
ホームページ >バックエンド開発 >PHPチュートリアル >HTTP のさまざまなバージョンの主な機能と相違点の分析
HTTP のさまざまなバージョンの主な機能と相違点の分析

- 小云云オリジナル
- 2018-01-29 11:01:541918ブラウズ
HTTP には多くのバージョンがあり、各バージョンには独自の違いがあります。この記事は、HTTP のさまざまなバージョンの主な機能の概要と概要です。 HTTP不同版本主要特性的一个概述和总结,希望能帮助到大家。
HTTP1.0
早先1.0的HTTP版本,是一种无状态、无连接的应用层协议。
HTTP1.0规定浏览器和服务器保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。
这种无状态性可以借助cookie/session机制来做身份认证和状态记录。而下面两个问题就比较麻烦了。
首先,无连接的特性导致最大的性能缺陷就是无法复用连接。每次发送请求的时候,都需要进行一次TCP的连接,而TCP的连接释放过程又是比较费事的。这种无连接的特性会使得网络的利用率非常低。
其次就是就是队头阻塞(head of line blocking)。由于HTTP1.0规定下一个请求必须在前一个请求响应到达之前才能发送。假设前一个请求响应一直不到达,那么下一个请求就不发送,同样的后面的请求也给阻塞了。
为了解决这些问题,HTTP1.1出现了。
HTTP1.1
对于HTTP1.1,不仅继承了HTTP1.0简单的特点,还克服了诸多HTTP1.0性能上的问题。
首先是长连接,HTTP1.1增加了一个Connection字段,通过设置Keep-Alive可以保持HTTP连接不断开,避免了每次客户端与服务器请求都要重复建立释放建立TCP连接,提高了网络的利用率。如果客户端想关闭HTTP连接,可以在请求头中携带Connection: false来告知服务器关闭请求。
其次,是HTTP1.1支持请求管道化(pipelining)。基于HTTP1.1的长连接,使得请求管线化成为可能。管线化使得请求能够并行传输。举个例子来说,假如响应的主体是一个html页面,页面中包含了很多img,这个时候keep-alive就起了很大的作用,能够进行并行发送多个请求。(客户端依据域名来向服务器建立连接,一般PC浏览器会针对单个域名的服务器同时建立6~8个连接,手机端一般控制在4~6个。这也是为什么很多大型网站设置不同的静态资源CDN域名来加载资源。)
需要注意的是,服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。
也就是说,HTTP管道化可以让我们把先进先出队列从客户端(请求队列)迁移到服务端(响应队列)。
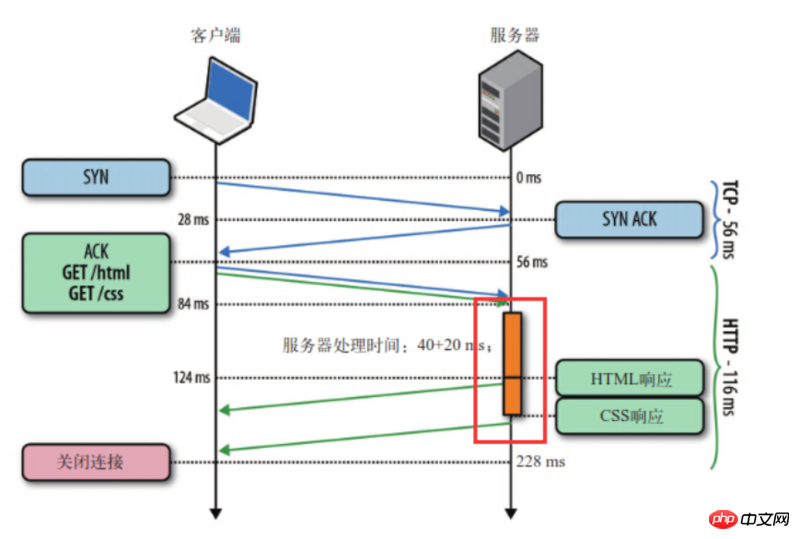
如图所示,客户端同时发了两个请求分别来获取html和css,假如说服务器的css资源先准备就绪,服务器也会先发送html再发送css。
同时,管道化技术只是使得客户端能够往一个服务器同时发送一组请求,假若客户端想往这个相同的服务器发起另一组请求,也必须等待上一组请求全部响应完毕。
可见,HTTP1.1解决队头阻塞(head of line blocking)还不彻底。同时“管道化”技术存在各种各样的问题,所以很多浏览器要么根本不支持它,要么就直接默认关闭,并且开启的条件很苛刻...
此外,HTTP1.1还加入了缓存处理(强缓存和协商缓存[传送门]),支持断点传输,以及增加了Host字段(使得一个服务器能够用来创建多个Web站点)。
HTTP2.0
HTTP2.0的新特性大致如下:
二进制分帧
HTTP2.0通过在应用层和传输层之间增加一个二进制分帧层,突破了HTTP1.1
HTTP1.0
1.0 の以前の HTTP バージョンは、ステートレス、コネクションレスのアプリケーション層プロトコルです。 HTTP1.0 では、ブラウザとサーバーが短期間の接続を維持するために、サーバーとの TCP 接続を確立する必要があると規定されています。 TCP 接続を開くと (接続なし)、サーバーは各クライアントを追跡せず、過去のリクエストを記録しません (ステートレス)。 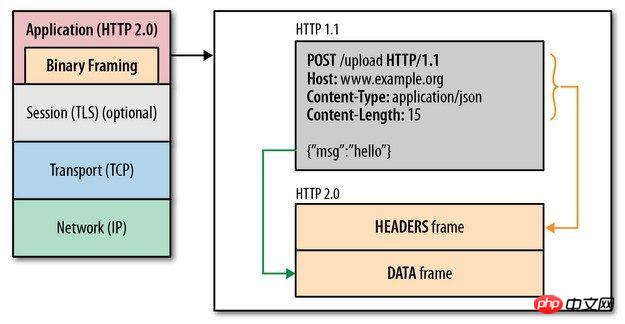 このステートレス性では、ID 認証とステータス記録に
このステートレス性では、ID 認証とステータス記録に cookie/session メカニズムを使用できます。次の 2 つの質問はさらに厄介です。
TCP 接続が必要となり、TCP 接続の解放処理が非常に面倒です。このコネクションレス機能により、ネットワーク使用率が非常に低くなります。 🎜🎜 2 つ目は行頭ブロック (行頭ブロック) です。 HTTP1.0 では、前のリクエストに対する応答が到着する前に次のリクエストを送信する必要があると規定されているためです。前のリクエストに対する応答が到着しないと仮定すると、次のリクエストは送信されず、後続の同じリクエストもブロックされます。 🎜🎜これらの問題を解決するために、HTTP1.1 が登場しました。 🎜HTTP1.1
🎜HTTP1.1 の場合、HTTP1.0 の単純な機能を継承するだけでなく、多くの を克服します。 HTTP1。0パフォーマンスの問題。 🎜🎜 1 つ目は長い接続です。HTTP1.1 は Connection フィールドを追加します。これは Keep-Alive <code>HTTP 接続が切断されないようにすることで、クライアントとサーバーがリクエストするたびに TCP 接続の確立、解放、確立を繰り返す必要がなくなり、ネットワークの使用率が向上します。クライアントが HTTP 接続を閉じたい場合は、リクエスト ヘッダーに Connection: false を含めて、サーバーにリクエストを閉じるように指示できます。 🎜🎜 次に、HTTP1.1 はリクエストのパイプライン (パイプライン) をサポートします。 HTTP1.1 に基づく長い接続により、リクエスト パイプラインが可能になります。パイプライン化により、リクエストを並行して送信できます。たとえば、応答の本文が html ページで、そのページに多くの img が含まれている場合、keep-alive はstart これは大きな役割を果たし、複数のリクエストを並行して送信できます。 (クライアントはドメイン名に基づいてサーバーへの接続を確立します。通常、PC ブラウザは単一のドメイン名のサーバーに対して 6 ~ 8 個の接続を同時に確立します。モバイル端末は通常、これが、多くの大規模な Web サイトがリソースをロードするために異なる静的リソース CDN ドメイン名を設定する理由です)🎜🎜 サーバーは対応する結果を順番に返信する必要があることに注意してください。クライアントが各リクエストの応答内容を確実に区別できるようにするため。 🎜🎜言い換えると、HTTP パイプラインを使用すると、先入れ先出しキューをクライアント (要求キュー) からサーバー (応答キュー) に移行できます。 🎜🎜🎜🎜🎜🎜図に示すように、クライアントは 2 つのメッセージを送信しました同時に html と css を取得するために 2 つのリクエストが行われます。サーバーの css リソースが最初に準備できている場合、サーバーも送信します。 html <code>css を再度送信します。 🎜🎜 同時に、パイプライン テクノロジーでは、クライアントが同時に一連のリクエストをサーバーに送信することしかできません。クライアントが同じサーバーに別のリクエスト セットを開始したい場合も、待機する必要があります。応答する前の一連のリクエスト。 🎜🎜HTTP1.1 は行頭ブロック (行頭ブロック) を完全には解決していないことがわかります。同時に、「パイプライン」テクノロジーにはさまざまな問題があるため、多くのブラウザーはそれをまったくサポートしていないか、単にデフォルトでオフになっており、オンにするための条件は非常に厳しいです...🎜🎜さらに、 HTTP1.1 ではキャッシュ処理 (強力なキャッシュとネゴシエーション キャッシュ [ポータル]) も追加され、ブレークポイント送信をサポートし、 > ホスト フィールド > (1 つのサーバーを使用して複数の Web サイトを作成できるようにします)。 🎜HTTP2.0
🎜HTTP2.0 の新機能はおおよそ次のとおりです: 🎜🎜バイナリ フレーミング🎜🎜HTTP2.0 code>アプリケーション層とトランスポート層の間にバイナリ フレーミング層を追加することで、<code>HTTP1.1 のパフォーマンス制限を突破し、送信パフォーマンスを向上させます。 🎜🎜🎜🎜🎜🎜 HTTP2.0 プロトコルと HTTP1.x プロトコルの仕様は完全に異なりますが、実際には HTTP2.0 であることがわかります。 > は変更されません HTTP1.x のセマンティクスは変更されません。 HTTP2.0的协议和HTTP1.x协议之间的规范完全不同了,但是实际上HTTP2.0并没有改变HTTP1.x的语义。
简单来说,HTTP2.0只是把原来HTTP1.x的header和body部分用frame重新封装了一层而已。
多路复用(连接共享)
下面是几个概念:
流(
stream):已建立连接上的双向字节流。消息:与逻辑消息对应的完整的一系列数据帧。
帧(
frame):HTTP2.0通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流(stream id)。
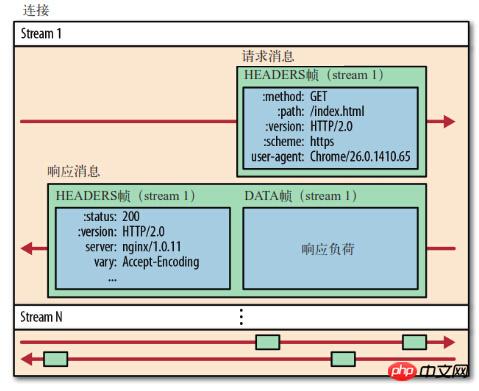
从图中可见,所有的HTTP2.0通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。
每个数据流以消息的形式发送,而消息由一或多个帧组成。这些帧可以乱序发送,然后再根据每个帧首部的流标识符(stream id)重新组装。
举个例子,每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧首部记录着stream id用来标识所属的数据流,不同属的帧可以在连接中随机混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求当中去。
另外,多路复用(连接共享)可能会导致关键请求被阻塞。HTTP2.0里每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回给客户端,数据流还可以依赖其他的子数据流。
首部压缩
在HTTP1.x中,首部元数据都是以纯文本的形式发送的,通常会给每个请求增加500~800字节的负荷。
比如说cookie,默认情况下,浏览器会在每次请求的时候,把cookie附在header上面发送给服务器。(由于cookie比较大且每次都重复发送,一般不存储信息,只是用来做状态记录和身份认证)
HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。
服务器推送
服务器除了对最初请求的响应外,服务器还可以额外的向客户端推送资源,而无需客户端明确的请求。
总结
HTTP1.0
无状态、无连接
HTTP1.1
持久连接
请求管道化
增加缓存处理
增加
Host簡単に言うと、HTTP2.0は、元のHTTP1.xのheaderとbodyの部分を置き換えるだけです。frameは再カプセル化されるだけです。
ここにいくつかの概念があります:
ストリーム (
stream): 確立された接続上のバイトの双方向ストリーム。メッセージ: 論理メッセージに対応する一連の完全なデータ フレーム。
フレーム (
frame):HTTP2.0通信の最小単位。各フレームには、少なくとも現在のフレームの送信先ストリームを識別するフレーム ヘッダーが含まれます。 (ストリーム ID
HTTP2.0 通信は接続上で完了し、任意の数の双方向データ ストリームを伝送できます。 各データ ストリームはメッセージの形式で送信され、メッセージは 1 つ以上のフレームで構成されます。これらのフレームは、順不同で送信し、各フレームのヘッダー内のストリーム識別子 (stream id) に基づいて再組み立てすることができます。
stream id が記録されます。ストリーミングでは、接続中に異なる送信元のフレームがランダムに混在する可能性があります。受信者は、stream id に基づいて、フレームをさまざまなリクエストに再帰属させることができます。
HTTP1.x では、ヘッダーのメタデータはプレーン テキストの形式で送信され、通常、各リクエストに 500 ~ 800 バイトの負荷が追加されます。
HTTP2.0 は、 エンコーダ は、送信する必要がある header のサイズを削減します。各通信パーティの cache には、headerfields テーブルがあります。これにより、 の重複が回避されます。>header の送信により、送信する必要のあるサイズも削減されます。効率的な圧縮アルゴリズムにより、header が大幅に圧縮され、送信されるパケット数が減り、レイテンシが短縮されます。 🎜🎜🎜サーバープッシュ🎜🎜🎜 最初のリクエストに対するサーバーの応答に加えて、サーバーは、クライアントからの明示的なリクエストなしで追加のリソースをクライアントにプッシュすることもできます。 🎜概要
🎜🎜HTTP1.0🎜🎜🎜🎜🎜ステートレス、コネクションレス🎜🎜🎜🎜🎜HTTP1.1🎜🎜🎜🎜🎜永続的な接続🎜🎜🎜🎜リクエストパイプライン🎜 🎜🎜🎜 キャッシュ処理を追加🎜🎜🎜🎜Host フィールドを追加し、ブレークポイント送信などをサポート🎜🎜🎜🎜🎜HTTP2.0🎜🎜🎜🎜🎜バイナリフレーミング🎜🎜🎜🎜多重化(または接続)共有)🎜🎜 🎜 🎜ヘッダー圧縮🎜🎜🎜🎜サーバープッシュ🎜🎜🎜🎜関連する推奨事項:🎜🎜🎜🎜HTTP/2サーバープッシュについて🎜🎜🎜🎜PHPはHTTP認証を実装します🎜🎜🎜 🎜httpをシミュレートするためのPHP実装の分析例🎜🎜🎜🎜 🎜 🎜以上がHTTP のさまざまなバージョンの主な機能と相違点の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。