
ホームページ >Java >&#&チュートリアル >同時実行性と可用性の高いアーキテクチャを構築する
同時実行性と可用性の高いアーキテクチャを構築する
- 巴扎黑オリジナル
- 2017-07-24 14:14:351926ブラウズ
この記事では、電子商取引プラットフォームにおけるアーキテクチャの実践をさまざまな角度から要約しています。時間の都合上、最初の草案が完成しており、今後追加され、改良される予定です。ぜひご連絡ください。
転載する場合は出典を明記してください:
著者: Yang Butao
分散アーキテクチャ、ビッグデータ、検索、オープンソーステクノロジーに焦点を当てる
QQ:306591368
テクノロジーブログ:
一、設計コンセプト
1. 時間のためのスペース
1) マルチレベルキャッシュ、静的
クライアントページキャッシュ (http ヘッダーには以下が含まれます) 有効期限切れ/コントロールのキャッシュ、最終更新日 (304、サーバーは body を返さない、クライアントは引き続き キャッシュを使用してトラフィックを削減できます )、ETag)
リバース プロキシ キャッシュ
アプリケーション側キャッシュ(memcache)
メモリ内データベース
バッファ、キャッシュメカニズム(データベース、ミドルウェアなど)
2)ハッシュ、B ツリー、反転、ビットマップ
ハッシュインデックスは、配列のアドレス指定とリンクリストの挿入特性を統合するのに適しており、データへの高速アクセスを実現できます。
B ツリー インデックスはクエリ指向のシナリオに適しており、複数のIO を回避し、クエリ効率を向上させます。
転置インデックスは、単語とドキュメントのマッピング関係の最適な実装と最も効果的なインデックス構造を実現し、検索分野で広く使用されています。
ビットマップは非常にシンプルで高速なデータ構造であり、(時間とスペースを交換することなく) ストレージ容量と速度を同時に最適化でき、大量のデータを使用するコンピューティングシナリオに適しています。2.
並列分散コンピューティング
1)
タスクの分割、分割統治(MR)
大規模データでは、データは特定の局所性の特性は、局所性の原理を使用して、大量のデータ計算の問題を分割および克服します。
MR モデルはシェアードナッシング アーキテクチャであり、データセットはさまざまなノードに分散されます。処理中、各ノードは、ローカルに保存されている処理用データを読み取り (マップ)、処理されたデータ をマージ (結合)、ソート (シャッフルとソート) を行った後、
を (reduce ノード に) 配布します。大量のデータを送信し、処理効率を向上させます。
2)マルチプロセス、マルチスレッド並列実行(MPP)
) は、複数のコンピューティング リソースを同時に使用することを指します。解決する問題を計算するプロセスは、コンピュータ システムの計算速度と処理能力を向上させる効果的な手段です。その基本的な考え方は、複数のプロセッサ /プロセス /スレッドを使用して同じ問題を共同で解決することです。つまり、解決される問題はいくつかの部分に分解され、各部分は独立したプロセッサによって並列計算されます。
と MR の違いは、データ分解ではなく問題分解に基づいていることです。 プラットフォームの同時実行性の増加に伴い、クラスタリングとロード バランシングを使用する。ロード バランシング デバイスは通常、ロード バランシングを提供すると同時に、可用性を向上させるために、ノード障害による可用性の問題を防ぐために災害復旧バックアップが必要です。オフライン バックアップでは、さまざまな無効要件に基づいてさまざまなバックアップ戦略を選択できます。 読み取りと書き込みの分離はデータベースに対するものであり、システムの同時実行性の増加に伴い、データ アクセスの可用性を向上させるための重要な手段は、書き込みデータと読み取りデータを分離することです。 . ; もちろん、読み取りと書き込みが分離されている間は、データの一貫性に注意を払う必要があります。分散システム CAP の定量化では、可用性により多くの注意が払われます。 プラットフォーム内のさまざまなモジュール間の関係は、可能であれば非同期に、関連するメッセージ コンポーネントを通じて相互作用でき、メイン プロセスを明確に区別する必要があります。セカンダリ プロセスでは、プライマリ プロセスとセカンダリ プロセスが非同期で動作するため、システム全体の可用性が向上します。 もちろん、非同期処理では、データが受信または処理されたことを確認するために、確認メカニズム (confirm、ack) が必要になることがよくあります。 ただし、一部のシナリオでは、リクエストは処理されましたが、他の理由 (不安定なネットワーク など) により確認メッセージが返されないことがあります。この場合、リクエストを再送信する必要があります。設計では、再送信要因による冪等性を考慮する必要があります。 4. システム リソースは常に制限されており、多数の同時操作の下で比較的長いビジネスが一度に実行される場合、このブロック方法では他のプロセスの実行に間に合うようにリソースを効果的に解放できません。高くない。 システムのスループットを向上させるには、ビジネスを論理的にセグメント化し、非同期でノンブロッキングな方法を使用する必要があります。 データ量と同時実行性が増加するにつれて、読み取りと書き込みの分離ではシステムの同時実行パフォーマンスの要件を満たすことができなくなり、データをデータベースとテーブルに分割するなど、データをセグメント化する必要があります。データベースとテーブルを分割するこの方法では、データのルーティング ロジック サポートを追加する必要があります。 2) システムの容量は限られており、アーキテクチャを設計するときに耐えられる同時実行の量も限られています。予期せぬ攻撃や瞬間的な同時実行の影響によるシステムのクラッシュを防ぐために、フロー制御を考慮する必要があります。フロー制御手段を追加するように設計する場合は、リクエストをキューに入れることを検討し、リクエストが予想される範囲を超えた場合にアラームを発行するか、リクエストを破棄できます。 共有リソースへのアクセスでは、競合を防ぐために、一部のトランザクションはトランザクションの一貫性を確保するために同時実行制御が必要です。システムを設計するときは、アトミック操作と同時実行制御を考慮する必要があります。 同時実行制御を確保するために一般的に使用される高パフォーマンスの手段には、オプティミスティック ロック、ラッチ、ミューテックス、コピーオンライト、CAS などが含まれます。MVCC は通常、次の重要な手段です。データベースで使用される一貫性の確保は、設計でよく使用されます。 プラットフォームにはさまざまな種類のビジネス ロジックがあり、計算が複雑なものもあれば、IO を消費するものもあります。同時に、同じ種類のビジネス ロジックが異なれば消費するリソースの量も異なり、ロジックごとに異なる戦略が必要になります。 IOタイプでは、シングルスレッド方式でスレッド切り替えによるオーバーヘッドを軽減でき、マルチスレッドの場合はスピン方式を採用できます。スレッド切り替え を削減し (Oracle ラッチ設計 など)、操作にはマルチスレッドを最大限に活用します。 同じタイプの呼び出し方法を使用して、異なる企業が適切なリソースを割り当て、異なる数の計算ノードまたはスレッドを設定し、業務を転用し、優先度の高いビジネスを優先します。 システムの一部のビジネスモジュールでエラーが発生した場合、同時実行下での通常のリクエストの処理への影響を軽減するために、場合によっては個別のチャネルを考慮する必要があります。これらの異常なリクエストに対しては、これらの異常なビジネス モジュールを処理するか、一時的に自動的に無効にします。 一部のリクエストの失敗は、偶発的な一時的な失敗 (ネットワークの不安定さなど) である可能性があり、リクエストの再試行を考慮する必要があります。 リソースを使用する場合、リクエストが正常なパスであっても異常なパスであっても、最後にリソースを解放する必要があります。他のリクエストで使用するためにリソースをタイムリーにリサイクルします。 通信アーキテクチャを設計するとき、多くの場合、タイムアウト制御を考慮する必要があります。 2. 静的アーキテクチャ ブループリント アーキテクチャ全体は、CDN と垂直方向の負荷分散を含む、階層化された分散アーキテクチャです。リバース プロキシ、Web アプリケーション、ビジネス レイヤー、基本サービス レイヤー、データ ストレージ レイヤー。水平方向には、プラットフォーム全体の構成管理、導入、監視が含まれます。 CDNシステムは、ネットワークトラフィックや各ノードの接続、負荷状況、ユーザーまでの距離、およびサービス ノードでの応答時間。その目的は、ユーザーが必要なコンテンツを近くで入手できるようにし、インターネット ネットワークの混雑を解決し、ユーザーが Web サイトにアクセスする際の応答速度を向上させることです。 大規模な電子商取引プラットフォームの場合、通常、ネットワーク高速化のために CDN を構築する必要があります。Taobao や JD.com などの大規模プラットフォームは、中小企業向けに独自に構築された CDN を使用します。サードパーティ CDN を使用して、Lan Xun、Wangsu、Kuaiwang などのメーカーと連携できます。 もちろん、CDNベンダーを選択するときは、ビジネスの長さ、スケーラブルな帯域幅リソース、柔軟なトラフィックと帯域幅の選択、安定したノード、および費用対効果があるかどうかを考慮する必要があります。 大規模なプラットフォームには多くのビジネスドメインが含まれており、異なるビジネスドメインには異なるクラスターがあります。DNSを使用してドメイン名解決を分散またはポーリングできます。その方法は簡単です。実装することはできますが、キャッシュの存在により柔軟性に欠けます。通常、商用ハードウェアF5、NetScaler、またはオープンソースのソフトロードlvsをベースにしており、4レイヤーで分散されます。使用 ( lvs+keepalived など) では、アクティブ モードとバックアップ モードを採用します。 4レイヤーがビジネスクラスターに配布された後、レイヤーで やHAProxyなどのwebサーバーを経由します7するロード バランシングまたはリバース エージェントは、クラスター内のアプリケーション ノードに分散されます。 どのタイプの負荷を選択するかについては、さまざまな要素 (高い同時実行性と高いパフォーマンスを満たしているかどうか、セッション保持を解決する方法、負荷分散アルゴリズムとは何か、圧縮のサポート、キャッシュのメモリ消費量); 以下は、一般的に使用されるいくつかの負荷分散ソフトウェアに基づいた紹介です。 は、 レイヤーで動作し、Linuxに実装された高性能、高同時実行性、スケーラブルで信頼性の高いロードバランサであり、複数の転送方法(NAT、DR、IP)をサポートしていますトンネリング)。DR モードは WAN 上の負荷分散をサポートします。デュアルマシンのホットスタンバイ(キープアライブまたはハートビート)をサポートします。ネットワーク環境への依存度は比較的高いです。 Nginx は、7 レイヤー、イベント駆動型、非同期、ノンブロッキング アーキテクチャで動作し、マルチプロセスの高同時実行ロード バランサー / リバース プロキシ ソフトウェアをサポートします。ドメイン名、ディレクトリ構造、および通常のルールに基づいて、http を転用することができます。 Web ページの処理時にサーバーから返されるステータス コードやタイムアウトなどの内部サーバー障害をポート経由で検出し、エラーを返すリクエストを別のノードに再送信します。ただし、欠点は url をサポートしていないことです。検出用。 session Stickyの場合、ip hashのアルゴリズムに基づいて実装でき、Cookieベースの拡張機能nginx-sticky-moduleを通じてsession Stickyをサポートします。 HAProxyは負荷分散のために4層と7層をサポートし、sessionセッション永続性をサポートします。 cookie サポート バックエンド url 検出方法; RR、重みなどを含む、負荷分散アルゴリズムが比較的充実しています。 画像の場合は、別のドメイン名、独立または分散画像サーバー、または mogileFS が必要です。画像サーバーの上に varnish を追加できます画像のキャッシュ用。 アプリケーション層はjbossまたはtomcatコンテナで実行され、フロントエンドショッピング、ユーザー独立サービス、バックエンドシステムなどの独立したシステムを表します。 プロトコルインターフェース、HTTP、JSON はservlet3.0、非同期サーブレット、を使用してシステム全体のスループットを向上させることができます httpリクエストN ginxを通過し、負荷分散アルゴリズムを通じてAppの特定のノードに割り当てられます。この層を拡張するのは比較的簡単です。 Cookieを使用して少量のユーザーの部分情報を保存することに加えて、Appアクセス層用に、ユーザー関連の情報(Cookieは通常4Kのサイズを超えることはできません) セッションデータは保存されますが、一部のリバースプロキシまたはロードバランシングはセッションスティッキーをサポートしていないか、比較的高いアクセス可用性要件を持っています(アプリアクセスノードがダウンしている、セッションが失われた)、これは必要ですセッションの集中ストレージを検討して、Appアクセス層をステートレスにすると同時に、システムユーザーの数が増加した場合、アプリケーションノードを追加することで水平方向の拡張を実現できます。 Session一元化ストレージは、次の要件を満たす必要があります。 a、効率的な通信プロトコル b、session分散キャッシュ、ノードのスケーリング、データ冗長バックアップおよびデータ移行をサポート c、session有効期限管理 は、電子商取引の場合、ユーザー、商品、注文、赤い封筒、支払いサービスなどのサービスを表します。これらの異なるフィールドは、異なるサービスを提供します。モジュールを構成するためには、適切なモジュール分割とインターフェイス設計が非常に重要です。これにより、システム全体の可用性が向上します。もちろん、アプリケーションのサイズに応じてモジュールをまとめてデプロイすることもできますが、大規模なアプリケーションの場合は、通常は個別にデプロイされます。 高い同時実行性: ビジネス層の外部プロトコルは の で公開されており、netty、minaなどのより成熟したNIO通信フレームワークを使用できます 可用性: モジュール サービスの可用性を向上させるために、モジュールは冗長性を確保するために複数のノードにデプロイされ、ロード転送とフェイルオーバーを自動的に実行します VIP+ハートビート メソッドを使用できます。 、システムには1つの個別のコンポーネントがありますhha、 (元のソリューションに対する利点)を達成します。可用性と一貫性は、最終的に一貫した状態を達成するための校正を通じて実現できます。 5. 基本サービスミドルウェア 1) 通信コンポーネント 通信コンポーネントは、大規模な同時実行性の電子商取引プラットフォームで、高い同時実行性の要件を満たす必要があります。高スループット。 通信コンポーネント全体には、クライアントとサーバーの 2 つの部分が含まれます。 クライアントとサーバーは長い接続を維持するため、各リクエストの接続を確立するコストを削減できます。接続が初期化された後、サーバーは rpc を実行するために同時に接続できます。接続プール内の長い接続には、ハートビートのメンテナンスとリクエストのタイムアウト設定が必要です。 長い接続の維持プロセスは 2 つの段階に分けることができます。1 つはリクエストを送信するプロセスで、もう 1 つは応答を受信するプロセスです。リクエストの送信プロセス中に IOException を送信し続けます( pingInterval ping ( を意味します。現在の接続に問題がある場合は、現在の接続を無効としてマークします。ping が成功した場合は、現在の接続が信頼できることを意味し、読み取りを続行します。無効な接続は接続プールから削除されます。 各接続は応答を受信するために別のスレッドで実行され、クライアントはそれを同期的に行うことができます (wait,notify) またはを同時に作るrpc呼び出し、シリアル化は、より効率的なhessionシリアル化メソッドを採用します。 サーバーは、イベント駆動型の NIO の MINA フレームワークを使用して、高い同時実行性と高スループットのリクエストをサポートします。 ほとんどのデータベースシャーディングソリューションでは、データベースのスループットを向上させるために、最初のステップは、データベース内の異なるテーブルを垂直に分割することです。 次に、データベース内のテーブルが特定のサイズを超えると、テーブルを水平に分割する必要があります。ここでは、データベースにアクセスするクライアントの場合も同様です。ユーザーの に基づいて、アクセスする必要のあるデータを見つけます。データセグメント化アルゴリズム、 はユーザーの 、一貫性ハッシュに基づいてハッシュ操作を実行します。このメソッドには問題があります。無効なデータの移行中、移行期間中はサービスが利用できません ユーザーと 間のマッピング関係を保存するルーティングテーブルを維持し、シャーディングはリーダーとレプリカに分割されます。 、それぞれ書き込みと読み取りを担当します このように、各 クライアントはすべての シャーディング 接続プールを維持する必要があります。これには、完全な接続が発生するという欠点があります。問題; 解決策 のシャーディングはビジネスサービス層で行われ、各ビジネスノードは1つのシャード接続のみを維持します。 画像を参照してください( ) ルーティングコンポーネントの実装は次のようになります(可用性、高パフォーマンス、高同時実行性) パフォーマンスの考慮事項に基づいて、 ユーザー id と shard の間の関係を維持し、可用性を確保するには、replicatset クラスターを構築します。 biz shardingとデータベースのshardingは1対1対応しており、1つのデータベースshardingのみにアクセスします。 ビジネス 動物園管理人up/bizs/shard/down。 router /bizs/上のzookeeperを監視し、routerのオンラインbizをキャッシュします。 clientがrouterにbizの取得をリクエストすると、routerはまずユーザーの対応するシャードをmongodbから取得し、routerはキャッシュされたコンテンツに基づいてRRアルゴリズムを通じてbizノードを取得します。 ルーターの可用性と同時実行スループットの問題を解決するために、ルーターを冗長化し、同時にクライアント聞いてください動物園の飼育員の/ルーターオンラインのノードとキャッシュルーターノードのリスト。 HAを実装する従来の方法は、一般に仮想IPドリフトをハートビートと組み合わせて使用することです、キープアライブ、その他実装HA、 Keepalivedは、vrrpを使用してデータパケットを転送し、4レイヤーの負荷分散を提供し、vrrpを検出して切り替えます、冗長ホットバックアップを提供します。 LVSと合わせるのに適しています。 linux Heartbeat は、ネットワークまたはホストに基づく高可用性サービスです。HAProxy または Nginx は、7 レイヤーに基づいてデータ パケットを転送できるため、Heatbeat は HAProxy、Nginx に適しています。 、高いビジネス可用性を含む。 ハッシュアルゴリズムまたはroudrobinを使用して負荷分散を実現します。マスター-マスターモードおよびマスター-スレーブモードの場合は、zookeeper分散ロックメカニズムを通じてサポートできます。 4) メッセージメッセージ メッセージ サービス コンポーネントを設計するときは、メッセージの一貫性、永続性、可用性、および完全な監視システムを考慮する必要があります。 RabbitMQ kafka、 RabbitMQはAMQPプロトコルに従い、本質的に同時実行性の高いerlanng言語によって開発されており、Linkedinは201012月にオープンソースのメッセージ公開およびサブスクリプションシステム、 主にアクティブ ストリーミング データ、大量のデータのデータ処理の処理に使用されます。 応答確認メカニズムは、メッセージの生成および消費のプロセスを含め、メッセージの一貫性が比較的高い状況で必要となります。その他の原則 欠如するとメッセージの重複が発生する可能性がありますが、これはビジネス レベルで冪等性に基づいて判断およびフィルタリングできます。 はこの方法を採用しています。また、コンシューマが broker からメッセージをプルするときに LSN 番号を持ち込んで、broker の特定の LSN ポイントからメッセージをバッチでプルするメカニズムもあります。そのため、応答メカニズムは必要ありません、kafkaは配信メッセージの途中です。 このように動作します。 メッセージの信頼性要件とパフォーマンスの包括的な測定に基づいて、 でのメッセージのストレージは、メモリ内に保存することも、ストレージに永続化することもできます。 可用性と高スループットの要件のために、クラスター モードとアクティブ/スタンバイ モードの両方を実際のシナリオに適用できます。 ソリューションには、通常のクラスターと高可用性の ミラーキュー メソッドが含まれています。 kafka は、zookeeper を使用してクラスター内の broker と consumer を管理します。zookeeper の調整メカニズムを通じて topic を zookeeper に登録できます。 トピック 情報は、ランダムまたはポーリング方式で broker に送信でき、Producer はセマンティクスに基づいてシャードを指定でき、メッセージは broker の特定のシャードに送信できます。 一般的に、RabbitMQ は比較的高い信頼性が必要なリアルタイム メッセージングに使用されます。 kafka は主にアクティブなストリーミング データ と大量のデータのデータ処理の処理に使用されます。 5) キャッシュとバッファ システム 一部の高同時実行性および高パフォーマンスのシナリオでは、キャッシュを使用するとバックエンドシステムの負荷を軽減でき、通常、データベース ストレージの前に cache キャッシュを追加するなど、圧力をかけることでシステムのスループットが大幅に向上します。 しかし、キャッシュアーキテクチャの導入は、キャッシュヒット率の問題、キャッシュの失敗によって引き起こされるジッター、キャッシュ、ストレージの一貫性など、いくつかの問題を必然的に引き起こします。 キャッシュのデータは、ストレージと比較して結局のところ制限されており、ストレージシステムのホットデータは、いくつかの一般的なアルゴリズムLRUなどを使用することで排除できます。データ; システム規模が大きくなると、単一ノード キャッシュ では要件を満たすことができなくなるため、単一ノードの障害によって引き起こされるジッターを解決するために、分散 キャッシュ を構築する必要があります。一貫性 ハッシュ を使用します。このソリューションは、単一ノードの障害によって引き起こされるジッター範囲を大幅に削減します。また、比較的高い可用性要件が必要なシナリオでは、各ノードをバックアップする必要があります。データはキャッシュとストレージの両方に同じバックアップがあるため、整合性の問題が発生するはずです。整合性が比較的強い場合は、データベースキャッシュを同時に更新します。整合性要件が低い場合は、キャッシュの有効期限ポリシーを設定できます。 Memcached libeventのイベント処理メカニズムに基づいています。 キャッシュシステムは、プラットフォームの システムのクライアントで使用され、データアクセスが失敗すると、ルーターシステムにアクセスされます。 現在、キャッシュ Redis、mongodbなどのより多くのインメモリデータベースが使用されており、redisはmemcacheAPIよりも豊富なデータ操作を備えています。 ; レディス と mongodb は両方ともデータを永続化しますが、memcache にはこの機能がないため、memcache はリレーショナル データベース上のデータのキャッシュに適しています。 バッファ 高速書き込み操作シナリオで使用され、プラットフォーム内の一部のデータを書き込む必要がありますデータはデータベースとテーブルに分割されますが、データの信頼性はそれほど高くありません。データベースへの書き込み負荷を軽減するために、バッチ書き込み操作を採用できます。 lucene と sphinx が含まれますが、どちらの検索エンジンが優れているかについてはここでは説明しません。ただし、検索エンジンを選択する際には、基本的な機能に加えて、次の 2 つがサポートされている必要があります。非機能的な側面を考慮する必要があります: a. 検索エンジンは、大量のデータに対応するための分散インデックス作成と検索をサポートし、読み取りと書き込みの分離をサポートし、可用性を向上させますか? Solr は、lucene に基づいた高性能の全文検索サーバーです。lucene よりも豊富なクエリ言語を提供し、構成可能で拡張可能であり、 に基づいた XML/JSON 形式の外部インターフェイスを提供します。 http プロトコル。 Solr4バージョン以降、分散インデックス作成をサポートし、各シャーディングを通じてシャーディングデータシャーディングを自動的に実行するためのSolrCloudメソッドが提供されています。 マスタースレーブ(リーダー、レプリカ) モードは、検索パフォーマンスを向上させます。zookeeper を使用して、リーダー の選択などを含むクラスターの可用性を確保します。 Luceneインデックス付きのReaderはインデックスsnapshotに基づいているため、インデックスに含まれている必要がありますコミット 後、新しいものを再度開きます スナップショットを作成することによってのみ、新しく追加されたコンテンツを検索できます。また、インデックス作成コミットはパフォーマンスに非常に負荷がかかるため、リアルタイムのインデックス検索の効率は比較的低くなります。 インデックス検索のリアルタイムパフォーマンスについて、Solr4の以前のソリューションは、完全なファイルインデックス作成とメモリ増分インデックスマージを組み合わせることでした。以下の図を参照してください。 Solr4 は、NRT ソフトコミット のソリューションを提供し、インデックス操作を送信せずにインデックスへの最新の変更を検索できますが、インデックスへの変更は 同期コミット ではありません。何らかの事故が発生してプログラムが異常終了した場合、コミットしていないデータは失われるため、定期的にコミット操作を行う必要があります。 プラットフォーム内のデータのインデックス作成とストレージ操作は非同期であるため、可用性とスループットが大幅に向上します。インデックス操作のみが特定の属性フィールドに対して実行され、データの識別は行われません。 storagekey Hbase に保存されます。検索統計。 インデックスデータとHBaseデータストレージの一貫性、つまり、HBaseに格納されているデータがインデックス付けされていることを確認する方法については、confirm 7) ログ収集 ログ システムには、エージェント (データ ソースをカプセル化し、データ ソース内のデータをコレクターに送信する)、コレクター (複数のエージェントからデータを受信し、それを要約する) という 3 つの基本コンポーネントが必要です。バックエンドの store)、store (中央ストレージ システムはスケーラブルで信頼性が高く、現在非常に人気のある HDFS をサポートする必要があります)。 業界で最も一般的に使用されているオープンソースログ収集システムは、clouderaのFlumeとfacebookのSですクリベ、その中に Flume現在のバージョンFlumeNGは、Flumeに大幅なアーキテクチャ変更を加えました。 ログ収集システムを設計または技術的に選択する場合、通常は次の特性が必要です。 a アプリケーション システムと分析システムは両者の関係が分離されており b、分散型かつスケーラブルで拡張性が高く、データ量が増えた場合はノードを追加することで水平拡張可能 ログ収集システムはスケーラブルで全く問題なく利用可能です。システムのレベルがスケーラブルで、データ処理には状態が必要なく、スケーラビリティを比較的簡単に実現できます。 c、ほぼリアルタイム 高い適時性要件がある一部のシナリオでは、データ分析に間に合うようにログを収集する必要があります 一般的なログ ファイルは定期的または定量的にローリングされるため、リアルタイム検出ログを生成します。ファイルを処理し、ログ ファイルに対して同様の tail 操作をタイムリーに実行し、送信効率を向上させるためにバッチ送信をサポートします。バッチ送信のタイミングは、メッセージ数と時間間隔の要件を満たす必要があります。 d、フォールトトレランス Scribe クラッシュが発生したときに、ストレージシステムが正常に戻ったときにscribeがデータをローカルディスクに書き込むことです。 , scribeログをストレージ システムにリロードします。 FlumeNG シンクプロセッサを通じて負荷分散とフェイルオーバーを実現します。複数の シンク が シンク グループ を形成できます。 シンク プロセッサは、指定された シンク グループから シンクをアクティブ化する責任があります。 シンク プロセッサ は、グループ内のすべての シンク を通じて負荷分散を実現できます。また、1 つの シンク に障害が発生した場合に、別のシンク に転送することもできます。 はトランザクションサポートを考慮していません。 は、応答確認メカニズムを通じてトランザクションサポートを実現します。下の図を参照してください。 FlumeNG の チャンネル は、さまざまな信頼性要件に基づいたメモリとファイルの永続化メカニズムに基づくことができますが、メモリベースのデータ送信はより高い売上をもたらしますが、ノードがダウンすると、ファイル中にデータが失われ、復元できなくなります。永続性 ダウンタイムを回復できます。 g、定期的かつ定量的なデータのアーカイブ データは、ログ収集システムによって収集された後、その後の処理と分析を容易にするために、通常、Hadoopなどの分散ファイル システムに保存されます。データ、タイミング(TimeTrigger)または定量的(SizeTriggerの分散システムのローリングファイル。 取引システムでは、通常必要です異種データ ソースを同期するには、通常、データ ファイルとリレーショナル データベース、データ ファイルと分散データベース、リレーショナル データベースと分散データベースなどが存在します。異種ソース間のデータの同期は、通常、パフォーマンスとビジネス ニーズに基づいて行われます。ファイルは順次に保存されるため、一般に、リレーショナル データへのデータ同期は効率が高くなります。クエリ要件。分散データベースはますます大量のデータを保存しますが、リレーショナル データベースは大規模なデータ ストレージとクエリ要求に対応できません。 データ同期の設計では、スループット、耐障害性、信頼性、一貫性の問題を総合的に考慮する必要があります。 同期は、リアルタイム増分データ同期とオフライン完全データ同期に分けて紹介します。二次元、 リアルタイム増分は通常、ファイルの変更をリアルタイムで追跡するための Tail ファイルであり、バッチまたはマルチスレッドでデータベースにエクスポートされます 、 このメソッドのアーキテクチャはログ収集フレームワークに似ています。この方法には、2 つの側面を含む確認メカニズムが必要です。 1つの側面は、Channelがデータレコードをバッチで受信したことをagentに確認し、LSN番号をagentに送信する必要があるということです。これにより、agentが失敗して回復したときに、これを使用できます LSN 開始 tail をクリックします。 もちろん、少量の重複レコードを許可する問題については (channel が agent に確認するときに、agent がダウンし、確認メッセージ)、ビジネスシナリオジャッジに含まれる必要があります。 チャンネルへの同期ですデータベースへの一括書き込みが完了したことを確認しますので、channel 確認されたメッセージのこの部分は削除できます。 信頼性要件に基づいて、 はファイルの永続性を使用できます。 下の写真を参照してください MySQLなどのソースデータを分割し、複数のスレッドでソースデータを同時読み込み、HBaseなどの複数のスレッドでソースデータを一括で同時に書き込む必要があります読み込み間のバッファとしてchannelを使用します。より良いデカップリングを実現するための書き込みでは、チャンネルをファイル ストレージまたはメモリに基づいて行うことができます。下の図を参照してください: (たとえば、その日の注文データを早朝に HBase に同期する) ため、セグメント化する必要があります行数( )に応じたデータ、マルチスレッドはテーブル全体をスキャンします (時間内にインデックスを構築し、テーブルを返す必要もあります)、大量のデータ、IOは非常に高く、効率は非常に低いです。これが解決策です。時間フィールドに従ってデータベースのパーティションを作成し、時間に従って同期します、そしてそれぞれのパーティションに従ってエクスポートします。時間。 9) データ分析 トラフィック統計、推奨エンジン、トレンド分析、ユーザー行動分析、データマイニング分類器、分散インデックスなどなどを含む大規模な電子商取引ウェブサイトで広く使用されています。 商用のEMC Greenplum Greenplumのアーキテクチャは、大規模データストレージ用のpostgresqlに基づく分散データベースであるMPP (Massively Parallel Processing)を採用しています。 インメモリコンピューティングに関しては、SAP HANAがあり、オープンソースのnosqlメモリデータベースmongodbもサポートしていますデータの mapreduce分析。 膨大なデータのオフライン分析は現在、インターネット企業 Hadoop にはスケーラビリティ、堅牢性、コンピューティングパフォーマンス、コストの面でかけがえのない利点があることは事実です。現在のインターネット企業の主流となっている分析プラットフォームHadoopは、 という分散処理フレームワークを通じて大規模なデータを処理するために使用されており、拡張性も非常に優れています。 MapReduceの欠点 リアルタイム要件を満たすことができないシナリオであり、主にオフライン分析に使用されます。 データ分析用のMapRduceモデルプログラミングに基づいて、hadoopの上に位置するHiveの出現により、sqlを記述するのと同様のデータ分析が行われます。実行計画を生成すると、最終的にMapReduceタスクが生成されて実行されるため、開発効率が大幅に向上し、アドホック(クエリ発生時の計算)メソッドでの分析が可能になります。 モデルに基づく分散データの分析はすべてオフライン分析であり、実行はすべてブルートフォーススキャンであり、メカニズムオープンソースの Cloudera Impala は MPP 並列プログラミング モデルに基づいており、基礎となるレイヤーは Hadoop に保存されており、データの遅延を大幅に削減できます。分析。 で現在使用されているバージョンはHadoop1.0ですが、一方で、元のMapReduceフレームワークにはJobTrackerに関する単一の問題があります。 、リソース管理を行うJobTrackerはタスクのスケジューリングも実行します。データ量とJobタスクが増加すると、スケーラビリティ、メモリ消費量、スレッドモデル、信頼性、パフォーマンスに明らかなボトルネックが生じます。フレームワークでは、リソース管理とタスクのスケジューリングを分離し、アーキテクチャ設計からこの問題を解決しました。 10) リアルタイムコンピューティング インターネット分野では、リアルタイムコンピューティングが広く使用されています。監視と分析、フロー制御、リスク制御などの分野。電子商取引プラットフォームのシステムやアプリケーションは、毎日生成される大量のログや異常情報をリアルタイムでフィルタリングして分析し、早期警告が必要かどうかを判断する必要があります同時に、自己警告を実装する必要があります。 - システムへの過度の圧力によって引き起こされる予期せぬシステム麻痺を防ぐためのモジュールのフロー制御など、システムの保護メカニズム。トラフィックが大きすぎる場合、一部のビジネスではリスク制御が必要になります。たとえば、宝くじの一部の企業は、システムのリアルタイムの売上に基づいて番号を制限し、番号を割り当てる必要があります。 元の計算は単一ノードに基づいていました。システム情報の爆発的な生成と計算の複雑さの増加により、単一ノードの計算ではマルチノード分散計算の要件を満たすことができなくなりました。分散型リアルタイムコンピューティングプラットフォームが登場しました。 ここで言及されているリアルタイム コンピューティングは、実際にはストリーム コンピューティングです。この概念の前身は、Esper などの関連オープン ソース製品、Yahoo S4、Twitter storm、などです。 stormオープンソース製品が最も広く使用されています。 リアルタイム コンピューティング プラットフォームでは、アーキテクチャ設計の観点から次の要素を考慮する必要があります。 2. 高パフォーマンス、低遅延 コンピューティング プラットフォームに流入するデータから出力結果の計算まで、メッセージが迅速に処理され、リアルタイムの計算を実現するには、効率的なパフォーマンスと低遅延が必要です。 3. 信頼性 各データ メッセージが 1 回完全に処理されることを確認します。 4. 耐障害性 システムは、アプリケーションに対して透過的にノードのダウンタイムと障害を自動的に管理できます。 Twitter の Storm は、上記の点で優れています。 Storm のアーキテクチャを簡単に紹介します。 クラスター全体は zookeeper を通じて管理されます。 クライアントはトポロジーをnimbusに送信します。 Nimbusこのトポロジーのローカルディレクトリを確立し、トポロジーの構成に従ってタスクを計算し、タスクを割り当て、割り当てノードストレージタスクとスーパーバイザーを確立します動物園の飼育員ノード内のworkerのマシン対応。 zooke eper上にtaskbeatsノードを作成しますタスクハートビートトポロジを開始します。 Supervisorはzookeeperに移動して、割り当てられたタスクを取得し、複数のworkerを開始して続行し、各workerがタスクを生成します、1 つの タスク 1 つのスレッド; task 間の接続 は、topology 情報の初期化に基づいて確立されます。Task と Task は、 の後に zeroMQ を通じて管理されます。 はストリームの基本的な処理単位であり、メッセージです。Tupleはその中にあります。 タスクの転送における、Tupleの送受信プロセスは次のとおりです: Tupleを送信するには、Workerがtransfer関数を提供します現在のタスクタプルを転送するには他のタスクに送信します。目的のtaskidとtupleパラメータを使用して、tupleデータをシリアル化し、転送キューに入れます。 バージョン 0.8 より前は、この queue は LinkedBlockingQueue であり、0.8 以降は DisruptorQueue でした。 バージョン0.8以降、各ワーカーはインバウンド転送キューとアウトボンドキューにバインドされます。バインドされたキューはメッセージを受信するために使用されます 、 outbond queue はメッセージの送信に使用されます。メッセージを送信するとき、単一のスレッドが transferqueue からデータを取得し、この tuple を zeroMQ に渡します。 他の従業員中間者に送信。 はTupleを受信し、すべてのworkerはメッセージを受信するためにzeroMQのtcpポートをリッスンし、メッセージはDisruptorQueue中盤以降、 after from queue からmessage(taskid,tuple)を取得し、目的taskid,tuple taskにルーティングします。各タプルは、ダイレクトストリームに送信することも、Stream GroupによってReglularモードで通常ストリームに送信することもできます(ストリームID-->コンポーネントID-->アウトボンド) task) 関数は、送信される現在の タプル の宛先を完成させます。 上記の分析からわかるように、 Storm は、スケーラビリティ、耐障害性、および高性能の観点からアーキテクチャ設計の観点からサポートされており、同時に信頼性の観点からも、Storm の ack コンポーネントは XOR xor アルゴリズムを使用しています。メッセージが常に完全に処理されるようにするため。 システム監視ダイナミクスのリアルタイム曲線描画、携帯電話メッセージのプッシュなど、リアルタイムプッシュには多くのアプリケーションシナリオがあります webリアルタイムチャットなどリアルタイムプッシュを実現するには、Cometメソッド、websocketメソッドなどを含む多くのテクノロジーがあります。 Comet「サーバー プッシュ」テクノロジーは、2 つのタイプを含む長いサーバー接続に基づいています: ロング ポーリング: サーバーはリクエストを受信した後にハングし、更新があると接続が返されて切断され、その後、クライアントは新しい接続を開始します Streamメソッド: サーバーデータが送信されるたびに接続は閉じられません。接続は、通信エラーが発生した場合、または接続が再確立された場合にのみ閉じられます(一部のファイアウォールは、多くの場合、サーバーは過度に長い接続を破棄するように設定されています。クライアントはタイムアウト期間を設定でき、タイムアウト後、クライアントは接続を再確立して元の接続を閉じるように通知されます。 Websocket: 長時間接続、全二重通信 はHTML5の新しいプロトコルです。ブラウザとサーバー間の双方向通信を実装します。 webSocket API では、ブラウザーとサーバーはハンドシェイク アクションのみを必要とし、ブラウザーとクライアントの間に高速双方向チャネルを形成するため、データを両方向に迅速に送信できます。 Socket.io は、リアルタイム web アプリケーションを迅速に構築するために使用される、クライアント側 js とサーバー側 nodejs を含む NodeJS Websocket ライブラリです。 追加予定 データベースストレージは、 Oracle にリレーショナル (トランザクション) データベースを含めて、次のカテゴリに大別されます。 、mysqlが表され、redisとmemcached dbで表されるkeyvalueデータベースがあり、mongodbなどのドキュメントデータベース、HBase、cassandraなどのカラム型分散データベースがあります。 dynamo、他にもグラフデータベース、オブジェクトデータベース、xmlデータベースなどがあります。データベース アプリケーションの種類ごとにビジネス分野が異なります。以下では、関連製品のパフォーマンス、可用性などをメモリ、リレーショナル、分散の 3 つの側面から分析します。 高い同時実行性と高いパフォーマンスを目指しており、トランザクション性の点ではそれほど厳密ではありません、そしてオープンソースのnosqlデータベースmongodb、redisたとえば Ø Mongodb マルチスレッドメソッド、メインスレッドは新しい接続を監視します、そして接続後、データ操作 (IO データ構造 -->collection-->record MongoDBは、データストレージ上の名前空間によって分割されており、 は名前空間です。インデックスも名前空間です。 同じ名前空間内のデータは多数のエクステント エクステントは二重リンクリストを使用して接続されます。 各エクステント 各行のデータストレージスペースには、データが占有しているスペースだけでなく、データ更新が大きくなった後に位置を移動できない追加スペースの一部も含まれる場合があります。 インデックスはBTree構造に実装されています。 jorunalingログを有効にすると、すべての操作記録を保存するファイルもいくつか存在します。 永続ストレージ MMapメソッドは、write、readオペレーションを呼び出すことなく、メモリアドレス空間を直接操作することでファイルを操作できます。高い。 mongodb は mmap を呼び出してディスク内のデータをメモリにマッピングするため、信頼性を確保するためにデータを常にハードディスクにフラッシュするメカニズムが必要です。フラッシュする頻度は、 同期遅延パラメータ。 ジャーナル(リカバリに使用)はMongodbのredoログであり、Oplogはレプリケーションbinlogを担当します。 journal がオンになっている場合、電源が切れても、失われるデータは 100ms だけであり、ほとんどのアプリケーションでは許容可能です。 1.9.2+ 以降、mongodb はデータのセキュリティを確保するためにデフォルトで journal 機能をオンにします。さらに、journalの更新時間は2-300msの範囲内で変更できます。--journalCommitIntervalコマンドを使用します。 Oplogとデータがディスクに更新されるまでの時間は60秒です。レプリケーションの場合、oplogがディスクを更新するのを待つ必要はなく、メモリ内のSencondaryノードに直接コピーできます。 。 Mongodb クラスター のアトミック操作がより一般的に使用されます は、可用性を確保しながら、リーダー の選出を自動的に実行する選出アルゴリズムを使用し、強力な一貫性要件となる可能性があります。 もちろん、大量のデータに対して、 はデータ シャーディング アーキテクチャ Sharding も提供します。 Ø Redis 豊富なデータ構造、高速な応答速度、メモリ操作 すべての演算がメモリ内にあるため、論理演算が非常に高速で、 を削減します切り替えオーバーヘッドがないため、シングルスレッド モードになります (論理処理スレッドとメイン スレッドが 1 つです)。 actorモード、独自の多重化NIOメカニズムを実装(epoll、select、kqueueなど) マルチタスク データ構造 hash+bucket構造、リンクリストの長さが長すぎる場合、移行措置が取られます(元のハッシュテーブルを2倍に拡張し、そこにデータを移行、expand+rehash) 永続ストレージ a、完全な永続性RDB (redisDBの読み取り、バケットの読み取り) )、save コマンドはメインスレッドをブロックします。 bgsaveサブプロセスを開始して、snapshot永続化操作を実行し、rdbファイルを生成します。 すると、保存操作が行われますと呼ばれるデータが変更されると、何秒になりますか sync、 はslavebからのコマンドを受け入れます、インクリメンタル永続性( はredologに似ています) )、最初にログバッファに書き込みます, その後、ログ ファイルに flush を書き込みます (flush の戦略は、単一またはバッチでのみ設定できます)、ファイルへの flush のみが実際にクライアントに返されます。 aof rdbファイルは定期的にマージする必要があります(スナップショットプロセス中、変更されたデータは最初にaof bufに書き込まれ、子供処理が完了します スナップショット<memorysnapshot>を取得した後、aofbufの変更部分と完全なイメージデータをマージします)。 RDBよりもサービスのパフォーマンス指標に明らかなジッターを引き起こします。メモリに再ロードする時間はデータ量に比例します。 クラスター 一般的な解決策は、HA ソフトウェアを使用したマスター/スレーブ バックアップの切り替えです。これにより、障害が発生したマスター redis をスレーブ redis にすぐに切り替えることができます。マスターとスレーブのデータ同期にはレプリケーション メカニズムが採用されており、このシナリオでは読み取りと書き込みを分離できます。 現在、レプリケーションに関しては、ネットワークが不安定な場合、SlaveとMasterが切断され(フラッシュ中断を含む)、Masterの転送が必要になるという問題があります。メモリ rdb ファイル (スナップショット ファイル) 内のすべてのデータが再生成され、その後 Slave に転送されます。 Slaveは、Masterから渡されたrdbファイルを受信すると、自身のメモリをクリアし、rdbファイルをメモリに再ロードします。この方法は比較的非効率的ですが、将来のバージョン Redis2.8 では、作成者はコピー機能の一部を実装しました。 mysqlデータベースを説明する例を挙げてください。アーキテクチャ設計の原則、パフォーマンスに関する考慮事項、可用性要件を満たす方法。 Ø mysql(innodb) のアーキテクチャ原理 アーキテクチャの観点から見ると、mysqlはserver層とストレージエンジン層に分かれています。 サーバーサーバー層のアーキテクチャは、接続/スレッド処理、クエリ処理(パーサー、オプティマイザー)やその他のシステムタスクを含む、異なるストレージエンジンでも同じです。 mysql はストレージ エンジンのプラグイン構造を提供し、最も広く使用されているのは innodb と myisamin です。アプリケーション 、トランザクション処理をサポートしますが、myisamはトランザクション、テーブルロックをサポートしませんが、OLAPの動作速度が高速です。 以下では主にinnodbストレージエンジンを紹介します。
スレッド処理の観点から見ると、Mysqlはマルチスレッドアーキテクチャであり、マスタースレッド、ロック監視スレッド、エラー監視スレッド、および複数のIOスレッドで構成されています。そして、接続を提供するためにスレッドが開かれます。 ioスレッドは、ランダムなIOを保存する挿入バッファ、トランザクション制御用のoracleと同様のやり直しログ、および複数のwrite、複数のreadハードディスクとメモリを交換するIOスレッドに分割されます。 。メモリ割り当てに関しては、innodb バッファ プール、およびログ バッファが含まれます。その中で、innodb バッファー プール には、挿入バッファー、データページ、インデックス ページ、データ ディクショナリ、およびアダプティブ ハッシュ が含まれています。 ログ バッファは、パフォーマンスを向上させるためにトランザクション ログをキャッシュするために使用されます。 データ構造の観点から見ると、innodbにはテーブルスペース、セグメント、リージョン、ページ/ブロック、行が含まれます。インデックス構造は、セカンダリインデックスと主キーインデックスを含むB+tree構造であり、セカンダリインデックスのリーフノードは主キーPKであり、主キーに従ってインデックス付けされたリーフノードは、保存されたデータブロック。この B+ ツリー ストレージ構造は、ランダム クエリ操作 IO の要件をより適切に満たすことができます。データ ページとセカンダリ インデックス ページの変更には、書き込み中のパフォーマンスを向上させるために が含まれます。挿入バッファ が順次書き込みを実行すると、バックグラウンド スレッドが複数の挿入を特定の頻度でセカンダリ インデックス ページにマージします。データベース(メモリおよびハードディスクのデータファイル)の一貫性を確保し、インスタンスの回復時間を短縮するために、リレーショナルデータベースには、以前のダーティページを変換するために使用されるチェックポイント関数もあります。 (old の比率に従ってメモリバッファがディスクに書き込まれるため、障害から回復するときにredologファイルのLSN以前のログが上書きされ、リサイクルされます。ログから LSN をクリックするだけで復元できます。 トランザクション機能のサポートに関して、リレーショナル データベースは ACID 4 つの機能を満たす必要があり、さまざまなトランザクションの同時実行性とデータ可視性の要件に基づいて、さまざまなトランザクション分離レベルを定義する必要があり、それらはリソース競合のためのロック メカニズムと切り離すことができません。デッドロックを回避するために、mysqlはサーバー層とストレージエンジン層で同時実行制御を実行し、主に読み取り/書き込みロックに反映されます。ロックの粒度に応じて、さまざまなレベルのロック(テーブルロック、行ロック、 page locks Lock, MVCC); 同時実行パフォーマンスの向上を考慮して、トランザクションの分離をサポートするためにマルチバージョン同時実行制御 MVCC が使用され、トランザクションのロールバックを行う場合は undo に基づいて実装されます。も中古パーツになります。 mysql redolog を使用して、データの書き込みと障害回復のパフォーマンスを確保します。データを変更する場合は、メモリを変更するだけで済み、変更動作をトランザクション ログ (シーケンシャル IO) に記録します。毎回データを変更する必要がある データ変更自体はハードディスク(ランダムIO)に保持されるため、パフォーマンスが大幅に向上します。で信頼性の観点から、innodb ストレージ エンジンは 2 回書き込みメカニズムを提供しますdoubleライター ページをストレージにフラッシュする際のエラーを防ぎ、ディスク 半分ライター の問題を解決するために使用されます。 Ø 高い同時実行性と高いパフォーマンス mysql のために、パフォーマンスのチューニングを多次元で実行できます。 a、ハードウェアレベル、ログとデータストレージを分離する必要があり、ログは順次に書き込まれ、raid1+0を実行する必要があり、 を使用するデータは個別に読み書きされます。ファイルシステムキャッシュによって引き起こされるオーバーヘッドを回避するには、direct IOを使用してください。 容量容量、sasasdiskraid cardキャッシュ、read をオフにして、ディスクをオフにして、読み取りをオフにして、使用のみを使用しますもちろん、データサイズが大きくなければ、データストレージには高速な機器、Fusion IO、SSDを使用できます。
データ書き込みの場合は、ダーティ・ページのリフレッシュ頻度を制御し、データ読み取りの場合はキャッシュ・ヒット率を制御します。したがって、システムが必要とするを推定します。 IOPS、必要なハードディスク は10wを超える最大IOPS、通常のハードディスク150)。 Cpu 単一インスタンスに関しては、NUMA はオフになっており、mysql はマルチコアをあまりサポートしておらず、CPU は複数のインスタンスにバインドできます。 b、オペレーティングシステムレベル、 カーネルとソケットの最適化、ネットワーク最適化ボンド、IOスケジューリング innodb 主に OLTP で使用されます アプリケーションは通常、IO 機能の向上に基づいて、キャッシュ メカニズムを最大限に活用します。考慮する必要があるのは次のとおりです: システムの利用可能なメモリを確保することに基づいて、 を可能な限り拡張します。通常は 3 に設定されます。 /4 ファイル システムを使用します。トランザクション ログを記録するときは、ファイル システムの のみを使用します。swap を使用する mysql を避けるようにしてください (vm.swappiness=0 を設定できます)。ファイル システム キャッシュを解放します)IO IO アクセスのレイテンシーを削減します (CFQ、Deadline、 + d. アプリケーション レベル (インデックスの考慮事項、適切な冗長性を備えた スキーマ の最適化、SQL CPU 問題とメモリ問題の最適化、ロックの範囲の削減、テーブル バックの削減など)高可用性の実践に関して、 は マスター-マスター モードと マスター-スレーブ maser-slave はマスターとして読み取りと書き込みを担当し、もう 1 つは障害を提供するスタンバイ として機能します。maser-slave はマスターとして書き込み操作を提供し、他のいくつかのノードは読み取り操作として機能します。 、読み取りと書き込みの分離をサポートします。 ノードマスターとバックアップの障害検出と切り替えには、HAソフトウェアを使用することもできます。もちろん、より多くの観点からクラスター調整サービスとしてzookeeperを使用することもできます。きめ細かいカスタマイズ。 a、oracle の rack などのクラスター方式、欠点は次のとおりです。それはもっと複雑です b 共有 SAN ストレージ方式では、関連するデータ ファイルとログ ファイルが共有ストレージに配置されるため、アクティブとスタンバイの切り替え中にデータの一貫性が維持され、失われることがありません。スタンバイ マシンが一定期間プルアップされ、短期間利用不能状態になります c、メイン データとバックアップ データの同期方法、一般的な方法はログ同期であり、ホット バックアップと良好な状態を保証できます。リアルタイムのパフォーマンスが向上しますが、切り替え中に一部のデータが同期されない可能性があり、データの一貫性の問題が発生します。メインデータベースを操作しながら操作ログを記録できます。スタンバイに切り替えると、同期されていないデータを補うために操作ログの d が実行されます。データが失われないように、メイン ライブラリの regolog mysql ではデータベースのマスター/スレーブ レプリケーションの効率があまり高くありません。主な理由は、トランザクションがレプリケーションに関して厳密に順序を維持するためです: ログ 。および relog log これらはすべてシングルスレッドのシリアル操作であり、データ コピーの最適化の観点から、IO の影響は最小限に抑えられます。ただし、Mysql5.6 バージョンでは、異なるライブラリでの並列レプリケーションがサポートされるようになりました。 Ø さまざまなビジネス要件に基づくアクセス方法 プラットフォーム ビジネスでは、2 つの典型的なビジネス ユーザーと注文、一般的なユーザーなど、さまざまなビジネスに異なるアクセス要件があります。合計量は制御可能ですが、ユーザー テーブルの場合は、まずサブデータベースに分割し、各 シャーディング で 1 つのマスターと複数の読み取りを実行します。注文の場合も同様に、より多くのニーズがあるため、ユーザーはクエリを実行します。注文ライブラリ自体もユーザーに応じて分割する必要があり、1 つのマスターからの複数の読み取りをサポートします。 ハードウェア ストレージに関しては、トランザクション ログは順次書き込まれるため、フラッシュ メモリの利点はハードディスクよりもそれほど高くないため、データ ファイルにはバッテリー保護された書き込みキャッシュ raid カード ストレージが採用されています。ユーザー向けか注文向けかに関係なく、大量のランダムな読み取りおよび書き込み操作が発生します。もちろん、メモリの増設も 1 つの側面です。また、PCIe カードなどの高速 デバイスのフラッシュ メモリも使用できます。 フュージョン-io。フラッシュ メモリの使用は、マスター/スレーブ レプリケーションなどのシングル スレッドのワークロードにも適しています。スレーブ ノードで fusion-IO カードを構成して、レプリケーションの遅延を短縮することができます。 注文業務の量は常に増加しており、PCIeカードのストレージ容量は比較的限られており、注文業務のホットデータは最近の期間のみです(たとえば、最近 ヶ月)、ここでは 2 つの解決策を紹介します。1 つは、フラッシュ メモリとハードディスク ストレージに基づくオープン ソースのハイブリッド ストレージ方式を使用して、フラッシュ メモリにホットスポット データを保存する方法です。別の方法は、古いデータを分散データベース HBase に定期的にエクスポートすることです。ユーザーが注文リストをクエリするとき、古いデータは HBase からクエリできます。 HBase の 適切に設計された rowkey は、クエリのニーズに合わせて設計されています。 データへの高い同時アクセスの場合、従来のリレーショナル データベースは読み取りと書き込みを分離するソリューションを提供しますが、データの一貫性の問題が発生し、大量のデータに対してはデータ セグメンテーション ソリューションが提供されます。従来のデータベースはサブデータベースとサブテーブルを使用しますが、実装がより複雑であり、将来的には継続的な移行とメンテナンスが必要になります。高可用性とスケーリングを実現するために、従来のデータはマスター/スタンバイ、マスター/スレーブ、およびマルチマスターのソリューションを使用します。ただし、ノードの追加とダウンタイムによりデータの移行が必要になるため、スケーラビリティは比較的低くなります。上記の問題に対して、分散データベース HBase には、同時実行性の高い大規模なデータ アクセス要件に適したソリューションの完全なセットが用意されています。 Ø HBase 列ベースの効率的なストレージにより、IO 高いパフォーマンス LSMツリー 高速書き込みシナリオに適しています 強力で一貫したデータアクセス MVCC HBase の一貫したデータ アクセスは、MVCC を通じて実装されます。 HBase データを書き込むプロセスでは、HLog の書き込み、memstore の書き込み、MVCC の更新といういくつかの段階を経る必要があります。たとえば、データの読み取りでは、他のスレッドによって送信されていないデータを取得することはできません。 信頼性の高いHBaseのデータストレージは、冗長メカニズムを提供するHDFSに基づいています。 リージョン フラッシュされていないメモリ内のデータに対する信頼性の高い回復メカニズムを提供します。 Zookeeperを介したスケーラブルな自動分割、移行 リージョンサーバー 。
リージョンサーバーは、それ自体をMasterに公開することで拡張され、Masterは均等に分散されます。 可用性 リージョンサーバーがダウンすると、サーバーによって維持されているリージョンに短期間でアクセスできなくなります。 が有効になるのを待っています。
は、マスターを介して各リージョンサーバーのヘルスステータスとリージョンの配布を維持します。 複数のマスター、マスターのダウンタイムには、zookeeperのpaxos投票メカニズムがあり、次のマスターを選択します。 Masterが完全にダウンしても、Regionの読み書きには影響しません。 マスターは、自動運用とメンテナンスの役割としてのみ機能します。 HDFSは、1つのバックアップ、3つのバックアップ、高い信頼性、0データ損失を備えた分散ストレージエンジンです。 HDFS の namenode は SPOF です。 単一リージョンへの頻繁なアクセスや単一マシンへの過剰な負荷を避けるために、分割メカニズム HBaseはLSM-TREEアーキテクチャを使用して書かれています。データには、append、HFile、HBaseがますます増えており、期限切れのデータをクリアし、クエリのパフォーマンスを向上させるためにHFileファイル処理compactを提供します。 スキーマフリー HBaseリレーショナルデータベースのような厳密なスキーマはなく、スキーマの追加や削除が可能 のフィールドを自由に入力してください。 分散データベースは現在、rowkey のインデックスのみをサポートしているため、rowkey の設計はクエリのパフォーマンスにとって非常に重要です。 7. 管理および展開構成 展開プラットフォーム 8. 大規模な分散システムにはさまざまなデバイスが関与します。ネットワークスイッチなど、通常の プラットフォームのデータ分類 アプリケーションビジネスレベル: アプリケーションイベント、ビジネスログ、監査ログ、リクエストログ、例外、リクエストビジネス 、パフォーマンスメトリクス システムレベル: CPU 、メモリ、ネットワーク、IO 適時性要件 しきい値、アラーム: リアルタイム計算: ほぼリアルタイムの分計算 時間と日ごとのオフライン分析 リアルタイム クエリ ノード内の エージェントは、ログ、アプリケーション イベントを受信し、プローブを通じてデータを収集できます。 エージェント データ収集の原則の 1 つは、ビジネス アプリケーションから非同期的に分離されることです。トランザクションのプロセスには影響しません。 データはコレクタークラスターを通じて均一に収集され、処理するデータの種類に応じて異なるコンピューティングクラスターに分散されます。一部のデータは、時間ごとの統計など、hadoopクラスターに入れられます。循環する追跡データをクエリ可能にする必要がある場合は、インデックス作成のために solr クラスターに入れることができます。リアルタイムで計算してアラートを送信する必要がある一部のデータは、処理のために storm クラスターに入れる必要があります。 データがコンピューティングクラスターによって処理された後、結果はMysqlまたはHBaseに保存されます。 モニタリング web アプリケーションは、リアルタイムのモニタリング結果をブラウザにプッシュでき、結果の表示と検索のための API も提供できます。 3. 多次元可用性
1) ロードバランシング、災害復旧、バックアップ
2) 読み取りと書き込みの分離
3) 依存関係
モニタリング
モニタリングは、プラットフォーム全体の可用性を向上させるための重要な手段でもあり、実行時にモジュールが透過的にホワイトボックス化を実現します。ランタイム。 スケーリング
1) 分割
には、ビジネスの分割とデータベースの分割が含まれます。 ステートレス
システムのスケーラビリティのためには、モジュールがステートレスであることが最適であり、ノードを追加することで全体のスループットを向上させることができます。 5. リソース使用率を最適化する
1) システム容量は限られています
2) アトミック操作と同時実行制御
3) さまざまなロジックに基づいて、さまざまな戦略が採用されます
4) フォールトトレラントな分離
5) リソースの解放
3. アーキテクチャの分析
1. CDN
2. ロードバランシング、リバースプロキシ
3. アプリアクセス
4ビジネス サービス
ping
操作を送信します)

2) ルーティングルーター

3) HA
プラットフォームのさまざまなシステム間の非同期対話の場合、MQ
コンポーネントを通じて実行されます。 

8) データ同期
 完全なオフラインバージョンは、スペース間の時間を交換し、分割統治する原則に従って、データ同期時間を可能な限り短縮し、同期の効率を向上させます。
完全なオフラインバージョンは、スペース間の時間を交換し、分割統治する原則に従って、データ同期時間を可能な限り短縮し、同期の効率を向上させます。 
-ベースのHadoop
の大量データ分析、データ分析は、1. ビジネス量が増加し、計算量が増加するにつれて、ノード処理を増やすと、処理できるようになります。

12) レコメンデーションエンジン
6. データストレージ
1) インメモリデータベース

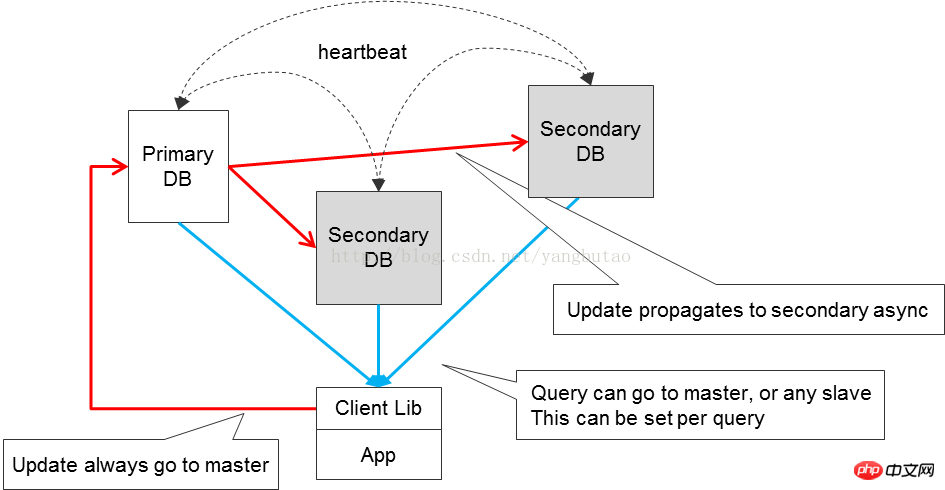
2) リレーショナルデータベース
3) 分散データベース
通常のクエリは行内のすべてのフィールドを必要とせず、ほとんどのクエリはいくつかのフィールドのみを必要とします
行指向のストレージ システムでは、各クエリはすべてのデータを必要としますが取り出され、そこから必要なフィールドが選択されます
列指向のストレージ システムは列を個別にクエリできるため、大幅に削減されますIO
圧縮効率が向上します
同じ列内のデータは類似性が高く、圧縮効率が向上します
Hbase その機能の多くは列ストレージによって決定されます
 を見つけ、最後に
を見つけ、最後に 統合構成ライブラリ
マシン、さまざまな種類のネットワーク カード、ハードディスク、メモリなどだけでなく、アプリケーションのビジネス レベルの監視もその数が非常に多くなると、エラーの可能性も高まり、いくつかの監視要件が発生します。比較的タイムリーで、第 2 レベルに達する一部の異常データは多数のデータ ストリームでフィルタリングする必要があり、アラームが必要かどうかを判断するためにデータに対して複雑なコンテキスト関連の計算が実行される場合があります。したがって、監視プラットフォームのパフォーマンス、スループット、可用性がより重要になり、すべてのレベルでシステムを監視するための統合された監視プラットフォームを計画する必要があります。

以上が同時実行性と可用性の高いアーキテクチャを構築するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。