
ホームページ >バックエンド開発 >Python チュートリアル >Python NLP の簡単な紹介
Python NLP の簡単な紹介

- 小云云オリジナル
- 2017-12-26 09:16:242601ブラウズ
この記事では、Python NLP の入門チュートリアル、Python 自然言語処理 (NLP)、Python の NLTK ライブラリの使用方法を主に紹介します。 NLTK は、Python の自然言語処理ツールキットであり、NLP の分野で最も一般的に使用されている Python ライブラリです。編集者がとても良いと思ったので、参考として共有したいと思います。編集者をフォローして見てみましょう。皆さんのお役に立てれば幸いです。
NLPとは何ですか?
簡単に言えば、自然言語処理 (NLP) は、人間の言語を理解できるアプリケーションまたはサービスの開発です。
ここでは、音声認識、音声翻訳、完全な文の理解、一致する単語の同義語の理解、文法的に正しい完全な文と段落の生成など、自然言語処理 (NLP) の実用的な応用例をいくつか説明します。
NLP でできることはこれだけではありません。
NLP 実装
検索エンジン: Google、Yahoo など。 Google 検索エンジンは、あなたが技術者であることを認識しているため、
ソーシャル Web サイトのプッシュ: Facebook ニュース フィードなどを表示します。ニュース フィード アルゴリズムがユーザーの興味が自然言語処理であることを認識している場合、関連する広告と投稿が表示されます。
音声エンジン: Apple の Siri など。
スパムフィルタリング: Googleスパムフィルタのようなもの。通常の迷惑メールフィルタリングとは異なり、メール内容の深い意味を理解して迷惑メールかどうかを判定します。
NLP ライブラリ
以下は、オープンソースの自然言語処理ライブラリ (NLP) です。
自然言語ツールキット (NLTK)
-
Stanford NLP スイート。
-
Gate NLP ライブラリ
その中で、Natural Language Toolkit (NLTK) は最も人気のある自然言語処理ライブラリ (NLP) であり、Python で書かれており、その背後に非常に強力なコミュニティ サポートがあります。
NLTK は簡単に始めることもでき、実際、最も単純な自然言語処理 (NLP) ライブラリです。
この NLP チュートリアルでは、Python NLTK ライブラリを使用します。
NLTKをインストールしますWindows/Linux/Macを使用している場合は、pipを使用してNLTKをインストールできます:
pip install nltkPythonターミナルを開いてNLTKをインポートし、NLTKが正しくインストールされているかどうかを確認します:
import nltkすべてがうまくいけば、NLTK ライブラリが正常にインストールされたことを意味します。初めて NLTK をインストールした後、次のコードを実行して NLTK 拡張パッケージをインストールする必要があります:
import nltk nltk.download()これにより、インストールする必要があるパッケージを選択するための NLTK ダウンロード ウィンドウがポップアップします:
すべてのパッケージをそのままインストールできます。サイズが小さいので問題ありません。
まず、Web ページのコンテンツをクロールし、次にテキストを分析してページのコンテンツを理解します。 urllib モジュールを使用して Web ページをクロールします。
import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() print (html)印刷された結果からわかるように、結果にはクリーニングが必要な HTML タグが多数含まれています。
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") # 这需要安装html5lib模块 text = soup.get_text(strip=True) print (text)これで、クロールされた Web ページからクリーン テキストが得られました。
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() print (tokens)
単語の頻度をカウントします
テキストが処理されました。今度は Python NLTK を使用してトークンの頻度分布をカウントします。 NLTK で FreqDist() メソッドを呼び出すことで実現できます:
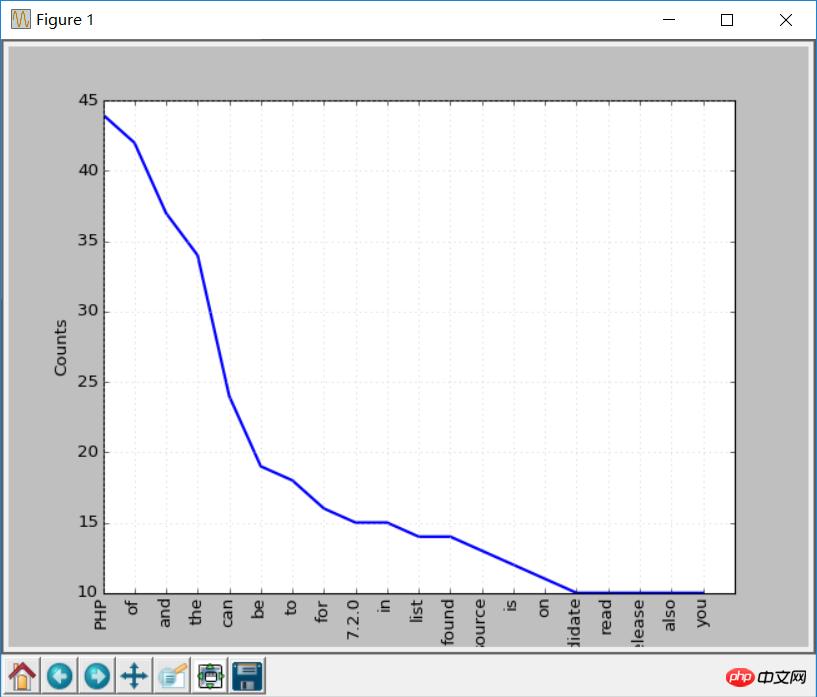
from bs4 import BeautifulSoup import urllib.request import nltk response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() freq = nltk.FreqDist(tokens) for key,val in freq.items(): print (str(key) + ':' + str(val))出力結果を検索すると、最も一般的なトークンが PHP であることがわかります。
freq.plot(20, cumulative=False) # 需要安装matplotlib库
 一般に、ストップワードは分析結果に影響を与えないように削除する必要があります。
一般に、ストップワードは分析結果に影響を与えないように削除する必要があります。
NLTK には多くの言語のストップワードリストが付属しています:
from nltk.corpus import stopwords stopwords.words('english')次に、トークンを描画する前にコードを変更し、無効なストップワードをいくつかクリアします:
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if token not in sr:
clean_tokens.append(token) 最終的なコードは次のようになります:from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if not token in sr:
clean_tokens.append(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val)) ここで単語の出現頻度グラフをもう一度実行します。ストップワードが削除されているため、効果は以前よりも良くなります:
freq.plot(20,cumulative=False)
NLTK を使用してテキストをトークン化する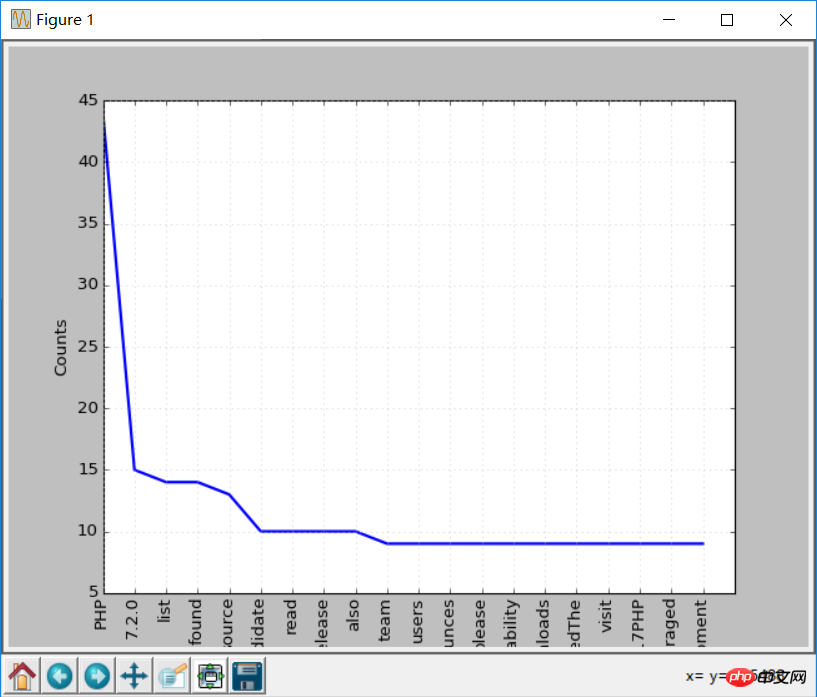
以前は、split メソッドを使用してテキストをトークンに分割していましたが、今では NLTK を使用してテキストをトークン化しています。 テキストはトークン化せずに処理できないため、テキストをトークン化することが非常に重要です。トークン化のプロセスは、大きな部分を小さな部分に分割することを意味します。
你可以将段落tokenize成句子,将句子tokenize成单个词,NLTK分别提供了句子tokenizer和单词tokenizer。
假如有这样这段文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
使用句子tokenizer将文本tokenize成句子:
from nltk.tokenize import sent_tokenize mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这是你可能会想,这也太简单了,不需要使用NLTK的tokenizer都可以,直接使用正则表达式来拆分句子就行,因为每个句子都有标点和空格。
那么再来看下面的文本:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
这样如果使用标点符号拆分,Hello Mr将会被认为是一个句子,如果使用NLTK:
from nltk.tokenize import sent_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这才是正确的拆分。
接下来试试单词tokenizer:
from nltk.tokenize import word_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(word_tokenize(mytext))
输出如下:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']
Mr.这个词也没有被分开。NLTK使用的是punkt模块的PunktSentenceTokenizer,它是NLTK.tokenize的一部分。而且这个tokenizer经过训练,可以适用于多种语言。
非英文Tokenize
Tokenize时可以指定语言:
from nltk.tokenize import sent_tokenize mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour." print(sent_tokenize(mytext,"french"))
输出结果如下:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]
同义词处理
使用nltk.download()安装界面,其中一个包是WordNet。
WordNet是一个为自然语言处理而建立的数据库。它包括一些同义词组和一些简短的定义。
您可以这样获取某个给定单词的定义和示例:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())输出结果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
WordNet包含了很多定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())结果如下:
the branch of information science that deals with natural language information
large Old World boas
可以像这样使用WordNet来获取同义词:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)输出:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
反义词处理
也可以用同样的方法得到反义词:
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)输出:
['large', 'big', 'big']
词干提取
语言形态学和信息检索里,词干提取是去除词缀得到词根的过程,例如working的词干为work。
搜索引擎在索引页面时就会使用这种技术,所以很多人为相同的单词写出不同的版本。
有很多种算法可以避免这种情况,最常见的是波特词干算法。NLTK有一个名为PorterStemmer的类,就是这个算法的实现:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('working')) print(stemmer.stem('worked'))
输出结果是:
work
work
还有其他的一些词干提取算法,比如 Lancaster词干算法。
非英文词干提取
除了英文之外,SnowballStemmer还支持13种语言。
支持的语言:
from nltk.stem import SnowballStemmer print(SnowballStemmer.languages) 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
你可以使用SnowballStemmer类的stem函数来提取像这样的非英文单词:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))单词变体还原
单词变体还原类似于词干,但不同的是,变体还原的结果是一个真实的单词。不同于词干,当你试图提取某些词时,它会产生类似的词:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('increases'))
结果:
increas
现在,如果用NLTK的WordNet来对同一个单词进行变体还原,才是正确的结果:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('increases'))
结果:
increase
结果可能会是一个同义词或同一个意思的不同单词。
有时候将一个单词做变体还原时,总是得到相同的词。
这是因为语言的默认部分是名词。要得到动词,可以这样指定:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('playing', pos="v"))
结果:
play
实际上,这也是一种很好的文本压缩方式,最终得到文本只有原先的50%到60%。
结果还可以是动词(v)、名词(n)、形容词(a)或副词(r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))输出:
play
playing
playing
playing
词干和变体的区别
通过下面例子来观察:
from nltk.stem import WordNetLemmatizer from nltk.stem import PorterStemmer stemmer = PorterStemmer() lemmatizer = WordNetLemmatizer() print(stemmer.stem('stones')) print(stemmer.stem('speaking')) print(stemmer.stem('bedroom')) print(stemmer.stem('jokes')) print(stemmer.stem('lisa')) print(stemmer.stem('purple')) print('----------------------') print(lemmatizer.lemmatize('stones')) print(lemmatizer.lemmatize('speaking')) print(lemmatizer.lemmatize('bedroom')) print(lemmatizer.lemmatize('jokes')) print(lemmatizer.lemmatize('lisa')) print(lemmatizer.lemmatize('purple'))
输出:
stone
speak
bedroom
joke
lisa
purpl
---------------------
stone
speaking
bedroom
joke
lisa
purple
词干提取不会考虑语境,这也是为什么词干提取比变体还原快且准确度低的原因。
个人认为,变体还原比词干提取更好。单词变体还原返回一个真实的单词,即使它不是同一个单词,也是同义词,但至少它是一个真实存在的单词。
如果你只关心速度,不在意准确度,这时你可以选用词干提取。
在此NLP教程中讨论的所有步骤都只是文本预处理。在以后的文章中,将会使用Python NLTK来实现文本分析。
相关推荐:
以上がPython NLP の簡単な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。