
ホームページ >運用・保守 >Linuxの運用と保守 >Heka 構成の詳細な紹介
Heka 構成の詳細な紹介

- 零下一度オリジナル
- 2017-07-18 16:47:213011ブラウズ
この Linux チュートリアルでは、Heka の構成について説明します。具体的な操作プロセス:
Heka、ElasticSearch、Kibana に基づく分散バックエンド ログ アーキテクチャ
現在主流のバックエンド ログは、標準の Elk モード (Elasticsearch、Logstash) を使用します。 、Kinaba)、それぞれログの保存、収集、およびログの可視化を担当します。
ただし、ログ ファイルは多様であり、異なるサーバーに分散されているため、将来の二次開発やカスタマイズを容易にするためにさまざまなログが使用されます。そこでMozillaは、オープンソースのgolangを利用して実装され、Logstashを模倣したHekaを採用した。
Heka、ElasticSearch、Kibana に基づく分散バックエンド ログ アーキテクチャ
現在主流のバックエンド ログは標準の elk モード (Elasticsearch、Logstash、Kinaba) を採用しており、それぞれログの保存、収集、ログの視覚化を担当します。
ただし、ログ ファイルは多様であり、さまざまなサーバーに分散されているため、さまざまなログは、将来の二次開発やカスタマイズを容易にするために使用されます。そこでMozillaは、オープンソースのgolangを利用して実装され、Logstashを模倣したHekaを採用した。
全体的なアーキテクチャ図
Heka、ElasticSearch、Kibanaを使用した後の全体的なアーキテクチャを以下の図に示します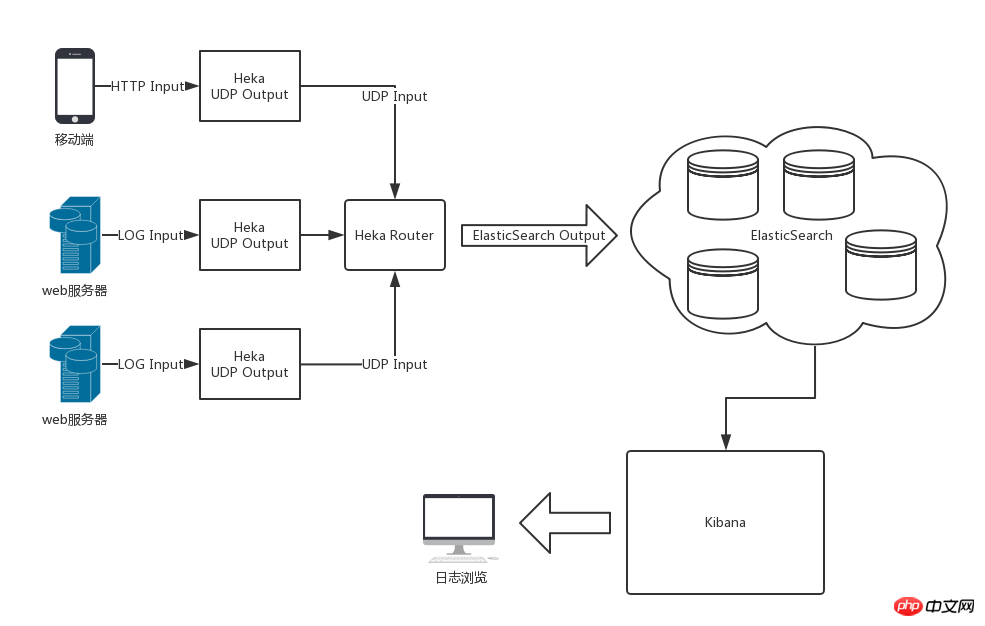
Hekaの章
はじめに
Hekaのログ処理フローは、入力、セグメンテーション、デコード、フィルタリング、エンコード、出力です。単一の Heka サービス内のデータ フローは、Heka によって定義されたメッセージ データ モデルを通じて各モジュール内を流れます。
heka には、
入力プラグインなどの最も一般的に使用されるモジュール プラグインが組み込まれています。 Logstreamer 入力はログ ファイルを入力ソースとして使用でき、
デコード プラグイン Nginx Access Log Decoder はデコードできますnginx は標準キーにアクセス ログを記録します。値ペアのデータは、後続のモジュール プラグインに渡されて処理されます。
入出力の柔軟な構成のおかげで、Heka によってさまざまな場所で収集されたログ データは、統一されたエンコードのために処理されてログ センターの Heka に出力され、保存のために ElasticSearch に渡されます。
以上がHeka 構成の詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。