
ホームページ >バックエンド開発 >Python チュートリアル >Python が XML を解析するいくつかの方法を分析する
Python が XML を解析するいくつかの方法を分析する
- 巴扎黑オリジナル
- 2017-09-19 10:20:272716ブラウズ
私が初めて PYTHON を学んだとき、DOM と SAX という 2 つの解析方法があることしか知りませんでしたが、処理する必要があるファイルの数が多かったために、これら 2 つの方法は時間がかかりすぎ、効率が理想的ではありませんでした。受け入れられない。
インターネットで検索したところ、現在広く使われており比較的効率の良いElementTreeも多くの人が推奨しているアルゴリズムであることが分かりましたので、このアルゴリズムを実際の測定と比較に使用しました。通常の ElementTree (ET )、1 つは ElementTree.iterparse(ET_iter) です。
この記事では、DOM、SAX、ET、ET_iter の 4 つのメソッドを水平比較し、同じファイルの処理にかかる時間を比較することで各アルゴリズムの効率を評価します。
4 つの解析メソッドはプログラム内で関数として記述され、解析効率を評価するためにメイン プログラムで個別に呼び出されます。
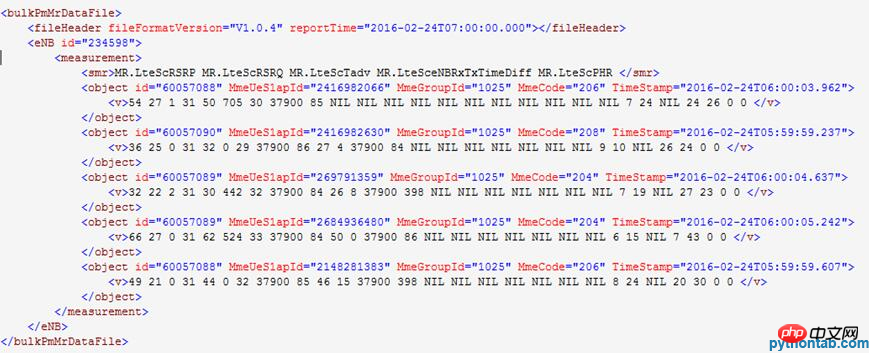
解凍された XML ファイルの内容の例は次のとおりです:
メイン プログラムの関数呼び出し部分のコードは次のとおりです:
print("文件计数:%d/%d." % (gz_cnt,paser_num))
str_s,cnt = dom_parser(gz)
#str_s,cnt = sax_parser(gz)
#str_s,cnt = ET_parser(gz)
#str_s,cnt = ET_parser_iter(gz)
output.write(str_s)
vs_cnt += cnt最初の関数呼び出しでは、関数は 2 つの値を返しますが、関数呼び出しの値を受け取るとき、2 つの変数は呼び出しはそれぞれの関数を 2 回実行することになりますが、後に 2 つの変数を同時に呼び出して戻り値を受け取るように修正され、無効な呼び出しが減りました。
1. DOM解析
関数定義コード:
def dom_parser(gz):
import gzip,cStringIO
import xml.dom.minidom
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
doc = xml.dom.minidom.parseString(xm.read())
bulkPmMrDataFile = doc.documentElement
#读入子元素
enbs = bulkPmMrDataFile.getElementsByTagName("eNB")
measurements = enbs[0].getElementsByTagName("measurement")
objects = measurements[0].getElementsByTagName("object")
#写入csv文件
for object in objects:
vs = object.getElementsByTagName("v")
vs_cnt += len(vs)
for v in vs:
file_io.write(enbs[0].getAttribute("id")+' '+object.getAttribute("id")+' '+\
object.getAttribute("MmeUeS1apId")+' '+object.getAttribute("MmeGroupId")+' '+object.getAttribute("MmeCode")+' '+\
object.getAttribute("TimeStamp")+' '+v.childNodes[0].data+'\n') #获取文本值
str_s = (((file_io.getvalue().replace(' \n','\r\n')).replace(' ',',')).replace('T',' ')).replace('NIL','')
xm.close()
file_io.close()
return (str_s,vs_cnt)プログラム実行結果:
*************************** ******* **********************
プログラムの処理が開始されます。
入力ディレクトリは /tmcdata/mro2csv/input31/ です。
出力ディレクトリは /tmcdata/mro2csv/output31/ です。
入力ディレクトリ内の .gz ファイルの数は 12 です。今回はそのうち 12 が処理されます。
*********************************************** **
ファイル数: 1/12.
読み込み: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
解析:
ファイル数: 2/12.
入力の読み取り: / tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
解析:
ファイル数: 3/12.
読み込み: /tmcdata/mro2csv/input31/TD -LTE_MRO_ NSN_OMC_123798_20160224060000.xml.
解析中:
………………………………………………
ファイル数: 12/12.
読み込み: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_20160224060000. gz.
解析:
VS 行数: 177849、実行時間: 107.077867、1 秒あたり処理される行数: 1660。
書き込み先: /tmcdata/mro2csv/output31/mro_0001.csv。
*********************************************** **
プログラムの処理が終了します。
DOM 解析ではファイル全体をメモリに読み込んでツリー構造を構築する必要があるため、メモリ消費量と消費時間が比較的多くなりますが、ロジックが単純でコールバック関数を定義する必要がないという利点があります。実装が簡単です。
2. SAXパース
関数定義コード:
def sax_parser(gz):
import os,gzip,cStringIO
from xml.parsers.expat import ParserCreate
#变量声明
d_eNB = {}
d_obj = {}
s = ''
global flag
flag = False
file_io = cStringIO.StringIO()
#Sax解析类
class DefaultSaxHandler(object):
#处理开始标签
def start_element(self, name, attrs):
global d_eNB
global d_obj
global vs_cnt
if name == 'eNB':
d_eNB = attrs
elif name == 'object':
d_obj = attrs
elif name == 'v':
file_io.write(d_eNB['id']+' '+ d_obj['id']+' '+d_obj['MmeUeS1apId']+' '+d_obj['MmeGroupId']+' '+d_obj['MmeCode']+' '+d_obj['TimeStamp']+' ')
vs_cnt += 1
else:
pass
#处理中间文本
def char_data(self, text):
global d_eNB
global d_obj
global flag
if text[0:1].isnumeric():
file_io.write(text)
elif text[0:17] == 'MR.LteScPlrULQci1':
flag = True
#print(text,flag)
else:
pass
#处理结束标签
def end_element(self, name):
global d_eNB
global d_obj
if name == 'v':
file_io.write('\n')
else:
pass
#Sax解析调用
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
vs_cnt = 0
str_s = ''
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
for line in xm.readlines():
parser.Parse(line) #解析xml文件内容
if flag:
break
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)プログラム実行結果:
*************************** ***** **********************
プログラムの処理が開始されます。
入力ディレクトリは /tmcdata/mro2csv/input31/ です。
出力ディレクトリは /tmcdata/mro2csv/output31/ です。
入力ディレクトリ内の .gz ファイルの数は 12 です。今回はそのうち 12 が処理されます。
*********************************************** **
ファイル数: 1/12.
読み込み: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
解析:
ファイル数: 2/12.
入力の読み取り: / tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
解析:
ファイル数: 3/12.
読み込み: /tmcdata/mro2csv/input31/TD -LTE_MRO_ NSN_OMC_123798_20160224060000.xml.
解析中:
.................................................
ファイル数: 12/12.
読み込み: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析:
VS行数: 177849、実行時間:14.386779、毎秒数値処理された行数: 12361。
書き込み先: /tmcdata/mro2csv/output31/mro_0001.csv。
*********************************************** **
プログラムの処理が終了します。
SAX 解析は DOM 解析よりも実行時間が大幅に短く、SAX は行ごとの解析を使用するため、より大きなファイルの処理に必要なメモリの消費量が少なくなります。そのため、SAX 解析は現在広く使用されている解析方法です。欠点は、コールバック関数を自分で実装する必要があり、ロジックが比較的複雑であることです。
3.ET分析
関数定義コード:
def ET_parser(gz):
import os,gzip,cStringIO
import xml.etree.cElementTree as ET
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
tree = ET.ElementTree(file=xm)
root = tree.getroot()
for elem in root[1][0].findall('object'):
for v in elem.findall('v'):
file_io.write(root[1].attrib['id']+' '+elem.attrib['TimeStamp']+' '+elem.attrib['MmeCode']+' '+\
elem.attrib['id']+' '+ elem.attrib['MmeUeS1apId']+' '+ elem.attrib['MmeGroupId']+' '+ v.text+'\n')
vs_cnt += 1
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)プログラム実行結果:
**************************** * *********************
プログラムの処理が開始されます。
入力ディレクトリは /tmcdata/mro2csv/input31/ です。
出力ディレクトリは /tmcdata/mro2csv/output31/ です。
入力ディレクトリ内の .gz ファイルの数は 12 です。今回はそのうち 12 が処理されます。
*********************************************** **
ファイル数: 1/12.
読み込み: /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
解析:
ファイル数: 2/12.
入力の読み取り: / tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
解析:
ファイル数: 3/12.
読み込み: /tmcdata/mro2csv/input31/TD -LTE_MRO_ NSN_OMC_123798_20160224060000.xml.
解析中:
...........................................
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析中:
VS行计数:177849,运行时间:4.308103,每秒处理行数:41282。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
相较于SAX解析,ET解析时间更短,并且函数实现也比较简单,所以ET具有类似DOM的简单逻辑实现且匹敌SAX的解析效率,因此ET是目前XML解析的首选。
4、ET_iter解析
函数定义代码:
def ET_parser_iter(gz):
import os,gzip,cStringIO
import xml.etree.cElementTree as ET
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
d_eNB = {}
d_obj = {}
i = 0
for event,elem in ET.iterparse(xm,events=('start','end')):
if i >= 2:
break
elif event == 'start':
if elem.tag == 'eNB':
d_eNB = elem.attrib
elif elem.tag == 'object':
d_obj = elem.attrib
elif event == 'end' and elem.tag == 'smr':
i += 1
elif event == 'end' and elem.tag == 'v':
file_io.write(d_eNB['id']+' '+d_obj['TimeStamp']+' '+d_obj['MmeCode']+' '+d_obj['id']+' '+\
d_obj['MmeUeS1apId']+' '+ d_obj['MmeGroupId']+' '+str(elem.text)+'\n')
vs_cnt += 1
elem.clear()
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
解析中:
...................................................
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析中:
VS行计数:177849,运行时间:3.043805,每秒处理行数:58429。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
在引入了ET_iter解析后,解析效率比ET提升了近50%,而相较于DOM解析更是提升了35倍,在解析效率提升的同时,由于其采用了iterparse这个循序解析的工具,其内存占用也是比较小的。
以上がPython が XML を解析するいくつかの方法を分析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。