
ホームページ >バックエンド開発 >Python チュートリアル >Pandas データ処理例の表示: 世界的な上場企業のデータ収集
Pandas データ処理例の表示: 世界的な上場企業のデータ収集
- 巴扎黑オリジナル
- 2017-07-22 11:39:263568ブラウズ
現在、フォーブス誌の 2016 年世界トップ 2000 上場企業データのコピーが手元にありますが、元のデータは標準化されていないため、さらに使用する前に処理する必要があります。
この記事では、データ整理のためのパンダの使用法を実践的な例を通して紹介します。
いつものように、最初に私の動作環境について話させてください、次のとおりです:
windows 7、64-bit
python 3.5
pandas version 0.19.2
オリジナルを入手した後データ、まずはデータを見て、どのようなデータ結果が必要なのかを考えてみましょう。
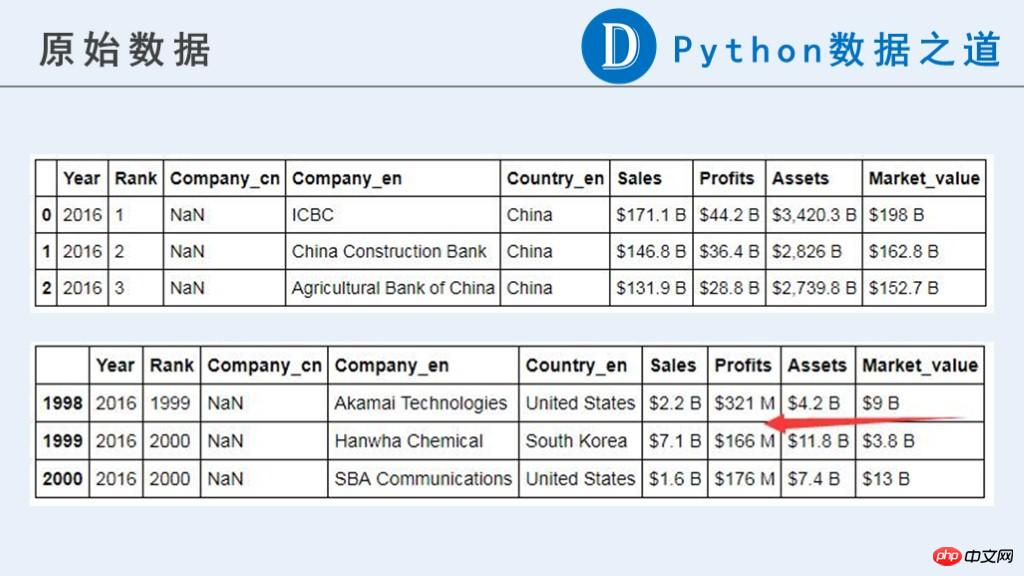
生データは次のとおりです:
この記事では、将来の使用のために次の暫定的な結果が必要です。
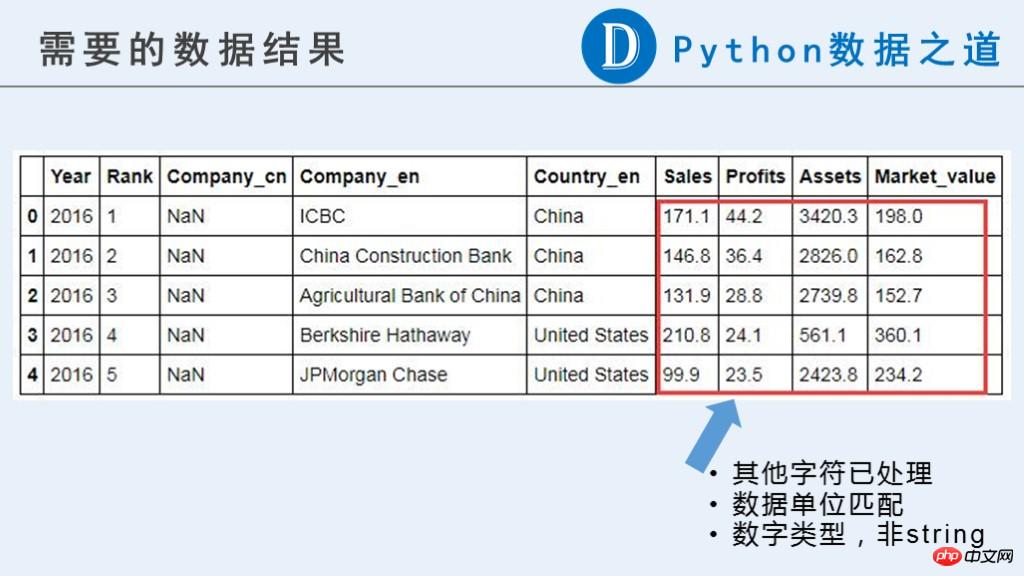
元のデータでは、企業に関連するデータ (「Sales」、「Profits」、「Assets」、「Market_value」) が、現時点では計算に使用できる数値タイプではないことがわかります。
元のコンテンツには、通貨記号「$」、「-」、純粋な文字で構成された文字列、その他異常と思われる情報が含まれています。さらに、これらのデータの単位は一貫していません。それぞれ「B」(Billion、10億)と「M」(Million、100万)で表されます。以降の計算の前に単位の統一が必要です。
1 処理方法 Method-1
最初に思い浮かぶ処理アイデアは、データ情報を数十億 ('B') と数百万 ('M') に分割し、個別に処理し、最後にそれらをマージすることです。プロセスは次のとおりです。
データをロードして列の名前を追加します
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
データを10億単位で取得します('B')
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_b
データを数百万単位で取得します('M')
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_m
この方法は理解するのが比較的簡単ですが、操作がより煩雑になり、特に処理するデータの列が多い場合は、時間がかかります。
これ以上の処理についてはここでは説明しません。もちろん、この方法を試すこともできます。
以下はもう少し簡単な方法です。
2 処理方法 方法-2
2.1 データの読み込み
最初のステップはデータの読み込みです。これは方法-1と同じです。
以下は「Sales」列の処理です
2.2 関連する異常な文字を置換します
まず、ドル通貨記号「$」、純粋なアルファベット文字列「unknown」、「」などの関連する異常な文字を置換します。 B'。 ここでは、「B」を直接置き換えることができるように、データ単位を一律に 10 億単位に編成したいと考えています。また、「M」にはさらに多くの処理ステップが必要です。
2.3 「M」関連データの処理
数百万個の「M」を単位とするデータ、つまり「M」で終わるデータを処理する場合の考え方は以下の通りです。
(1) 検索条件マスクを設定する。
( 2) 文字列「M」を null 値に置き換えます
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)
用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df
3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()
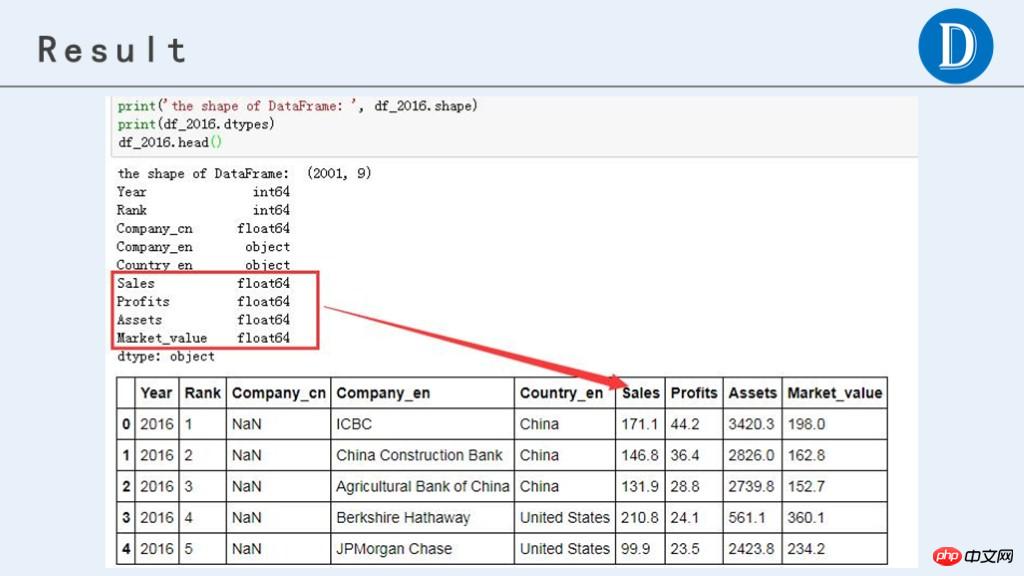
最终处理后,获得的数据结果如下:
以上がPandas データ処理例の表示: 世界的な上場企業のデータ収集の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。