
ホームページ >バックエンド開発 >Python チュートリアル >Python での Numpy と Pandas の使用の概要
Python での Numpy と Pandas の使用の概要
- 巴扎黑オリジナル
- 2017-09-13 10:04:382847ブラウズ
最近、一連のデータを前年比で比較する必要があり、計算に numpy と pandas を使用する必要があります。次の記事では、Python 学習チュートリアルでの Numpy と Pandas の使用に関する関連情報を主に紹介します。記事ではサンプルコードを通じて詳しく紹介していますので、困っている人は参考にしてください。
前書き
この記事では主に Python での Numpy と Pandas の使用に関する関連情報を紹介し、参考と学習のために共有します。以下では多くを述べません。詳しい紹介。
それらは何ですか?
NumPy は、Python 言語の拡張ライブラリです。高度な大規模次元配列および行列演算をサポートし、配列演算用の多数の数学関数ライブラリも提供します。
Pandas は、データ分析タスクを解決するために作成された NumPy に基づくツールです。 Pandas には、大規模なデータ セットを効率的に操作するために必要なツールを提供するために、多数のライブラリといくつかの標準データ モデルが組み込まれています。 Pandas は、データを迅速かつ簡単に処理できるようにする関数とメソッドを多数提供します。
List、Numpy、Pandas
Numpy と List
は同じです:
はすべて添え字を使用して要素にアクセスできます。たとえば、a[0]
はすべてアクセスできますたとえば、a[1:3]
は for ループを使用して走査できます
違い:
-
の各要素タイプは同じである必要がありますが、複数のタイプの要素は同じである必要があります。 List
に混ぜることができます Numpyは、mean、std、sum、min、maxなどの多くの関数をカプセル化して、より使いやすくなります
Numpyは多次元配列にすることができます
Numpy Cで実装されており、操作が高速です
PandasはNumpyと同じです
:
アクセス要素は同じで、添字を使用でき、スライスアクセスも使用できます
For ループを使用してトラバースできます
mean、std、sum、min、max などの便利な関数がたくさんあります
ベクトル演算を実行できます
は C で実装されています
より高速です
違い: Pandas には、describe 関数など、Numpy にはないメソッドがいくつかあります。主な違いは、Numpy は List の拡張バージョンのようなものであるのに対し、Pandas はリストと辞書のコレクションのようなもので、Pandas にはインデックスがあることです。
Numpyの使い方
1. 基本操作
import numpy as np #创建Numpy p1 = np.array([1, 2, 3]) print p1 print p1.dtype
[1 2 3] int64
#求平均值 print p1.mean()
2.0
rreee
rreee
rreee
rreee
#求标准差 print p1.std()
0.816496580928
2. ベクトル演算
#求和、求最大值、求最小值 print p1.sum() print p1.max() print p1.min()
6 3 1
#求最大值所在位置 print p1.argmax()
2
p1 = np.array([1, 2, 3]) p2 = np.array([2, 5, 7])
#向量相加,各个元素相加 print p1 + p2
[ 3 7 10]
3. インデックス配列
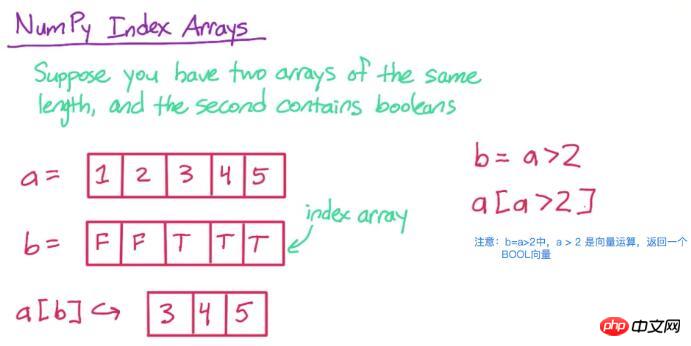 まず、下の図を見て理解してください
まず、下の図を見て理解してください
次に、コードで実装しましょう
#向量乘以1个常数 print p1 * 2
[2 4 6]
#向量相减 print p1 - p2
[-1 -3 -4]
#向量相乘,各个元素之间做运算 print p1 * p2a[b]、a 内の対応する b 位置が True である要素のみが保持されます
4。
最初に一連の操作を見てみましょう:
[ 2 10 21]
#向量与一个常数比较 print p1 > 2
[False False True]
a = np.array([1, 2, 3, 4, 5]) print a
- 上記の結果からわかるように、+= は元の配列を変更しますが、+ は変更しません。その理由は次のとおりです。
- +=: インプレース計算であり、元の配列の要素を変更すると新しい配列が作成されません。
- +: 非インプレース計算であり、新しい配列が作成されます。新しい配列。元の配列の要素は変更されません
5. Numpy のスライスと List のスライス
[1 2 3 4 5]
b = a > 2 print b
[False False True True True]
なる上記からわかるように、List 内のスライスを変更しても、その要素は元の配列に影響を与えず、Numpy がスライス内の要素を変更すると、元の配列も変更されます。これは、Numpy のスライス プログラミングでは新しい配列が作成されず、対応するスライスを変更すると元の配列データも変更されるためです。このメカニズムにより、Numpy はネイティブの配列操作よりも高速になりますが、プログラミングの際には注意が必要です。
6. 2次元配列の演算
p1 = np.array([[1, 2, 3], [7, 8, 9], [2, 4, 5]]) #获取其中一维数组 print p1[0]
[1 2 3]
#获取其中一个元素,注意它可以是p1[0, 1],也可以p1[0][1] print p1[0, 1] print p1[0][1]
2 2
#求和是求所有元素的和 print p1.sum()
41 [10 14 17]
但,当设置axis参数时,当设置为0时,是计算每一列的结果,然后返回一个一维数组;若是设置为1时,则是计算每一行的结果,然后返回一维数组。对于二维数组,Numpy中很多函数都可以设置axis参数。
#获取每一列的结果 print p1.sum(axis=0)
[10 14 17]
#获取每一行的结果 print p1.sum(axis=1)
[ 6 24 11]
#mean函数也可以设置axis print p1.mean(axis=0)
[ 3.33333333 4.66666667 5.66666667]
Pandas使用
Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
咱们主要梳理下Numpy没有的功能:
1、简单基本使用
import pandas as pd pd1 = pd.Series([1, 2, 3]) print pd1
0 1 1 2 2 3 dtype: int64
#也可以求和和标准偏差 print pd1.sum() print pd1.std()
6 1.0
2、索引
(1)Series中的索引
p1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) print p1
a 1 b 2 c 3 dtype: int64
print p1['a']
(2)DataFrame数组
p1 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print p1age name 0 18 Jack 1 19 Lucy 2 21 Coke
#获取name一列 print p1['name']
0 Jack 1 Lucy 2 Coke Name: name, dtype: object
#获取姓名的第一个 print p1['name'][0]
Jack
#使用p1[0]不能获取第一行,但是可以使用iloc print p1.iloc[0]
age 18 name Jack Name: 0, dtype: object
总结:
获取一列使用p1[‘name']这种索引
获取一行使用p1.iloc[0]
3、apply使用
apply可以操作Pandas里面的元素,当库里面没用对应的方法时,可以通过apply来进行封装
def func(value): return value * 3 pd1 = pd.Series([1, 2, 5])
print pd1.apply(func)
0 3 1 6 2 15 dtype: int64
同样可以在DataFrame上使用:
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print pd2.apply(func)age name 0 54 JackJackJack 1 57 LucyLucyLucy 2 63 CokeCokeCoke
4、axis参数
Pandas设置axis时,与Numpy有点区别:
当设置axis为'columns'时,是计算每一行的值
当设置axis为'index'时,是计算每一列的值
pd2 = pd.DataFrame({
'weight': [120, 130, 150],
'age': [18, 19, 21]
})0 138 1 149 2 171 dtype: int64
#计算每一行的值 print pd2.sum(axis='columns')
0 138 1 149 2 171 dtype: int64
#计算每一列的值 print pd2.sum(axis='index')
age 58 weight 400 dtype: int64
5、分组
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke', 'Pol', 'Tude'],
'age': [18, 19, 21, 21, 19]
})
#以年龄分组
print pd2.groupby('age').groups{18: Int64Index([0], dtype='int64'), 19: Int64Index([1, 4], dtype='int64'), 21: Int64Index([2, 3], dtype='int64')}6、向量运算
需要注意的是,索引数组相加时,对应的索引相加
pd1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) pd2 = pd.Series( [1, 2, 3], index = ['a', 'c', 'd'] )
print pd1 + pd2
a 2.0 b NaN c 5.0 d NaN dtype: float64
出现了NAN值,如果我们期望NAN不出现,如何处理?使用add函数,并设置fill_value参数
print pd1.add(pd2, fill_value=0)
a 2.0 b 2.0 c 5.0 d 3.0 dtype: float64
同样,它可以应用在Pandas的dataFrame中,只是需要注意列与行都要对应起来。
总结
这一周学习了优达学城上分析基础的课程,使用的是Numpy与Pandas。对于Numpy,以前在Tensorflow中用过,但是很不明白,这次学习之后,才知道那么简单,算是有一定的收获。
以上がPython での Numpy と Pandas の使用の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。