
ホームページ >Java >&#&チュートリアル >Java フレームワークの使用法についての概要
Java フレームワークの使用法についての概要
- 巴扎黑オリジナル
- 2017-07-18 15:45:503230ブラウズ
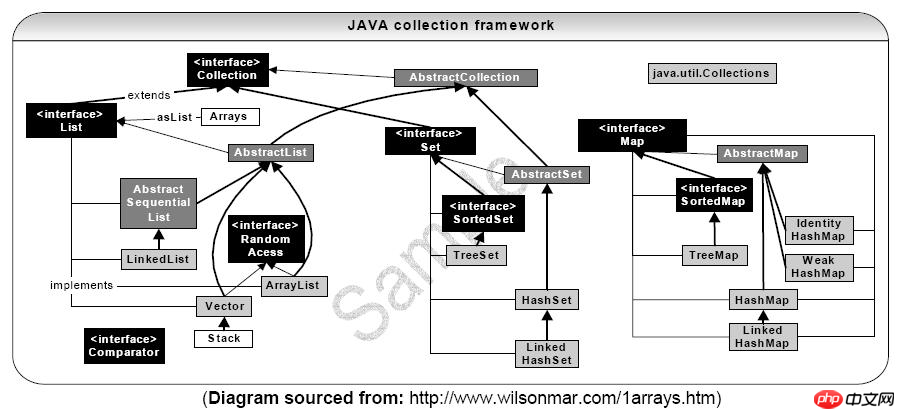
Collectionインターフェイス
Collectionは、オブジェクトのセット、つまりコレクションの要素を表します。
Collection インターフェイスを実装するすべてのクラスは、2 つの標準コンストラクターを提供する必要があります。パラメーターなしのコンストラクターは空のコレクションを作成するために使用され、Collection パラメーターを持つコンストラクターは新しいコレクションを作成するために使用されます。この新しいコレクションには同じものがあります。渡されたコレクションとしての要素。後者のコンストラクターを使用すると、ユーザーはコレクションをコピーできます。
コレクション内の各要素をトラバースするにはどうすればよいですか? Collection の実際のタイプに関係なく、イテレータを返す iterator() メソッドをサポートしています。このイテレータを使用して、コレクション内の各要素を走査し、アクセスできます。 典型的な使用法は次のとおりです:
1 Iterator it = collection.iterator(); // 获得一个迭代子2 while(it.hasNext()) {3 Object obj = it.next(); // 得到下一个元素4 }
List インターフェース
List は順序付けられた Collection であり、このインターフェースを使用すると、各要素の挿入位置を正確に制御できます。ユーザーは、Java 配列に似たインデックス (配列の添え字に似たリスト内の要素の位置) を使用して、リスト内の要素にアクセスできます。
Collection インターフェイスに必要な iterator() メソッドに加えて、List には ListIterator インターフェイスを返す listIterator() メソッドも用意されています。標準の Iterator インターフェイスと比較して、ListIterator には add() などのメソッドがいくつかあります。 、要素の追加、削除、設定、および前方または後方への移動が可能になります。
List インターフェイスを実装する一般的なクラスは、LinkedList、ArrayList、Vector、Stack です。
LinkedListクラス
LinkedListはListインターフェースを実装し、null要素を許可します。さらに、LinkedList は追加の get、remove、insert メソッドを提供します。これらの操作により、LinkedList をスタック、キュー、または両端キューとして使用できるようになります。
LinkedList には同期性がないことに注意してください。複数のスレッドが同時に LinkedList にアクセスする場合は、アクセスの同期を自分で実装する必要があります。もう 1 つの解決策は、リストの作成時に同期されたリストを構築することです。 List list = Collections.synchronizedList(new LinkedList(...));
ArrayList class
ArrayList は可変サイズの配列を実装します。 null を含むすべての要素が許可されます。 ArrayList には同期性がありません。
size、isEmpty、get、setメソッドの実行時間は一定です。ただし、add メソッドのコストは償却定数であり、n 個の要素を追加するには O(n) 時間がかかります。他の方法では実行時間が直線的になります。
各 ArrayList インスタンスには容量 (Capacity) があり、これは要素を格納するために使用される配列のサイズです。この容量は、新しい要素が追加されると自動的に増加しますが、増加アルゴリズムは定義されていません。多数の要素を挿入する必要がある場合は、挿入前に ensureCapacity メソッドを呼び出して ArrayList の容量を増やし、挿入効率を向上させることができます。
Vectorクラス
VectorはArrayListと非常によく似ていますが、Vectorは同期されています。 Vector で作成された Iterator は ArrayList で作成された Iterator と同じインターフェイスを持ちますが、Vector は同期されているため、Iterator が作成されて使用されると、別のスレッドによって Vector の状態が変更されます (たとえば、要素の追加や削除など)。 , Iterator メソッドを呼び出すと ConcurrentModificationException がスローされるため、例外をキャッチする必要があります。
Stack クラス
Stack は Vector を継承し、後入れ先出しスタックを実装します。 Stack には、Vector をスタックとして使用できるようにする 5 つの追加メソッドが用意されています。基本的なプッシュ メソッドとポップ メソッド、およびピーク メソッドはスタックの先頭にある要素を取得し、空のメソッドはスタックが空かどうかをテストし、検索メソッドはスタック内の要素の位置を検出します。スタックは、作成後の空のスタックです。
Vector、ArrayList、LinkedListの比較
1. Vectorはスレッド同期されているため、スレッドセーフでもありますが、ArrayListとLinkedListは非スレッドセーフです。スレッドの安全性要素が考慮されていない場合は、通常、ArrayList と LinkedList を使用する方が効率的です。
2.ArrayList と Vector は動的配列に基づいたデータ構造を実装し、LinkedList はリンク リスト データ構造に基づいています。
3. コレクション内の要素の数が現在のコレクション配列の長さより大きい場合、Vector の増加率は現在の配列の長さの 100%、ArrayList の増加率は現在の配列の長さの 50% になります。現在の配列の長さ コレクションでデータが使用されている場合、比較的大量のデータの場合、ベクトルの使用には一定の利点があります。
3. 指定された場所でデータを 見つけた場合、Vector と ArrayList は同じ時間を使用し、O(1) 時間がかかりますが、LinkedList は走査して検索する必要があり、O(i) 時間がかかります。最初の 2 つはそれほど効率的ではありません。
- 4. 指定した場所のデータの移動と削除にかかる時間が 0(n-i)n の場合、データの移動には時間がかかるため、現時点では LinkedList の使用を検討する必要があります。指定された場所の時刻は 0(1) です。
5.
データを指定された場所 - に挿入するには、ArrayList はデータを移動する必要があるため、LinedList が有利です。
Set インターフェイス
Set は、重複する要素を含まない Collection です。つまり、任意の 2 つの要素 e1 と e2 には e1.equals(e2)=false があり、Set には最大 1 つの要素が含まれます。ヌル要素。
- 明らかに、Set コンストラクターには、渡された Collection パラメーターに重複した要素を含めることができないという制約があります。
- 注意: 可変オブジェクトは注意して扱う必要があります。 Set 内の可変要素の状態が変化して Object.equals(Object)=true になると、いくつかの問題が発生します。
Map インターフェイス
Map は Collection インターフェイスを継承せず、Map はキーと値のマッピングを提供することに注意してください。マップに同じキーを含めることはできず、各キーは 1 つの値にのみマップできます。
Map インターフェイスは、3 種類のセット ビューを提供します。Map のコンテンツは、キー セットのセット、値セットのセット、またはキーと値のマッピングのセットと見なすことができます。
Hashtableクラス
HashtableはMapインターフェースを継承し、キーと値のマッピングのハッシュテーブルを実装します。 null 以外の任意のオブジェクトをキーまたは値として使用できます。
データを追加するには put(key, value) を使用し、データを削除するには get(key) を使用します。これら 2 つの基本操作の時間コストは一定です。
ハッシュテーブルは、初期容量と負荷率という 2 つのパラメーターを通じてパフォーマンスを調整します。通常、デフォルトの負荷係数 0.75 を使用すると、時間と空間のバランスがより良くなります。負荷率を増やすとスペースを節約できますが、それに対応する検索時間が増加し、get や put などの操作に影響します。
キーとして使用されるオブジェクトはハッシュ関数を計算することによって対応する値の位置を決定するため、キーとして使用されるオブジェクトはすべて hashCode メソッドと equals メソッドを実装する必要があります。 hashCode メソッドと equals メソッドは、ルート クラス Object から継承されます。
ハッシュテーブルは同期です。
HashMap クラス
HashMap は Hashtable に似ていますが、HashMap が非同期で null、つまり null 値と null キーを許可する点が異なります。ただし、HashMap をコレクションとして扱う場合 (values() メソッドはコレクションを返すことができます)、その反復サブ操作の時間オーバーヘッドは HashMap の容量に比例します。したがって、反復操作のパフォーマンスが非常に重要な場合は、HashMap の初期容量を高く設定しすぎたり、負荷率を低く設定しすぎたりしないでください。
TreeMap クラス
- HashMap はハッシュコードを使用して、順序付けされていないコンテンツを迅速に検索しますが、TreeMap 内のすべての要素は特定の固定順序を維持し、順序付けされています。
- Map で要素を挿入、削除、検索するには、HashMap が最適な選択です。ただし、自然な順序またはカスタム順序でキーを反復処理する場合は、TreeMap の方が適しています。 HashMap を使用するには、追加されたキー クラスが hashCode() およびquals() の実装を明確に定義する必要があります。
- ツリーは常にバランスの取れた状態にあるため、TreeMap には調整オプションがありません。
WeakHashMap クラス
WeakHashMap は、キーへの「弱参照」を実装する改良された HashMap であり、キーが外部から参照されなくなった場合、そのキーは GC によってリサイクルできます。概要
スタックやキューなどの操作が含まれる場合は、要素の高速な挿入と削除のために List の使用を検討する必要があります。要素への高速なランダム アクセスが必要な場合は、LinkedList を使用する必要があります。 、ArrayList を使用する必要があります。
- プログラムがシングルスレッド環境にある場合、またはアクセスが 1 つのスレッドでのみ実行される場合は、より効率的な非同期クラスを検討してください。複数のスレッドが同時にクラスを操作する可能性がある場合は、同期クラスを使用する必要があります。 。
- ハッシュ テーブルの操作に特に注意してください。キーとして使用されるオブジェクトは、equals メソッドと hashCode メソッドを正しく上書きする必要があります。
- Map を使用する場合、検索、更新、削除、追加には HashMap または HashTable を使用するのが最適です。Map を自然な順序またはカスタム キーの順序で移動する場合は、TreeMap を使用するのが最適です。実際の型の代わりにインターフェイスを返す (ArrayList の代わりに List を返すなど)。これにより、将来 ArrayList を LinkedList に置き換える必要がある場合でも、クライアント コードを変更する必要がありません。これは抽象化のためのプログラミングです。
以上がJava フレームワークの使用法についての概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。