
ホームページ >データベース >mysql チュートリアル >Mysql でのクエリ操作が遅い
Mysql でのクエリ操作が遅い

- 怪我咯オリジナル
- 2017-07-05 11:20:411412ブラウズ
今日、特に Web アプリケーションでは、データベース操作がアプリケーション全体のパフォーマンスのボトルネックになっています。データベースのパフォーマンスに関しては、DBA だけでなくプログラマーも注意を払う必要があります。現在、データベース操作がアプリケーション全体のパフォーマンスのボトルネックになっています。 Web にとって非常に重要 アプリケーションは特に明白です。データベースのパフォーマンスに関しては、DBA だけが心配する必要があるのではなく、私たちプログラマも注意を払う必要があります。
データベーステーブル構造を設計するときは、データベースを操作するときのデータ操作 (特にテーブルを検索するときの SQL ステートメント) のパフォーマンスに注意を払う必要があります。ここでは、SQL ステートメントの最適化についてはあまり説明せず、最も多くの Web アプリケーションが含まれるデータベースである MySQL にのみ焦点を当てます。 Mysql の
パフォーマンスの最適化 は、一夜にして達成できるものではありません。段階的に進めてあらゆる面から最適化する必要があり、最終的にはパフォーマンスが大幅に向上します。 mysqlデータベース最適化技術4種類: 通常インデックス、主キーインデックス、一意インデックス、全文インデックス]
•読み取りと書き込み[書き込み:更新/削除/追加]分離 •ストアドプロシージャ
[モジュラープログラミング、速度を上げることができます]
• mysql構成の最適化[my.iniの最大同時実行数を構成し、キャッシュサイズを調整します]
• Mysqlサーバーハードウェアのアップグレード
•時間指定不要なデータを削除し、定期的にデフラグを実行します (MyISAM)
データベース最適化作業
データ中心のアプリケーションでは、データベースの品質がプログラムのパフォーマンスに直接影響するため、データベースのパフォーマンスが重要です。一般的に、データベースの効率を確保するには、次の 4 つの側面を行う必要があります:
① データベース設計
② SQL ステートメントの最適化
③ データベースパラメータの設定
④ 適切なハードウェアリソースと運用 システム
さらに、適切なストアド プロシージャを使用すると、パフォーマンスを向上させることもできます。
データベース テーブルの設計
一般的な方法で 3 つのパラダイムを理解することは、データベース設計に大きな利点があります。データベース設計では、3 つのパラダイムをより適切に適用するために、一般的な方法で 3 つのパラダイムを理解する必要があります (一般的な理解は十分な理解であり、最も科学的で正確な理解ではありません):
第一正規形: 1NF は属性の原子性制約であり、属性 (列) が原子的である必要があり、分解することはできません (
リレーショナル データベース
ただし、冗長性のないデータベースは最適なデータベースではない可能性があり、運用効率を向上させるために、パラダイム基準を下げて冗長データを適切に保持する必要がある場合があります。具体的なアプローチは、概念データ モデルを設計するときは 3 番目のパラダイムに従い、物理データ モデルを設計するときはパラダイム標準を下げる作業を考慮することです。通常の形式を下げるということは、フィールドを追加して冗長性を考慮することを意味します。
リレーショナルデータベース: mysql/oracle/db2/informix/sysbase/sqlサーバー
非リレーショナルデータベース: (特徴: オブジェクト指向
またはコレクション)
NoSqlデータベース: MongoDB (ドキュメント指向の特徴)
適度な冗長性、または理由のある冗長性とは何か!
上記は不適切な冗長性であり、その理由は次のとおりです:
ここでは、生徒の活動記録の検索効率を高めるため、生徒の活動記録テーブルに単元名を重複して追加します。単元情報は500件あり、学生の活動記録は1年間で約200万件のデータがあります。 学生活動記録テーブルが単位名フィールドを冗長化していない場合、テーブルには 3 つの int フィールドと 1 つのタイムスタンプ フィールドのみが含まれ、占有量は 16 バイトのみで、非常に小さなテーブルになります。冗長な varchar(32) フィールドを使用すると、サイズは元のサイズの 3 倍になり、取得には非常に多くの I/O が必要になります。さらに、レコード数が 500 VS 2,000,000 と大きく異なるため、ユニット名を更新する際に 4,000 件の冗長なレコードを更新する必要があります。この冗長性は単に逆効果であることがわかります。
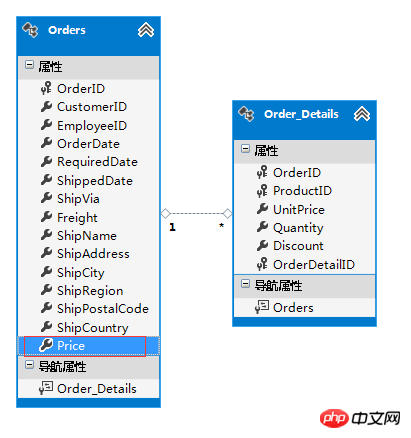
この注文の価格は注文詳細テーブルから計算できるため、注文テーブルの価格は冗長フィールドですが、この冗長性は合理的であり、クエリのパフォーマンスも向上させることができます。
上記の 2 つの例から結論が導き出されます:
1---n の冗長性は 1 側で発生するはずです
SQL ステートメントの最適化
一般的な SQL 最適化手順
1. show status コマンドを使用して、さまざまな SQL の実行頻度を把握します。
2. 実行効率の低い SQL ステートメントを特定する - (選択に重点を置く)
3. Explain を通じて非効率な SQL を分析し、対応する最適化措置を講じます
-- select语句分类 Select Dml数据操作语言(insert update delete) dtl 数据事物语言(commit rollback savepoint) Ddl数据定义语言(create alter drop..) Dcl(数据控制语言) grant revoke -- Show status 常用命令 --查询本次会话 Show session status like 'com_%'; //show session status like 'Com_select' --查询全局 Show global status like 'com_%'; -- 给某个用户授权 grant all privileges on *.* to 'abc'@'%'; --为什么这样授权 'abc'表示用户名 '@' 表示host, 查看一下mysql->user表就知道了 --回收权限 revoke all on *.* from 'abc'@'%'; --刷新权限[也可以不写] flush privileges;SQL ステートメントを最適化します。 -show パラメーター
MySQL クライアントが正常に接続された後、show [session|global] status コマンドを使用してサーバーのステータス情報を提供できます。セッションは現在の接続の統計結果を表し、グローバルはデータベースが最後に起動されてからの統計結果を表します。デフォルトはセッションレベルです。
次の例:
show status like 'Com_%';
ここで、Com_XXX は XXX ステートメントが実行された回数を表します。
重要な注意事項: Com_select、Com_insert、Com_update、Com_delete により、現在のデータベース アプリケーションが主に挿入および更新操作に基づいているか、クエリ操作に基づいているか、およびさまざまな種類の SQL のおおよその実行率を簡単に理解できます。 。 幾つか。
ユーザーがデータベースの基本的な状況を理解するのに役立つ、一般的に使用されるパラメーターもいくつかあります。
Connections: MySQL サーバーへの接続試行回数
Uptime: サーバーの動作時間 (秒単位)
Slow_queries: 低速クエリの数 (デフォルトは低速クエリ時間 10 秒)
show status like 'Connections' show status like 'Uptime' show status like 'Slow_queries'mysql の遅いクエリをクエリする方法 時間
Show variables like 'long_query_time';mysql の遅いクエリ時間を変更する
set long_query_time=2SQL ステートメントの最適化 - 遅いクエリを見つける
問題は、大規模なプロジェクトから実行の遅いステートメントを素早く見つける方法です。 (遅いクエリの特定)
まず、mysql データベースの実行ステータスをクエリする方法を理解します (たとえば、mysql の現在の実行時間/合計実行回数を知りたい場合)。
select/update/delete../current connection)
ストアド プロシージャを使用します
Build
デフォルトでは、mysql は実行に 10 秒かかるとみなします。遅いクエリになります。
show variables like 'long_query_time' ; //可以显示当前慢查询时间 set long_query_time=1 ;//可以修改慢查询时间
大きなテーブルを構築します - >大きなテーブル内のレコードには要件があります。レコードは異なる場合にのみ役に立ちます。そうでない場合、テストの効果は大きく異なります。実際のものから作成します:
CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/ loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/ ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8;テストデータ
INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999);
ストアドプロシージャを正常に実行するには、コマンド実行終了文字を入れる必要があります 区切り文字を変更します $$ ランダムを返す関数を作成します指定した長さの文字列
create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串 begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; endストアドプロシージャを作成します
create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; #set autocommit =0 把autocommit设置成0 set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand()); until i = max_num end repeat; commit; end #调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp(100001,4000000);
このとき、ステートメントの実行時間が1秒を超えた場合はカウントされます
遅いクエリSQLをログに記録すると
[mysqld] # The TCP/IP Port the MySQL Server will listen on port=3306 slow-query-log
低速クエリ ログを通じて、実行効率の低い SQL ステートメントを見つけます。スロークエリログには、実行時間がlong_query_timeの設定を超えたすべてのSQLステートメントが記録されます。
show variables like 'long_query_time'; set long_query_time=2;
deptテーブルにデータを追加
desc dept; ALTER table dept add id int PRIMARY key auto_increment; CREATE PRIMARY KEY on dept(id); create INDEX idx_dptno_dptname on dept(deptno,dname); INSERT into dept(deptno,dname,loc) values(1,'研发部','康和盛大厦5楼501'); INSERT into dept(deptno,dname,loc) values(2,'产品部','康和盛大厦5楼502'); INSERT into dept(deptno,dname,loc) values(3,'财务部','康和盛大厦5楼503');UPDATE emp set deptno=1 where empno=100002;
****テストステートメント*** [empテーブルのレコードは3600000になる可能性があり、効果は明らかに遅い]
select * from emp where empno=(select empno from emp where ename='研发部')
e.empnoで順序を持ってくる場合、速度は速くなります 遅く、1 分を超える場合もあります。
テストステートメントselect * from emp e,dept d where e.empno=100002 and e.deptno=d.deptno;
遅いクエリログを表示します。デフォルトは、データディレクトリデータの host-name-slow.log です。 mysql の下位バージョンは、mysql を開くときに - -log-slow-queries[=file_name] を使用して設定する必要があります
SQL ステートメントの最適化 - 分析問題の説明
Explain select * from emp where ename=“wsrcla”
は次の情報を生成します:
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明

explain select * from emp where ename='JKLOIP'
如果要测试Extra的filesort可以对上面的语句修改
explain select * from emp order by ename\G
EXPLAIN详解
id
SELECT识别符。这是SELECT的查询序列号
id 示例
SELECT * FROM emp WHERE empno = 1 and ename = (SELECT ename FROM emp WHERE empno = 100001) \G;
select_type
PRIMARY :子查询中最外层查询
SUBQUERY : 子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY:子查询内层第一个SELECT,依赖于外部查询
UNION :UNION语句中第二个SELECT开始后面所有SELECT,
SIMPLE
UNION RESULT UNION 中合并结果
Table
显示这一步所访问数据库中表名称
Type
对表访问方式
ALL:
SELECT * FROM emp \G
完整的表扫描 通常不好
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system:表仅有一行(=系统表)。这是const联接类型的一个特
const:表最多有一个匹配行
Possible_keys
该查询可以利用的索引,如果没有任何索引显示 null
Key
Mysql 从 Possible_keys 所选择使用索引
Rows
估算出结果集行数
Extra
查询细节信息
No tables :Query语句中使用FROM DUAL 或不含任何FROM子句
Using filesort :当Query中包含 ORDER BY 操作,而且无法利用索引完成排序,
Impossible WHERE noticed after reading const tables: MYSQL Query Optimizer
通过收集统计信息不可能存在结果
Using temporary:某些操作必须使用临时表,常见 GROUP BY ; ORDER BY
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据;
以上がMysql でのクエリ操作が遅いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。