
ホームページ >バックエンド開発 >Python チュートリアル >Python で Django で haystack を使用する方法: 全文検索フレームワークの例
Python で Django で haystack を使用する方法: 全文検索フレームワークの例

- 黄舟オリジナル
- 2017-10-03 06:00:562221ブラウズ
以下のエディターは、Python と Django での haystack の使用に関する記事を提供します: 全文検索フレームワーク (例付きの説明)。編集者はこれがとても良いものだと思ったので、皆さんの参考として今から共有します。編集者をフォローして一緒に見てみましょう
haystack: 全文検索フレームワーク
whoosh: 純粋な Python で書かれた全文検索エンジン
jieba: 無料の中国語単語分割パッケージ
まず、これら 3 つのパッケージをインストールします
pip install django-haystack
pip install whoosh
pip install jieba
1 settings.py ファイルを変更し、アプリケーション haystack をインストールします
2。 settings.py ファイル内で検索エンジンを設定します
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
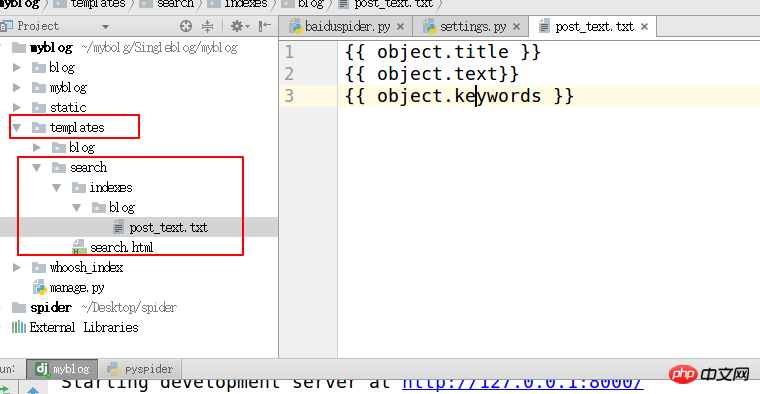
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3. templates ディレクトリの下に "search/indexes/blog/" ディレクトリを作成し、ブログ アプリケーション名の下にファイル blog_text.txt を作成します
#指定インデックスの属性
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
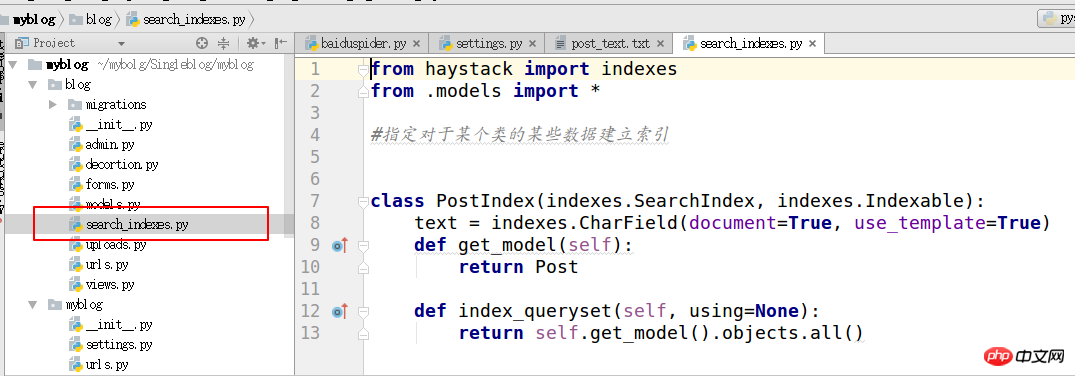
4. search_indexes を作成します
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
5.
1. haystack ファイルを変更します
2. 仮想環境 py_django で haystack ディレクトリを見つけます。このディレクトリは、使用している Python 環境に応じて異なります。
3. site-packages/haystack/backends/ ChineseAnalyzer.py という名前のファイルを作成し、中国語単語分割用の次のコードを記述します
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()6.
1. whoosh_backend.py ファイルをコピーして変更します。コピーしたファイルに中国語単語分割モジュールを次の名前でインポートします
whoosh_cn_backend.py
from . ChineseAnalyzer import ChineseAnalyzer
2. 単語分析クラスを中国語に変更します
analyzer=StemmingAnalyzer()を探して次のように変更します。 analyzer= ChineseAnalyzer()
7. 最後のステップは、初期インデックス データを作成することです
python manage.py build_index
8. template/indexes/ に検索テンプレートを作成し、search.html テンプレートを作成します
結果はページ分割され、ビューはテンプレートに渡されます。 コンテキストは次のとおりです
query: 検索キーワード
page: 現在のページのページ オブジェクト
paginator: paginator オブジェクト
9 モジュールをインポートします。独自のアプリケーション ビュー
from haystack.generic_views import SearchView
カスタム コンテキストをテンプレートに渡せるように、get_context_data メソッドをオーバーライドするクラスを定義します。
class GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
この URL をアプリケーションの URL ファイルに追加し、クラスをビュー メソッド .as_view() として使用します
url('^search/$', views.BlogSearchView.as_view())
以上がPython で Django で haystack を使用する方法: 全文検索フレームワークの例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。