
ホームページ >Java >&#&チュートリアル >Java仮想マシンにおけるリサイクル機構の研究
Java仮想マシンにおけるリサイクル機構の研究
- 一个新手オリジナル
- 2017-09-07 15:38:411837ブラウズ
1: 概要
ガベージ コレクション (ガベージ コレクション、GC) といえば、多くの人は自然に Java を連想するでしょう。 Java では、プログラマは動的なメモリ割り当てやガベージ コレクションについて心配する必要はありません。その名前が示すように、ガベージ コレクションはガベージによって占有されている領域を解放することを目的としており、これらはすべて JVM に任せられます。この記事は主に 3 つの質問に答えます:
1. どのメモリをリサイクルする必要がありますか? (どのような物体が「ゴミ」とみなされるのか)
2. リサイクルするにはどうすればよいですか? (一般的に使用されるガベージ コレクション アルゴリズム)
3. リサイクルにはどのようなツールが使用されますか? (ガベージ コレクター)
2. JVM ガベージ判定アルゴリズム
一般的に使用されるガベージ判定アルゴリズムには、参照カウント アルゴリズムと到達可能性分析アルゴリズムが含まれます。
1. 参照カウントアルゴリズム
Java は参照を通じてオブジェクトに関連付けられます。つまり、オブジェクトを操作したい場合は参照を通じて行う必要があります。オブジェクトに参照カウンタを追加すると、参照が存在するたびにカウンタ値が 1 ずつ増加します。カウンタが 0 のオブジェクトは常に使用できません。もはや、つまり、オブジェクトがリサイクルの対象として「ゴミ」とみなされることを示します。
参照カウンタ アルゴリズムは実装が簡単で非常に効率的ですが、循環参照の問題は解決できません (オブジェクト A がオブジェクト B を参照し、オブジェクト B がオブジェクト A を参照しますが、オブジェクト A と B は参照されなくなります)。同時に、カウンタの増減により多くの余分なオーバーヘッドが発生するため、JDK1.1 以降、このアルゴリズムは使用されなくなりました。コード:
public class Main {
public static void main(String[] args) {
MyTest test1 = new MyTest();
MyTest test2 = new MyTest();
test1.obj = test2;
test2.obj = test1;//test1与test2存在相互引用
test1 = null;
test2 = null;
System.gc();//回收
}
}
class MyTest{
public Object obj = null;
}test1とtest2には最終的にnullが代入されていますが、つまりtest1とtest2が指すオブジェクトにはアクセスできなくなりますが、相互に参照しているため参照カウントが0ではなくゴミとなっています。コレクターは決してそれらを回収しません。プログラムの実行後、メモリ分析から、これら 2 つのオブジェクトのメモリが実際にリサイクルされていることがわかります。これは、現在の主流の JVM がガベージ判定アルゴリズムとして参照カウンタ アルゴリズムを使用していないことも示しています。
2. 到達可能性分析アルゴリズム(ルート検索アルゴリズム)
ルート検索アルゴリズムは、いくつかの「GC Roots」オブジェクトを開始点として使用し、これらのノードから下方向に検索し、検索によって通過したパスが参照チェーンになります
(参考) Chain) では、オブジェクトが GC ルートの参照チェーンによって接続されていない場合、そのオブジェクトは利用できないことを意味します。
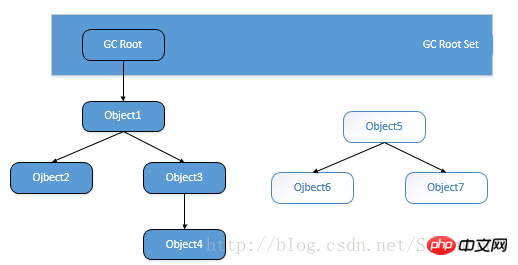
GC ルート オブジェクトには次のものが含まれます:
a) 仮想マシン スタック (スタック フレーム内のローカル変数テーブル) で参照されるオブジェクト。
b) メソッド領域のクラス静的プロパティによって参照されるオブジェクト。
c) メソッド領域の定数によって参照されるオブジェクト。
d) ネイティブ メソッド スタック内の JNI (一般にネイティブ メソッドとして知られる) によって参照されるオブジェクト。
到達可能性分析アルゴリズムでは、現時点では、到達不可能なオブジェクトは一時的に「停止」段階にあり、オブジェクトが実際に停止していると宣言するには、少なくとも 2 つのマーキング プロセスを経る必要があります。到達可能性分析の結果、オブジェクトが GC ルートに接続されている参照チェーンがないことが判明した場合、そのオブジェクトは初めてマークされ、1 回フィルターされます。フィルター条件は、オブジェクトが Finalize() メソッドを実行する必要があるかどうかです。オブジェクトが Finalize() メソッドをカバーしていない場合、または仮想マシンによって Finalize() メソッドが呼び出された場合、仮想マシンは両方の状況を「実行する必要がない」ものとして扱います。どのオブジェクトの Finalize() メソッドも、システムによって自動的に 1 回だけ実行されることに注意してください。
このオブジェクトが Finalize() メソッドを実行する必要があると判断された場合、このオブジェクトは F-Queue と呼ばれるキューに配置され、後で実行する仮想マシン スレッドによって優先度の低いファイナライザーによって自動的に作成されます。それ。ここでのいわゆる「実行」とは、仮想マシンがこのメソッドをトリガーしますが、実行が完了するまで待機することを約束しないことを意味します。その理由は、オブジェクトの Finalize() メソッドの実行が遅い場合、または無限に実行される場合です。ループが発生すると、F-Queue キュー内の他のオブジェクトが永続的に待機したり、メモリ リサイクル システム全体がクラッシュしたりする可能性があり、非常に困難になります。したがって、finalize() メソッドを呼び出しても、メソッド内のコードが完全に実行できることを意味するわけではありません。
finalize() メソッドは、オブジェクトが死の運命から逃れる最後のチャンスです。その後、オブジェクトがファイナライズで自身を正常に保存したい場合、GC はそのオブジェクトを F キューにマークします。 () - 参照チェーン上の任意のオブジェクトとの関連付けを再確立するだけです。たとえば、自分自身 (このキーワード) をオブジェクトのクラス変数またはメンバー変数に割り当てます。その後、それは "About to." から削除されます。 「コレクション」。この時点でオブジェクトがエスケープされていない場合、基本的には実際にリサイクルされます。次のコードから、オブジェクトの Finalize() が実行されても、まだ存続していることがわかります。
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finalize()方法最多只会被系统自动调用一次
*/ public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, i am still alive :)");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize mehtod executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
public static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinalizeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finalize方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finalize方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
}
}実行結果:
finalize mehtod executed! yes, i am still alive :) no, i am dead :(
从运行结果可以看出,SAVE_HOOK对象的finalize()方法确实被GC收集器调用过,且在被收集前成功逃脱了。
另外一个值得注意的地方是,代码中有两段完全一样的代码片段,执行结果却是一次逃脱成功,一次失败,这是因为任何一个对象的finalize()方法都只会被系统自动调用一次,如果对象面临下一次回收,它的finalize()方法不会被再次执行,因此第二段代码的自救行动失败了。
三、JVM垃圾回收算法
常用的垃圾回收算法包括:标记-清除算法,复制算法,标记-整理算法,分代收集算法
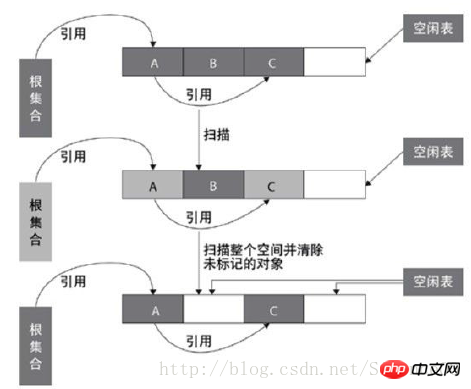
1、标记—清除算法(Mark-Sweep)(DVM 使用的算法)
标记—清除算法包括两个阶段:“标记”和“清除”。在标记阶段,确定所有要回收的对象,并做标记。清除阶段紧随标记阶段,将标记阶段确定不可用的对象清除。标记—清除算法是基础的收集算法,标记和清除阶段的效率不高,而且清除后回产生大量的不连续空间,这样当程序需要分配大内存对象时,可能无法找到足够的连续空间。
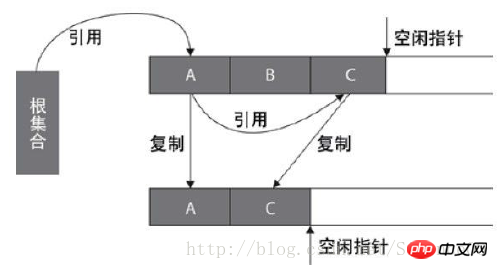
2、复制算法(Copying)
复制算法是把内存分成大小相等的两块,每次使用其中一块,当垃圾回收的时候,把存活的对象复制到另一块上,然后把这块内存整个清理掉。复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM 用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1)。
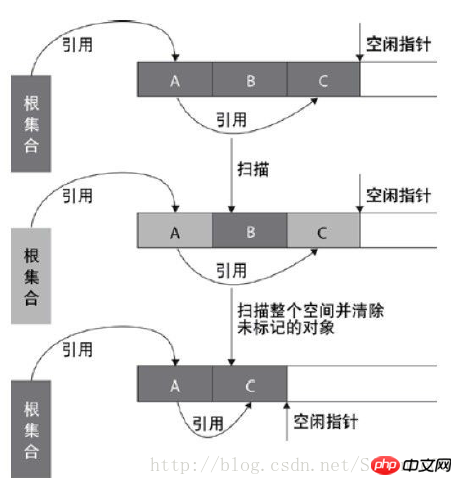
3、标记—整理算法(Mark-Compact)
标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
4、分代收集(Generational Collection)
分代收集是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
四、垃圾收集器
如果说垃圾收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。上面说过,各个平台虚拟机对内存的操作各不相同,因此本章所讲的收集器是基于JDK1.7Update14之后的HotSpot虚拟机。这个虚拟机包含的所有收集器如图:
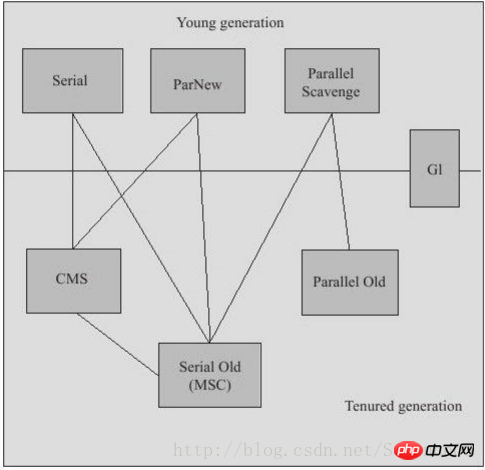
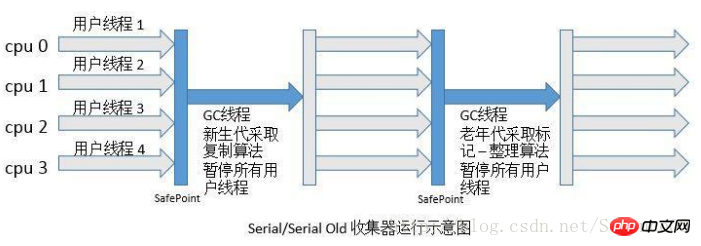
1、Serial收集器
Serial收集器是最基本、发展历史最悠久的收集器,曾经(在JDK 1.3.1之前)是虚拟机
新生代收集的唯一选择。大家看名字就会知道,这个收集器是一个单线程的收集器,但它
的“单线程”的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,
更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
2、ParNew收集器
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集之
外,其余行为包括Serial收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX:
PretenureSizeThreshold、-XX:HandlePromotionFailure等)、收集算法、Stop The World、对
象分配规则、回收策略等都与Serial收集器完全一样,在实现上,这两种收集器也共用了相
当多的代码。
3. Parallel Scavenge Collector
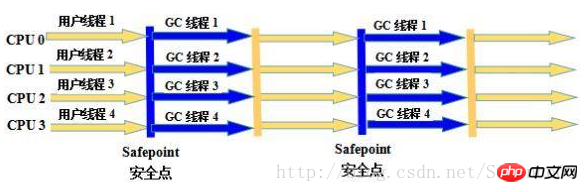
Parallel Scavenge Collector の特徴は、制御可能なスループット (Throughput) を達成することを目的としている点です。いわゆるスループットは、消費された合計 CPU 時間に対する CPU がユーザー コードの実行に費やした時間の比率です。つまり、スループット = ユーザー コードの実行時間/(ユーザー コードの実行時間 + ガベージ コレクション時間)です。スループットと密接な関係があるため、Parallel Scavenge コレクターは「スループット優先」コレクターと呼ばれることがよくあります。
4. Serial Old コレクター
Serial Old は、シリアル コレクターの旧世代バージョンであり、「マークソート」アルゴリズムを使用します。このコレクターの主な意義は、クライアント モードの仮想マシンでも使用されることです。サーバー モードの場合、主に 2 つの用途があります。1 つは JDK 1.5 および以前のバージョン [1] の Parallel Scavenge コレクターで使用され、もう 1 つは CMS コレクターのバックアップ プランとして使用されます。同時収集で ConcurrentMode Failure が発生した場合に使用されます。
5. Parallel Old コレクター
Parallel Old は、マルチスレッドと「マークソート」アルゴリズムを使用する、Parallel Scavenge コレクターの旧世代バージョンです。
このコレクターは JDK 1.6 でのみ提供されました。
6. CMS コレクター
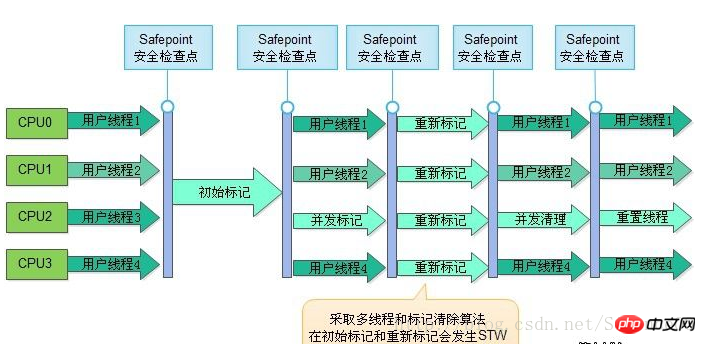
CMS (同時マーク スイープ) コレクターは、最短のリサイクル一時停止時間を取得することを目的としたコレクターです。現在、Java アプリケーションの大部分はインターネット Web サイトや B/S システムのサーバーに集中しており、このようなアプリケーションはサービスの応答速度に特別な注意を払っており、ユーザーにサービスを提供するためにシステムの停止時間が最短であることを望んでいます。より良い体験を。
操作プロセスは次の 4 つのステップに分かれています:
a) 初期マーク (CMS 初期マーク)
b) 同時マーク (CMS 同時マーク)
c) リマーク (CMS リマーク)
d) 同時スイープ (CMS 同時スイープ)
CMS コレクターには 3 つの欠点があります:
1 CPU リソースの影響を受けやすい。一般に、同時に実行されるプログラムは CPU の数に影響されます。
2 はフローティング ガベージを処理できません。同時クリーンアップ フェーズ中、ユーザー スレッドはまだ実行中であるため、この時点で生成されたガベージはクリーンアップできません。
3 マークスイープアルゴリズムにより、大量の空間断片化が生成されます。
7. G1 コレクター
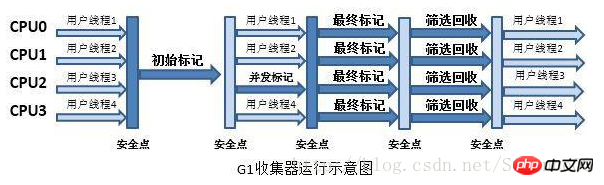
G1 は、サーバーサイド アプリケーション用のガベージ コレクターです。
G1コレクターの操作は大きく以下のステップに分かれます:
a)初期マーキング(初期マーキング)
b)同時マーキング(同時マーキング)
c)最終マーキング(ファイナルマーキング)
d)スクリーニングとリサイクル(ライブ) データのカウントと退避)
以上がJava仮想マシンにおけるリサイクル機構の研究の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。