法是如何实现的。
附:完整的 Tree diff 实现算法。

新树上的每个节点与旧树上的每个节点对比
如果父节点相同,继续循环对比子树
在上图的树中,依据最小操作原则,可以找到三个嵌套的循环对比。
但如果认真思考下,其实在 Web 应用中,很少有移动一个元素到另一个地方的场景。一个例子可能的是拖拽(Drag)并放置(Drop)元素到另一个地方,但它并不常见。
唯一的常用场景是在子元素之间移动元素,例如在列表中新增、删除和移动元素。既然如此,那可以仅仅对比同层级的节点。
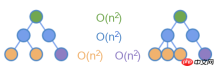
如上图所示,仅对相同颜色的节点做 diff ,这样能把时间复杂度降到了 O(n^2) 。
key

针对同级元素的比较,又引入了另一个问题。
同层级元素名称不同时,可以直接识别为不匹配;相同时,却没那么简单了。
假如在某个节点下,上一次渲染了三个 <input>,然后下一次渲染变成了两个。此时 diff 的结果会是什么呢?
最直观的结果是前面两个保持不变,删除第三个。
当然,也可以删除第一个同时保持最后两个。
如果不嫌麻烦,还可以把旧的三个都删除,然后新增两个新元素。
这说明,对于相同标签名称的节点,我们没有足够信息来对比前后差异。

如果再加上元素的属性呢?比如 value ,如果前后两次标签名称和 valueつまり、DOM には状態だけでなく隠れた到達不能な状態も含まれていることがわかります。
Diff
🎜 比較の違いといえば、 誰もがすぐにバージョン管理 (バージョン管理) を思い浮かべることができると思います。その原理は非常に簡単です。複数のコードのスナップショットを記録し、diff アルゴリズムを使用して 2 つのスナップショットを比較し、「5 行の削除」、「3 行の追加」、「単語の置換」などの一連の変更を生成します。この一連の変更を前のコード スナップショットに適用して、後続のコード スナップショットを取得します。 🎜🎜そして、これはまさに React が必要とするものですが、テキスト ファイルの代わりに DOM を処理する点が異なります。 🎜誰かが「私は React を DOM のバージョン管理 として考える傾向がある」と言うのも不思議ではありません。 🎜🎜DOM はツリー構造であるため、差分アルゴリズムはツリー構造に基づく必要があります。現在知られている完全なツリー構造 diff アルゴリズムの複雑さは O(n^3) です。 🎜🎜 ページ内に 10,000 の DOM ノードがある場合、この数は膨大に見えますが、想像できないわけではありません。この複雑さの大きさを計算するために、1 つの比較演算を 1 つの CPU サイクルで完了できる (これは不可能ですが)、CPU のクロックが 1 GHz であると仮定します。この場合、diff にかかる時間は次のとおりです: 🎜🎜 🎜🎜長さは 17 分ですが、想像を絶するものです。 🎜🎜検証フェーズでは当面パフォーマンスの問題は考慮されていませんが、アルゴリズムがどのように実装されているかを簡単に理解することはできます。 🎜
🎜🎜長さは 17 分ですが、想像を絶するものです。 🎜🎜検証フェーズでは当面パフォーマンスの問題は考慮されていませんが、アルゴリズムがどのように実装されているかを簡単に理解することはできます。 🎜添付ファイル: 完全な Tree diff 実装アルゴリズム。🎜
span>🎜- 🎜新しいツリーの各ノードと古いツリーの各ノードを比較します🎜
- 🎜親ノードが同じ場合、 continue ループ比較サブツリー🎜
🎜 🎜上の図に示すように、diff は同じ色のノードに対してのみ実行されるため、時間計算量は O(n^2) に軽減されます。 🎜キー
🎜 🎜🎜同じレベルの要素の比較に別の問題が導入されました。 🎜同じレベルの要素の名前が異なる場合は、それらが同じである場合は不一致として直接識別できますが、それほど単純ではありません。 🎜あるノードの下で、前回 3 つの
🎜🎜同じレベルの要素の比較に別の問題が導入されました。 🎜同じレベルの要素の名前が異なる場合は、それらが同じである場合は不一致として直接識別できますが、それほど単純ではありません。 🎜あるノードの下で、前回 3 つの <input> がレンダリングされ、次回は 2 つがレンダリングされたとします。このときdiffの結果はどうなるのでしょうか? 🎜🎜最も直感的な結果は、最初の 2 つを変更せずに保持し、3 つ目を削除することです。 🎜もちろん、最後の2つを残したまま最初の1つを削除することもできます。 🎜手間を気にしない場合は、3 つの古い要素をすべて削除して、2 つの新しい要素を追加できます。 🎜 これは同じラベル名を持つノードについて、 前後の違いを比較する十分な情報がないことを示しています。 🎜🎜🎜 🎜要素の属性を追加するとどうなるでしょうか?たとえば、value の場合、タグ名と value 属性が前後 2 回同じである場合、要素は一致しているとみなされ、変更する必要はありません。しかし実際には、これは機能しません。ユーザーが入力すると値が常に変化するため、要素は常に置き換えられ、フォーカスが失われます。さらに悪いことに、すべての HTML 要素がこの属性を持っているわけではありません。 。 🎜
那使用所有元素都有的 id 属性呢?这是可以的,如上图,我们可以容易的识别出前后 DOM 的差异。考虑表单情况,表单模型的输入通常跟 id 关联,但如果使用 AJAX 来提交表单的话,我们通常不会给 input 设置 id 属性。因此,更好的办法是引入一个新的属性名称,专门用来辅助 diff 算法。这个属性最终确定为 key 。这也是为什么在 React 中使用列表时会要求给子元素设置 key 属性的原因。

结合 key ,再加上哈希表,diff 算法最终实现了 O(n) 的最优复杂度。
至此,可以看到从 XHP 迁移到 JS 的方案可行的。接下来就可以针对各个环节进行逐步优化。
附:详细的 diff 理解:不可思议的 react diff 。
持续优化
Virtual DOM
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 p,其实例属性就达到 231 个。
// Chrome v63
const p = document.createElement('p');
let m = 0;
for (let k in p) {
m++;
}
console.log(m); // 231
之所以有这么多属性,是因为 DOM 节点被用于浏览器渲染管道的很多过程中。
浏览器首先根据 CSS 规则查找匹配的节点,这个过程会缓存很多元信息,例如它维护着一个对应 DOM 节点的 id 映射表。
然后,根据样式计算节点布局,这里又会缓存位置和屏幕定位信息,以及其他很多的元信息,浏览器会尽量避免重新计算布局,所以这些数据都会被缓存。
可以看出,整个渲染过程会耗费大量的内存和 CPU 资源。
现在回过头来想想 React ,其实它只在 diff 算法中用到了 DOM 节点,而且只用到了标签名称和部分属性。
如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这种方式称为 Virtual DOM 。

其过程如下:
维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
把变更应用于真实 DOM,生成最新的真实 DOM
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
至此,React 的两大优化:diff 算法和 Virtual DOM ,均已完成。再加上 XHP 时代尝试的数据绑定,已经算是一个可用版本了。
这个时候 Facebook 做了个重大的决定,那就是把 React 开源!
React 的开源可谓是一石激起千层浪,社区开发者都被这种全新的 Web 开发方式所吸引,React 因此迅速占领了 JS 开源库的榜首。
很多大公司也把 React 应用到生产环境,同时也有大批社区开发者为 React 贡献了代码。
接下来要说的两大优化就是来自于开源社区。
批处理(Batching)
著名浏览器厂商 Opera 把重排和重绘(Reflow and Repaint)列为影响页面性能的三大原因之一。
我们说 DOM 是很慢的,除了前面说到的它的复杂和庞大,还有另一个原因就是重排和重绘。
当 DOM 被修改后,浏览器必须更新元素的位置和真实像素;
当尝试从 DOM 读取属性时,为了保证读取的值是正确的,浏览器也会触发重排和重绘。
因此,反复的“读取、修改、读取、修改...”操作,将会触发大量的重排和重绘。
另外,由于浏览器本身对 DOM 操作进行了优化,比如把两次很近的“修改”操作合并成一个“修改”操作。
所以如果把“读取、修改、读取、修改...”重新排列为“读取、读取...”和“修改、修改...”,会有助于减小重排和重绘的次数。但是这种刻意的、手动的级联写法是不安全的。
与此同时,常规的 JS 写法又很容易触发重排和重绘。
在减小重排和重绘的道路上,React 陷入了尴尬的处境。
最終的に、コミュニティ貢献者の Ben Alpert は、バッチ処理を使用して、この恥ずかしい状況を救いました。
React では、開発者はコンポーネントの setState メソッドを呼び出すことで、現在のコンポーネントが変更されることを React に伝えます。 setState 方法告诉 React 当前组件要变更了。

Ben Alpert 的做法是,调用 setState 时不立即把变更同步到 Virtual DOM,而是仅仅把对应元素打上“待更新”的标记。如果组件内调用多次 setState ,那么都会进行相同的打标操作。
等到初始化事件被完全广播开以后,就开始进行从顶部到底部的重新渲染(Re-Render)过程。这就确保了 React 只对元素进行了一次渲染。
这里要注意两点:
此处的重新渲染是指把
setState变更同步到 Virtual DOM ;在这之后才进行 diff 操作生成真实的 DOM 变更。与前文提到的“重新渲染整个 DOM ”不同的是,真实的重新渲染仅渲染被标记的元素及其子元素,也就是说上图中仅蓝色圆圈代表的元素会被重新渲染
这也提醒开发者,应该让拥有状态的组件尽量靠近叶子节点,这样可以缩小重新渲染的范围。
裁剪(Pruning)
随着应用越来越大,React 管理的组件状态也会越来越多,这就意味着重新渲染的范围也会越来越大。
认真观察上面批处理的过程可以发现,该 Virtual DOM 右下角的三个元素其实是没有变更的,但是因为其父节点的变更也导致了它们的重新渲染,多做了无用操作。

对于这种情况,React 本身已经考虑到了,为此它提供了 bool shouldComponentUpdate(nextProps, nextState) 接口。开发者可以手动实现该接口来对比前后状态和属性,以判断是否需要重新渲染。这样的话,重新渲染就变成如下图所示过程。

当时,React 虽然提供了 shouldComponentUpdate 接口,但是并没有提供一个默认的实现方案(总是渲染),开发者必须自己手动实现才能达到预期效果。
其原因是,在 JS 中,我们通常使用对象来保存状态,修改状态时是直接修改该状态对象的。也就是说,修改前后的两个不同状态指向了同一个对象,所以当直接比较两个对象是否变更时,它们是相同的,即使状态已经改变。
对此,David Nolen 提出了基于不可变数据结构(Immutable Data Structure)的解决方案。
该方案的灵感来自于 ClojureScript ,在 ClojureScript 中,大部分的值都是不可变的。换句话说就是,当需要更新一个值时,程序不是去修改原来的值,而是基于原来的值创建一个新值,然后使用新值进行赋值。
David 使用 ClojureScript 写了一个针对 React 的不可变数据结构方案:Om ,为 shouldComponentUpdate 提供了默认实现。
不过,由于不可变数据结构并未被 Web 工程师广为接受,所以当时并未把这项功能合并进 React 。
遗憾的是,截止到目前,shouldComponentUpdate
Ben Alpert のアプローチは、setState を呼び出したときに変更を仮想 DOM に即座に同期させるのではなく、対応する要素を「更新予定」としてマークするだけです。 setState がコンポーネント内で複数回呼び出された場合、同じマーキング操作が実行されます。
初期化イベントが完全にブロードキャストされるまで待ってから、上から下まで再レンダリング プロセスを開始します。これにより、React が要素を 1 回だけレンダリングすることが保証されます。
ここで注意すべき 2 つの点:
- ここでの再レンダリングとは、この後に
setStateの変更を仮想 DOM に同期することを指します。その後のみ実行します。実際の DOM 変更を生成するための diff 操作。 -
上記の「DOM 全体の再レンダリング」とは異なり、実際の再レンダリングでは、マークされた要素とそのサブ要素のみがレンダリングされます。つまり、上の図の青い円のみが表現されます。要素は再レンダリングされます
これにより、開発者は、ステートフル コンポーネントをリーフ ノードのできるだけ近くに保持する必要があることを思い出させます。そうすることで、再レンダリングの範囲を減らすことができます。
プルーニング
アプリケーションが大きくなるにつれて、React はより多くのコンポーネントの状態を管理します。これは、再レンダリングの範囲もますます大きくなることを意味します。 上記のバッチ処理プロセスを注意深く観察すると、仮想 DOM の右下隅にある 3 つの要素が実際には変更されていないことがわかります。ただし、それらの親ノードの変更により再レンダリングも行われています。その結果、さらに無駄な操作が発生します。
React 自体はこの状況をすでに考慮しており、この目的のために bool shouldComponentUpdate(nextProps, nextState) インターフェースを提供しています。開発者は、このインターフェイスを手動で実装して、前後のステータスとプロパティを比較して、再レンダリングが必要かどうかを判断できます。この場合、再レンダリングは下図のような処理となります。
shouldComponentUpdate インターフェースを提供していましたが、デフォルトの実装ソリューション (常にレンダリング) を提供しておらず、望ましい効果を達成するには開発者が手動で実装する必要がありました。 🎜🎜その理由は、JS では通常、状態を保存するためにオブジェクトを使用し、状態を変更する場合は状態オブジェクトを直接変更するためです。つまり、変更前後の 2 つの異なる状態は同じオブジェクトを指しているため、2 つのオブジェクトが変更されたかどうかを直接比較すると、状態が変更されたとしても、それらは同じになります。 🎜🎜これに応えて、David Nolen は不変データ構造に基づくソリューションを提案しました。 🎜このソリューションは、ほとんどの値が不変である ClojureScript からインスピレーションを得ています。つまり、値を更新する必要がある場合、プログラムは元の値を変更せず、元の値に基づいて新しい値を作成し、その新しい値を代入に使用します。 🎜🎜David は ClojureScript を使用して React: Om 用の不変データ構造ソリューションを作成しました。これは shouldComponentUpdate のデフォルト実装を提供します。 🎜🎜ただし、不変のデータ構造は Web エンジニアに広く受け入れられていなかったため、この機能は当時 React には組み込まれませんでした。 🎜残念ながら、現時点では shouldComponentUpdate はまだデフォルトの実装を提供していません。 🎜しかし、David は開発者に優れた研究の方向性を切り開いてくれました。 🎜🎜本当に不変のデータ構造を使用して React のパフォーマンスを向上させたい場合は、React と同じ流派の Facebook Immutable.js を参照してください。これは React の良きパートナーです。 🎜🎜結論🎜🎜 React の最適化は現在も続いています。たとえば、Fiber は React 16 で新たに導入されました。これは、コア アルゴリズムの再構築であり、変更を検出する方法とタイミングを再設計し、レンダリング プロセスを可能にします。分割して完了する必要があり、一度にすべて完了する必要はありません。 🎜スペースの都合上、この記事では Fiber について詳しくは紹介しません。興味のある方は、「React Fiber とは」を参照してください。 🎜🎜関連する推奨事項: 🎜🎜🎜🎜 React コンポーネントのライフサイクルの詳細な説明🎜🎜🎜🎜 React の制御コンポーネントと非制御コンポーネントの詳細な説明🎜🎜🎜🎜 React を使用したページング コンポーネントの作成例🎜🎜🎜🎜🎜以上がReact の簡単な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM
ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM現実世界におけるJavaScriptのアプリケーションには、サーバー側のプログラミング、モバイルアプリケーション開発、モノのインターネット制御が含まれます。 2。モバイルアプリケーションの開発は、ReactNativeを通じて実行され、クロスプラットフォームの展開をサポートします。 3.ハードウェアの相互作用に適したJohnny-Fiveライブラリを介したIoTデバイス制御に使用されます。
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM私はあなたの日常的な技術ツールを使用して機能的なマルチテナントSaaSアプリケーション(EDTECHアプリ)を作成しましたが、あなたは同じことをすることができます。 まず、マルチテナントSaaSアプリケーションとは何ですか? マルチテナントSaaSアプリケーションを使用すると、Singの複数の顧客にサービスを提供できます
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AMこの記事では、許可によって保護されたバックエンドとのフロントエンド統合を示し、next.jsを使用して機能的なedtech SaaSアプリケーションを構築します。 FrontEndはユーザーのアクセス許可を取得してUIの可視性を制御し、APIリクエストがロールベースに付着することを保証します
 JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AM
JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AMJavaScriptは、現代のWeb開発のコア言語であり、その多様性と柔軟性に広く使用されています。 1)フロントエンド開発:DOM操作と最新のフレームワーク(React、Vue.JS、Angularなど)を通じて、動的なWebページとシングルページアプリケーションを構築します。 2)サーバー側の開発:node.jsは、非ブロッキングI/Oモデルを使用して、高い並行性とリアルタイムアプリケーションを処理します。 3)モバイルおよびデスクトップアプリケーション開発:クロスプラットフォーム開発は、反応および電子を通じて実現され、開発効率を向上させます。
 JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AM
JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AMJavaScriptの最新トレンドには、TypeScriptの台頭、最新のフレームワークとライブラリの人気、WebAssemblyの適用が含まれます。将来の見通しは、より強力なタイプシステム、サーバー側のJavaScriptの開発、人工知能と機械学習の拡大、およびIoTおよびEDGEコンピューティングの可能性をカバーしています。
 javascriptの分解:それが何をするのか、なぜそれが重要なのかApr 09, 2025 am 12:07 AM
javascriptの分解:それが何をするのか、なぜそれが重要なのかApr 09, 2025 am 12:07 AMJavaScriptは現代のWeb開発の基礎であり、その主な機能には、イベント駆動型のプログラミング、動的コンテンツ生成、非同期プログラミングが含まれます。 1)イベント駆動型プログラミングにより、Webページはユーザー操作に応じて動的に変更できます。 2)動的コンテンツ生成により、条件に応じてページコンテンツを調整できます。 3)非同期プログラミングにより、ユーザーインターフェイスがブロックされないようにします。 JavaScriptは、Webインタラクション、シングルページアプリケーション、サーバー側の開発で広く使用されており、ユーザーエクスペリエンスとクロスプラットフォーム開発の柔軟性を大幅に改善しています。
 pythonまたはjavascriptの方がいいですか?Apr 06, 2025 am 12:14 AM
pythonまたはjavascriptの方がいいですか?Apr 06, 2025 am 12:14 AMPythonはデータサイエンスや機械学習により適していますが、JavaScriptはフロントエンドとフルスタックの開発により適しています。 1. Pythonは、簡潔な構文とリッチライブラリエコシステムで知られており、データ分析とWeb開発に適しています。 2。JavaScriptは、フロントエンド開発の中核です。 node.jsはサーバー側のプログラミングをサポートしており、フルスタック開発に適しています。
 JavaScriptをインストールするにはどうすればよいですか?Apr 05, 2025 am 12:16 AM
JavaScriptをインストールするにはどうすればよいですか?Apr 05, 2025 am 12:16 AMJavaScriptは、最新のブラウザにすでに組み込まれているため、インストールを必要としません。開始するには、テキストエディターとブラウザのみが必要です。 1)ブラウザ環境では、タグを介してHTMLファイルを埋め込んで実行します。 2)node.js環境では、node.jsをダウンロードしてインストールした後、コマンドラインを介してJavaScriptファイルを実行します。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

