
ホームページ >バックエンド開発 >PHPチュートリアル >PHP はテキストベースのモールス信号を生成します
PHP はテキストベースのモールス信号を生成します

- *文オリジナル
- 2017-12-28 15:29:322205ブラウズ
最近、入力テキストに基づいてモールス信号オーディオ ファイルを生成する必要性が生じました。いくつかの無駄な検索の後、私は独自のジェネレーターを作成することにしました。この記事では主に、PHP でのテキストベースのモールス信号ジェネレーターの実装に関する関連情報を紹介します。必要な方は参考にしてください。お役に立てれば幸いです。
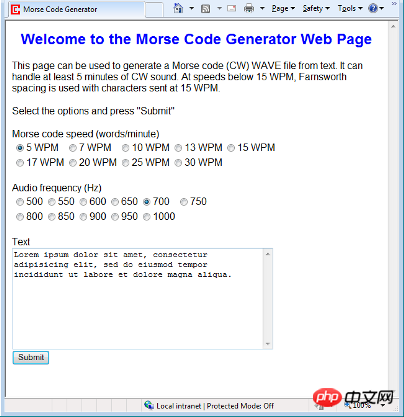
Web 経由でモールス信号の音声ファイルにアクセスしたいため、メインのプログラミング言語として PHP を使用することにしました。上のスクリーンショットは、モールス信号の生成を開始する Web ページを示しています。ダウンロードした zip ファイルには、テキストを送信するための Web ページと、音声ファイルを生成および表示するための PHP ソース ファイルが含まれています。 PHP コードをテストする場合は、Web ページと関連する PHP ファイルを PHP 対応サーバーにコピーする必要があります。
多くの人にとって、モールス信号は、古い映画のように、単なる「点」と「破線」の連続、または一連のビープ音にすぎません。コンピューター コードを使用してモールス信号を生成する場合、この知識だけでは明らかに不十分です。この記事では、モールス信号を生成する要素、WAVE 形式の音声ファイルを生成する方法、および PHP を使用してモールス信号を音声ファイルに変換する方法を紹介します。
モールス信号
モールス信号は、テキストの符号化方式です。その利点は、エンコードが簡単で、人間の耳で簡単にデコードできることです。基本的に、オーディオ (または無線周波数) はオンまたはオフになり、一般にドットとダッシュ、またはラジオ用語で「ディット」と「ダッシュ」と呼ばれる、短いまたは長いオーディオ パルスを形成します。現代のデジタル通信用語では、モールス符号は振幅シフト キーイング (ASK) の一種です。
モールス信号では、文字 (文字、数字、句読点、特殊記号) が一連の「ティック」と「ダ」にエンコードされます。したがって、テキストをモールス信号に変換するには、まず「カチカチ」と「ダ」をどのように表現するかを決定する必要があります。明らかな選択は、「ティック」に 0 を使用し、「ダー」に 1 を使用するか、その逆を使用することです。残念なことに、モールス信号は可変長符号化方式を使用しています。したがって、可変長シーケンスを使用するか、コンピューターのメモリに一般的な固定ビットサイズ形式にデータをパックする方法も採用する必要があります。さらに、モールス信号は大文字と小文字を区別せず、一部の特殊記号をエンコードできないことに注意することが重要です。私たちの実装では、未定義の文字と記号は無視されます。
このプロジェクトでは、メモリ使用量は特別な考慮が必要な問題ではありません。したがって、単純なエンコード方式を提案します。つまり、各「ティック」を表すために「0」を使用し、各「ダ」を表すために「1」を使用し、それらを文字列連想配列に置きます。モールス信号エンコーディング テーブルを定義する PHP コードは次のようになります。
$CWCODE = array ('A'=>'01','B'=>'1000','C'=>'1010','D'=>'100','E'=>'0', 'F'=>'0010','G'=>'110','H'=>'0000','I'=>'00','J'=>'0111', 'K'=>'101','L'=>'0100','M'=>'11','N'=>'10', 'O'=>'111', 'P'=>'0110','Q'=>'1101','R'=>'010','S'=>'000','T'=>'1', 'U'=>'001','V'=>'0001','W'=>'011','X'=>'1001','Y'=>'1011', 'Z'=>'1100', '0'=>'11111','1'=>'01111','2'=>'00111', '3'=>'00011','4'=>'00001','5'=>'00000','6'=>'10000', '7'=>'11000','8'=>'11100','9'=>'11110','.'=>'010101', ','=>'110011','/'=>'10010','-'=>'10001','~'=>'01010', '?'=>'001100','@'=>'00101');
メモリ使用量を特に気にする場合は、上記のコードはビットとして解釈できることに注意してください。各コードにスタートビットを追加することでビットパターンを形成し、各文字を 1 バイトに格納できます。同時に、最終的なエンコーディングを解析するときに、開始ビットの左側のビットが削除され、真の可変長エンコーディングが得られます。
多くの人は気づいていませんが、実際には「時間間隔」がモールス信号を定義する主な要素であるため、これを理解することがモールス信号を生成する鍵となります。したがって、最初に行う必要があるのは、モールス信号の内部符号 (つまり、「チック」と「ダ」) の時間間隔を定義することです。便宜上、「カチカチ」の音の長さを時間単位 dt として定義し、「カチカチ」と「ダ」の間の間隔も時間単位 dt として「ダ」の長さを 3 と定義します。 dt、文字(文字間の間隔)も 3 dt、定義語(単語)間の間隔は 7 dt です。要約すると、時間間隔テーブルは次のようになります:

モールス信号では、エンコードされたサウンドの「再生速度」は通常、1 分あたりの単語数 (WPM) で表されます。英語の単語の長さは異なり、文字のクリック数やクリック数も異なるため、WPM から (オーディオ) デジタル サンプルへの変換は、思っているほど簡単ではありません。国際機関で採用されている方式では、平均語長として 5 文字が使用され、数字や句読点は 2 文字として扱われます。このように、平均ワードは 50 時間単位 dt になります。このように、WPM を指定すると、合計再生時間は 50 * WPM 時間単位/分となり、各「ティック」の長さ (つまり、1 時間単位 dt) は 1.2/WPM 秒に等しくなります。このように、「ティック」の時間長が与えられれば、他の要素の時間長も簡単に計算できます。
你可能已经注意到,在上面显示的网页中,对于低于15WPM的选项,我们使用了“Farnsworth spacing”。那么这个“Farnsworth spacing”又是个什么鬼?
当报务员学习用耳朵来解码莫斯代码的时候,他就会意识到,当播放速度变化的时候,字符出现的节奏也会跟着变化。当播放速度低于10WPM的时候,他能够从容的识别“嘀”和“嗒”,并且知道发送的哪个字符。但是当播放速度超过10WPM的时候,报务员的识别就会出错,他识别出来的字符会多于实际的“嘀”和“嗒”。当一个学习的时候习惯低速莫斯代码的人,在处理高速播放代码的时候,就会出现问题。因为节奏变了,他潜意识的识别就会出错。
为了解决这个问题,“Farnsworth spacing”就被发明出来了。本质上来讲,字母和符号的播放速度依然采取高于15WPM的速度,同时,通过在字符之间插入更多的空格,来使整体的播放速度降低。这样,报务员就能够以一个合理的速度和节奏来识别每个字符,一旦所有的字符都学习完毕,就可以增加速度,而接收员只需要加快识别字符的速度就可以了。本质上来说,“Farnsworth spacing”这个技巧解决了节奏变化这个问题,使接收员能够快速学习。
所以,在整个系统中,对于更低的播放速度,都统一成15WPM。相对应的,一个“嘀”的长度是0.08秒,但是字符之间和单词之间的间隔就不再是3个dit或者7个dit,而是进行的调整以适应整体速度。
生成声音
在PHP代码中,一个字符(即前面数组的索引)代表一组由“嘀”、“嗒”和空白间隔组成的莫斯声音。我们用数字采样来组成音频序列,并且将其写入到文件中,同时加上适当的头信息来将其定义成WAVE格式。
生成声音的代码其实相当简单,你可以在项目中PHP文件中找到它们。我发现定义一个“数字振荡器”相当方便。每调用一次osc(),它就会返回一个从正玄波产生的定时采样。运用声音采样和声频规范,生成WAVE格式的音频已经足够了。在产生的正玄波中的-1到+1之间是被移动和调整过的,这样声音的字节数据可以用0到255来表示,同时128表示零振幅。
同时,在生成声音方面我们还要考虑另外一个问题。一般来讲,我们是通过正玄波的开关来生成莫斯代码。但是你直接这样来做的话,就会发现你生成的信号会占用非常大的带宽。所以,通常无线电设备会对其加以修正,以减少带宽占用。
在我们的项目中,也会做这样的修正,只不过是用数字的方式。既然我们已经知道了一个最小声音样本“嘀”的时间长度,那么,可以证明,最小带宽的声幅发生在长度等于“嘀”的正玄波半周期。事实上,我们使用低通滤波器(low pass filter)来过滤音频信号也能达到同样的效果。不过,既然我们已经知道所有的信号字符,我们直接简单的过滤一下每一个字符信号就可以了。
生成“嘀”、“嗒”和空白信号的PHP代码就像下面这样:
while ($dt < $DitTime) {
$x = Osc();
if ($dt < (0.5*$DitTime)) {
// Generate the rising part of a dit and dah up to half the dit-time
$x = $x*sin((M_PI/2.0)*$dt/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
else if ($dt > (0.5*$DitTime)) {
// For a dah, the second part of the dit-time is constant amplitude
$dahstr .= chr(floor(120*$x+128));
// For a dit, the second half decays with a sine shape
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
}
else {
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
// a space has an amplitude of 0 shifted to 128
$spcstr .= chr(128);
$dt += $sampleDT;
}
// At this point the dit sound has been generated
// For another dit-time unit the dah sound has a constant amplitude
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
$dahstr .= chr(floor(120*$x+128));
$dt += $sampleDT;
}
// Finally during the 3rd dit-time, the dah sound must be completed
// and decay during the final half dit-time
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
if ($dt > (0.5*$DitTime)) {
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$dahstr .= chr(floor(120*$x+128));
}
else {
$dahstr .= chr(floor(120*$x+128));
}
$dt += $sampleDT;
}WAVE格式的文件
WAVE是一种通用的音频格式。从最简单的形式来看,WAVE文件通过在头部包含一个整数序列来表示指定采样率的音频振幅。关于WAVE文件的详细信息请查看这里Audio File Format Specifications website。对于产生莫斯代码,我们并不需要用到WAVE格式的所有参数选项,仅仅需要一个8位的单声道就可以了,所以,so easy。需要注意的是,多字节数据需要采用低位优先(little-endian)的字节顺序。WAVE文件使用一种由叫做“块(chunks)”的记录组成的RIFF格式。
WAVE文件由一个ASCII标识符RIFF开始,紧跟着一个4字节的“块”,然后是一个包含ASCII字符WAVE的头信息,最后是定义格式的数据和声音数据。
在我们的程序中,第一个“块”包含了一个格式说明符,它由ASCII字符fmt和一个4倍字节的“块”。在这里,由于我使用的是普通脉冲编码调制(plain vanilla PCM)格式,所以每个“块”都是16字节。然后,我们还需要这些数据:声道数、声音采样/秒、平均字节/秒、一个区块(block)对齐指示器、位(bit)/声音采样。另外,由于我们不需要高质量立体声,我们只采用单声道,我们使用 11050采样/秒(标准的CD质量音频的采样率是 44200采样/秒)的采样率来生成声音,并且用8位(bit)保存。
最后,真实的音频数据储存在接下来的“块”中。其中包含ASCII字符data,一个4字节的“块”,最后是由字节序列(因为我们采用的是8位(bit)/采样)组成的真实音频数据。
在程序中,由8位音频振幅序列组成的声音保存在变量$soundstr中。一旦音频数据生成完毕,就可以计算出所有的“块”大小,然后就可以把它们合并在一起写入磁盘文件中。下面的代码展示了如何生成头信息和音频“块”。需要注意的是,$riffstr表示RIFF头,$fmtstr表示“块”格式,$soundstr表示音频数据“块”。
$riffstr = 'RIFF'.$NSizeStr.'WAVE';
$x = SAMPLERATE;
$SampRateStr = '';
for ($i=0; $i<4; $i++) {
$SampRateStr .= chr($x % 256);
$x = floor($x/256);
}
$fmtstr = 'fmt '.chr(16).chr(0).chr(0).chr(0).chr(1).chr(0).chr(1).chr(0)
.$SampRateStr.$SampRateStr.chr(1).chr(0).chr(8).chr(0);
$x = $n;
$NSampStr = '';
for ($i=0; $i<4; $i++) {
$NSampStr .= chr($x % 256);
$x = floor($x/256);
}
$soundstr = 'data'.$NSampStr.$soundstr;总结和评论
我们的文本莫斯代码生成器目前看起来还不错。当然,我们还可以对它做很多的修改和完善,比如使用其他字符集、直接从文件中读取文本、生成压缩音频等等。因为我们这个项目的目的是使其能够在网络上方便的使用,所以我们这个简单的方案,已经达到我们的目的了。
相关推荐:
PHP实现迪菲赫尔曼密钥交换(Diffie–Hellman)算法
以上がPHP はテキストベースのモールス信号を生成しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。