
ホームページ >Java >&#&チュートリアル >JavaでのLRUアルゴリズムの使い方を詳しく解説
JavaでのLRUアルゴリズムの使い方を詳しく解説

- 黄舟オリジナル
- 2017-09-15 10:35:222025ブラウズ
この記事では主に Java LRU アルゴリズムを紹介します。LRU アルゴリズムの概念を簡単に紹介し、LRU アルゴリズムの具体的な使用法を例の形式で分析します。この記事の例は、 Java LRU アルゴリズムの概要と使用法。参考のために皆さんと共有してください。詳細は次のとおりです:
1. はじめにユーザーがネットワーク化されたソフトウェアを使用する場合、同じデータが 1 つのネットワーク内で複数回使用される場合、常にネットワークからデータを取得します。その時点で、ユーザーがインターネットを使用するたびにインターネットにアクセスしてリクエストを行うことは不可能であり、時間とネットワークの無駄です
この時点で、ユーザーがリクエストしたデータは保存できますが、ただし、すべてのデータが保存されるわけではないため、メモリが無駄に消費されます。 LRUアルゴリズムの考え方が応用できます。
2. LRU の概要 LRU は、長期間使用されていないデータを削除できるアルゴリズムです。
LRU は一部の人々の感情にもよく反映されています。友人のグループと連絡をとっているとき、頻繁に連絡を取る人々との関係は非常に良好であり、長期間連絡を取らなかったり、おそらく二度と連絡を取らなかったりすると、その関係は失われます。友人。
3. 次のコードは LRU アルゴリズムを示しています: 設定されたキャッシュ範囲内の余分な古いデータを削除するメソッドがあるため、最も簡単な方法は LinkHashMap を使用することです
public class LRUByHashMap<K, V> {
/*
* 通过LinkHashMap简单实现LRU算法
*/
/**
* 缓存大小
*/
private int cacheSize;
/**
* 当前缓存数目
*/
private int currentSize;
private LinkedHashMap<K, V> maps;
public LRUByHashMap(int cacheSize1) {
this.cacheSize = cacheSize1;
maps = new LinkedHashMap<K, V>() {
/**
*
*/
private static final long serialVersionUID = 1;
// 这里移除旧的缓存数据
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// 当超过缓存数量的时候就将旧的数据移除
return getCurrentSize() > LRUByHashMap.this.cacheSize;
}
};
}
public synchronized int getCurrentSize() {
return maps.size();
}
public synchronized void put(K k, V v) {
if (k == null) {
throw new Error("存入的键值不能为空");
}
maps.put(k, v);
}
public synchronized void remove(K k) {
if (k == null) {
throw new Error("移除的键值不能为空");
}
maps.remove(k);
}
public synchronized void clear() {
maps = null;
}
// 获取集合
public synchronized Collection<V> getCollection() {
if (maps != null) {
return maps.values();
} else {
return null;
}
}
public static void main(String[] args) {
// 测试
LRUByHashMap<Integer, String> maps = new LRUByHashMap<Integer, String>(
3);
maps.put(1, "1");
maps.put(2, "2");
maps.put(3, "3");
maps.put(4, "4");
maps.put(5, "5");
maps.put(6, "6");
Collection<String> col = maps.getCollection();
System.out.println("存入缓存中的数据是--->>" + col.toString());
}
}後の効果実行中:
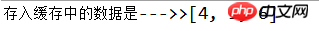 コードは明らかに 6 つのエントリを配置しましたが、最終的に表示されたのは 3 つだけでした。間の 3 つは古いため、直接クリックされませんでした
コードは明らかに 6 つのエントリを配置しましたが、最終的に表示されたのは 3 つだけでした。間の 3 つは古いため、直接クリックされませんでした
2 番目のタイプの方法は、二重リンクされたリスト + HashTable を使用することです
。二重リンクリストの役割は位置を記録することであり、HashTable はデータを保存するコンテナとして使用されます
なぜ HashMap の代わりに HashTable を使用するのですか?
1. HashTable のキーと値を null にすることはできません。
2. 上記の LinkHashMap で実装された LRU は、スレッドが同期的に処理できるようにするため、マルチスレッドが統合データを処理する際の問題を回避します。 HashTable 独自の同期メカニズムを備えているため、マルチスレッドで HashTable を正しく処理できます。
すべてのキャッシュは位置ダブルリストで接続されており、位置がヒットすると、リンクされたリストのポインティングを調整することで、位置がリンクされたリストの先頭の位置に調整されます。リンクされたリストの先頭。このようにして、複数のキャッシュ操作の後、最後にヒットしたものはリンク リストの先頭に移動され、ヒットしなかったものはリンク リストの末尾に移動されます。最も最近使用されていないキャッシュ。コンテンツを置き換える必要がある場合、リンク リストの最後の位置が最もヒットしない位置になります。リンク リストの最後の部分を削除するだけで済みます
public class LRUCache {
private int cacheSize;
private Hashtable<Object, Entry> nodes;//缓存容器
private int currentSize;
private Entry first;//链表头
private Entry last;//链表尾
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable<Object, Entry>(i);//缓存容器
}
/**
* 获取缓存中对象,并把它放在最前面
*/
public Entry get(Object key) {
Entry node = nodes.get(key);
if (node != null) {
moveToHead(node);
return node;
} else {
return null;
}
}
/**
* 添加 entry到hashtable, 并把entry
*/
public void put(Object key, Object value) {
//先查看hashtable是否存在该entry, 如果存在,则只更新其value
Entry node = nodes.get(key);
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new Entry();
}
node.value = value;
//将最新使用的节点放到链表头,表示最新使用的.
node.key = key
moveToHead(node);
nodes.put(key, node);
}
/**
* 将entry删除, 注意:删除操作只有在cache满了才会被执行
*/
public void remove(Object key) {
Entry node = nodes.get(key);
//在链表中删除
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
//在hashtable中删除
nodes.remove(key);
}
/**
* 删除链表尾部节点,即使用最后 使用的entry
*/
private void removeLast() {
//链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* 移动到链表头,表示这个节点是最新使用过的
*/
private void moveToHead(Entry node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
/*
* 清空缓存
*/
public void clear() {
first = null;
last = null;
currentSize = 0;
}
}
class Entry {
Entry prev;//前一节点
Entry next;//后一节点
Object value;//值
Object key;//键
}。以上がJavaでのLRUアルゴリズムの使い方を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- Javaのクラスロードメカニズムは、さまざまなクラスローダーやその委任モデルを含むどのように機能しますか?
- 適切なバージョン化と依存関係管理を備えたカスタムJavaライブラリ(JARファイル)を作成および使用するにはどうすればよいですか?
- キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPA(Java Persistence API)を使用するにはどうすればよいですか?
- カフェインやグアバキャッシュなどのライブラリを使用して、Javaアプリケーションにマルチレベルキャッシュを実装するにはどうすればよいですか?
- 高度なJavaプロジェクト管理、自動化の構築、依存関係の解像度にMavenまたはGradleを使用するにはどうすればよいですか?