
ホームページ >バックエンド開発 >Python チュートリアル >クローラーとは何ですか?クローラーの基本的なプロセスは何ですか?
クローラーとは何ですか?クローラーの基本的なプロセスは何ですか?

- 零下一度オリジナル
- 2017-07-23 13:41:0336960ブラウズ
Web クローラーは、主に検索エンジンに使用されるプログラムで、Web サイトのすべてのコンテンツとリンクを読み取り、関連する全文インデックスをデータベースに構築し、別の Web サイトにジャンプします。
インターネット (Google など) でキーワードを検索するとき、実際にはデータベース内のコンテンツを比較して、ユーザーに一致するものを見つけます。Web クローラー プログラムの品質によって、Google などの検索エンジンの機能が決まります。検索エンジン Web クローラー プログラムが効率的で、プログラミング構造が優れているため、明らかに Baidu よりも優れています
1. クローラーとは
まず、クローラーについて簡単に理解しましょう。これは、Web サイトをリクエストし、必要なデータを抽出するプロセスです。登り方や登り方については、後ほど学習する内容になりますので、今は触れる必要はありません。私たちのプログラムを通じて、私たちに代わってサーバーにリクエストを送信し、大量のデータをバッチでダウンロードできます。
2. クローラーの基本プロセス
リクエストの開始: URL を通じてサーバーへのリクエストリクエストを開始します。リクエストには追加のヘッダー情報を含めることができます。
応答コンテンツを取得する: サーバーが正常に応答した場合、応答は要求した Web ページのコンテンツであり、HTML、Json 文字列、またはバイナリ データ (ビデオ、画像) が含まれる場合があります。
コンテンツの解析: HTML コードの場合は、Web ページ パーサーを使用して解析できます。Json データの場合は、解析用の Json オブジェクトに変換できます。さらなる処理のためにファイルに保存されます。
データの保存: ローカルファイルまたはデータベース (MySQL、Redis、Mongodb など) に保存できます Dang ブラウザを通じてサーバーにリクエストを送信すると、どのような情報が保存されますかリクエストには次の内容が含まれますか? Chrome の開発者ツールを使用して説明できます (使い方がわからない場合は、この記事の注意事項をお読みください)。
リクエスト メソッド: 最も一般的に使用されるリクエスト メソッドには、get リクエストと post リクエストが含まれます。開発における最も一般的な投稿リクエストは、ユーザーの観点からはログイン認証です。ログインするために何らかの情報を入力する必要がある場合、このリクエストはポストリクエストです。
url ユニフォーム リソース ロケーター: URL、画像、ビデオなどはすべて URL を使用して定義できます。 Web ページをリクエストすると、通常、最初のタグはドキュメントです。これは、このドキュメントが外部画像、CSS、JS などでレンダリングされない HTML コードであることを意味します。このドキュメントの下に表示されます。参照 一連のjpg、jsなどに対して、htmlコードに基づいてブラウザが何度もリクエストを行うもので、リクエストアドレスはhtml文書内の画像やjsなどのURLアドレスとなります
リクエストヘッダー: このリクエストのリクエストタイプ、Cookie情報、ブラウザタイプなどを含むリクエストヘッダー。 このリクエスト ヘッダーは、Web ページをクロールするときにも役立ちます。サーバーはリクエスト ヘッダーを解析して情報を確認し、リクエストが正当なリクエストであるかどうかを判断します。したがって、ブラウザを偽装するプログラムを通じてリクエストを行う場合、リクエストのヘッダー情報を設定できます。
リクエストボディ: 投稿リクエストは、送信用のフォームデータにユーザー情報をパッケージ化します。そのため、投稿リクエストのヘッダータグのコンテンツには、フォームなどのより多くの情報パケットが含まれます。データ。 get リクエストは単純に通常の検索のキャリッジリターンとして理解でき、URL の末尾に ? 間隔で情報が追加されます。
-
IV. 応答には何が含まれますか? -
応答ステータス: ヘッダーの一般からステータス コードを確認できます。 200 は成功、301 はジャンプ、404 は Web ページが見つからない、502 はサーバー エラーなどを示します。
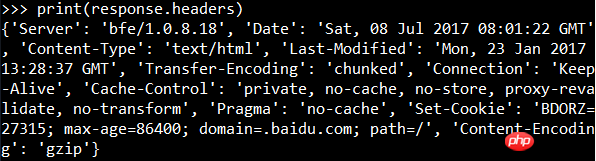
レスポンスヘッダー:コンテンツタイプ、Cookie情報などが含まれます。
レスポンスボディ: リクエストの目的は、HTML コード、Json、バイナリデータを含むレスポンスボディを取得することです。
5。つまり、リクエスト本文の内容です。応答ヘッダー情報を表示できます:
ステータスコードを表示します:

リクエスト情報にリクエストヘッダーを追加することもできます:
写真を撮る(Baidu ロゴ):

6. JavaScript レンダリングの問題を解決する方法
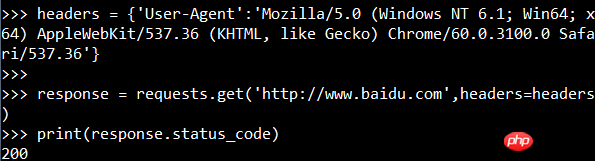
Selenium Webdriver を使用する

print(driver.page_) と入力します。出典)今回は、コードはその後コードをレンダリングしています。
【備考】Chromeブラウザ
 F12を使用して開発者ツールを開きます
F12を使用して開発者ツールを開きます
Elementsタグは要素の後ろにHTMLコードを表示します。
ネットワークタグ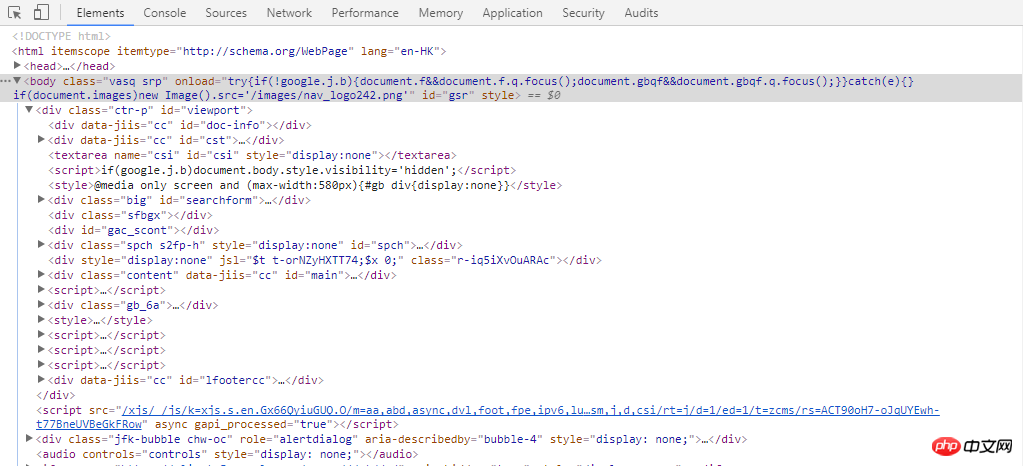
Networkタグの下にブラウザから要求されたデータがあり、クリックすると上記のリクエストヘッダーやレスポンスヘッダーなどの詳細情報が表示されます。
以上がクローラーとは何ですか?クローラーの基本的なプロセスは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。