
ホームページ >運用・保守 >Linuxの運用と保守 >Linuxのプロセスとシグナル
Linuxのプロセスとシグナル
- 巴扎黑オリジナル
- 2017-06-23 13:49:162225ブラウズ
この記事のディレクトリ:
9.1 プロセスの簡単な説明
9.11 プロセスとプログラムの違い
9.12 マルチタスクと CPU 時間スライス
9.13 親子プロセスとプロセスの作成方法
9.14 プロセスのステータス
9.15 を分析する例を挙げてみましょう。プロセス状態遷移プロセス
9.16 プロセス構造とサブシェル
9.2 ジョブタスク
9.3 ターミナルとサブシェルの関係プロセス
9.4 シグナル
9.41 知っておくべきシグナル
9.42 ため息
9.43 ゾンビプロセスと SIGCHLD
9.4 4 手動送信シグナル (kill コマンド)
9.45 pkill と killall
9.5 fuser と lsof
9.1 プロセスの簡単な説明
プロセスは次のとおりです。非常に複雑な概念であり、多くの内容が含まれています。このセクションに記載されている内容は、コマンドを使用してステータスを確認する方法よりも、できる限り理解する必要があると思います。後でステータス情報を確認してください。基本的に、対応するステータスが何を意味するかはわかりません。
しかし、プログラマーではない人にとっては、プロセスの詳細を詳しく調べる必要はありません。もちろん、詳しい方が便利です。
9.1.1 プロセスとプログラムの違い
プログラムはバイナリファイルであり、ディスク上に静的に保存され、システム実行リソース (CPU/メモリ) を占有しません。
プロセスは、ユーザーがプログラムを実行するか、プログラムをトリガーした結果です。プロセスは、プログラムの実行中のインスタンスであると考えることができます。このプロセスは動的であり、システム リソースを適用して使用し、オペレーティング システム カーネルと対話します。次の記事では、多くのステータス統計ツールの結果がシステム クラスのステータスを示しています。実際、システム ステータスの同義語はカーネル ステータスです。
9.1.2 マルチタスクと CPU 時間スライス
現在、すべてのオペレーティング システムで複数のプロセスを「同時に」実行できます。これがマルチタスクまたは並列実行です。しかし実際には、これは人間の幻想です。物理 CPU は同時に 1 つのプロセスしか実行できません。実際にマルチタスクを実現できるのは、複数の物理 CPU だけです。
人間は、オペレーティング システムがいくつかのことを並行して実行できると錯覚します。これは、非常に短い時間でプロセスを切り替えることによって実現されます。その時間が非常に短いため、プロセス A は一度に実行されます。 B. 複数のプロセスを常に切り替えると、人間は同時に複数の処理を行っていると考えるようになります。 ただし、CPU が次に実行するプロセスをどのように選択するかは非常に複雑です。Linux では、次に実行するプロセスの決定は、「スケジューリング クラス」(スケジューラー) を通じて行われます。プログラムがいつ実行されるかはプロセスの優先度によって決まりますが、優先度の値が低いほど優先度が高くなり、スケジューリング クラスによってより早く選択されることに注意してください。 Linux では、プロセスの nice 値を変更すると、特定の種類のプロセスの優先順位の値に影響を与える可能性があります。
一部のプロセスはより重要であり、できるだけ早く完了する必要がありますが、一部のプロセスはそれほど重要ではなく、早くても遅くても大きな影響はありません。したがって、オペレーティング システムはどのプロセスがより重要であるかを認識できる必要があります。プロセスはそれほど重要ではありません。より重要なプロセスについては、できるだけ早く完了できるように、より多くの CPU 実行時間を割り当てる必要があります。下図はCPUタイムスライスの概念です。

このことから、すべてのプロセスが実行される可能性があることがわかりますが、重要なプロセスは常により多くの CPU 時間を取得します。この方法は「プリエンプティブ マルチタスク」です。 カーネルは CPU を強制的に同時に実行できます。 . CPU チップが枯渇すると、CPU 使用権が回復され、スケジューリング クラスで選択されたプロセスに CPU が与えられます。また、場合によっては、現在実行中のプロセスを直接プリエンプトすることもできます。時間が経つと、プロセスに割り当てられた時間が徐々に消費され、割り当てられた時間が消費されると、カーネルはプロセスの制御を取り戻し、次のプロセスを実行します。しかし、前のプロセスはまだ完了していないため、スケジューリング クラスは将来のある時点でそのプロセスを選択することになるため、カーネルは各プロセスが一時的に停止されるとき (保存) にランタイム環境 (レジスタおよびページ テーブルの内容) を保存する必要があります。場所はカーネルによって占有されているメモリです。これは保護サイトと呼ばれ、次回プロセスの実行が再開されると、元のランタイム環境が CPU にロードされ、CPU が実行を継続できるようになります。元のランタイム環境で。
Linux スケジューラは、CPU タイム スライスの経過に基づいて実行する次のプロセスを選択するのではなく、プロセスの待機時間、つまり準備完了キューでどれだけ待機したかを考慮すると述べています。最も厳しい時間要件がある場合、プロセスはできるだけ早く実行をスケジュールする必要があります。さらに、重要なプロセスには当然により多くの CPU 実行時間が割り当てられます。
スケジューリング クラスは、実行する次のプロセスを選択した後、基礎となるタスクの切り替え、つまりコンテキストの切り替えを実行する必要があります。このプロセスには CPU プロセスとの緊密な対話が必要です。 プロセスの切り替えは頻繁すぎても、遅すぎてもいけません。切り替えが頻繁すぎると、保護と回復のシーンで CPU が長時間アイドル状態になり、人間やプロセスにとって生産的ではありません (プログラムが実行されないため)。切り替えが遅すぎると、プロセス スケジュールの切り替えが遅くなります 率直に言えば、ls コマンドを発行すると、次のプロセスが実行されるまでに長時間待機する必要がある可能性があります。半日も待たなければなりませんが、それは明らかに許されていません。
この時点で、メモリの測定単位が空間サイズであるのと同様に、CPU の測定単位は時間であることがわかります。プロセスが占める CPU 時間が長いということは、CPU がそのプロセスで長時間実行されることを意味します。 CPU のパーセント値は、その作業強度や頻度ではなく、「プロセスが占有する CPU 時間 / 合計 CPU 時間」という測定概念を間違えてはいけないことに注意してください。
9.1.3 親子プロセスとプロセスの作成方法
各プロセスには、プログラムを実行するユーザーの UID およびその他の基準に基づいて、一意の PID が割り当てられます。
親子プロセスの概念は、簡単に言えば、あるプロセス(親プロセス)のコンテキストでプログラムが実行または呼び出されたとき、このプログラムによってトリガーされるプロセスが子プロセスであり、プロセスのPPIDはプロセスの親プロセスの PID。このことから、子プロセスは常に親プロセスによって作成されることもわかります。
Linuxでは親子プロセスがツリー構造で存在し、親プロセスによって作られた複数の子プロセスを兄弟プロセスと呼びます。 CentOS 6 では、init プロセスはすべてのプロセスの親プロセスであり、CentOS 7 では systemd です。
Linux 上で子プロセスを作成するには 3 つの方法があります (非常に重要な概念): 1 つは fork によって作成されるプロセス、1 つは exec によって作成されるプロセス、そして 1 つは clone によって作成されるプロセスです。
(1).fork はコピープロセスであり、現在のプロセスのコピーを (コピーオンライトモードに関係なく) コピーし、これらのリソースを適切な方法で子プロセスに渡します。したがって、子プロセスが制御するリソースは、メモリの内容も含めて親プロセスと同じなので、環境変数や変数も含まれます。ただし、親プロセスと子プロセスは完全に独立しています。これらは同じプログラムの 2 つのインスタンスです。
(2).exec は、現在実行中のプロセスを置き換えるために別のアプリケーションをロードします。これは、新しいプロセスを作成せずに新しいプログラムをロードすることを意味します。 exec には別のアクションもあります。プロセスの実行後、exec が配置されているシェルを終了します。したがって、プロセスのセキュリティを確保するために、新しい独立した子プロセスを形成する場合は、まず現在のプロセスのコピーをフォークし、次にフォークされた子プロセスで exec を呼び出して、子プロセスを置き換える新しいプログラムをロードします。プロセス。たとえば、bash で cp コマンドを実行する場合、最初に bash がフォークされ、次に exec が cp プログラムをロードしてサブ bash プロセスを上書きし、cp プロセスになります。
(3).clone はスレッドの実装に使用されます。 クローンはフォークと同じように機能しますが、クローンされた新しいプロセスは親プロセスから独立していません。プロセスをクローンするときに、どのリソースを共有するかを指定できます。
通常、兄弟プロセスは独立していて互いに見えませんが、特別な手段を介してプロセス間通信を実現できる場合があります。たとえば、パイプは両側のプロセスを調整し、両方のプロセスは同じプロセス グループに属し、その PPID が同じであるため、「パイプライン」方式でデータを転送できます。
プロセスには所有者、つまり開始者がいます。ユーザーがプロセス開始者、親プロセス開始者、または root ユーザーでない場合、プロセスを強制終了することはできません。また、親プロセス (非端末プロセス) を強制終了すると、子プロセスは孤立プロセスになります。孤立プロセスの親プロセスは常に init/systemd になります。
9.1.4 プロセスステータス
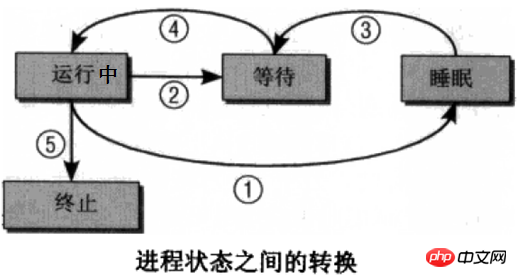
プロセスは常に実行されているわけではありません。少なくとも、CPU が実行されていないときは非実行です。プロセスには複数の状態があり、異なる状態間で状態を切り替えることができます。下の図は非常に古典的なプロセスの状態説明図ですが、個人的には右の図の方がわかりやすいと感じます。
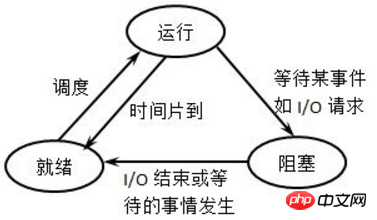
実行状態: プロセスは実行中、つまり CPU が稼働しています。
Ready (待機中) 状態: プロセスは実行可能で、すでに待機キューに入っています。これは、スケジューリング クラスが次回そのプロセスを選択する可能性があることを意味します。
Sleep (ブロック) 状態: プロセスはスリープ状態であり、実行できません。
各状態間の変換方法は次のとおりです: (わかりにくいかもしれませんが、後の例と組み合わせることができます)
(1) 新しい状態 -> 準備完了状態: 待機キューが新しいプロセスの受け入れを許可されている場合、カーネルは新しいプロセスを待機キューに移動します。
(2) Ready状態→Running状態:スケジューリングクラスが待機キュー内のプロセスを選択し、そのプロセスはRunning状態になります。
(3) 実行状態→スリープ状態: 実行中のプロセスは、特定のイベント(IO待ち、シグナル待ちなど)の発生を待つ必要があるため実行できず、スリープ状態に入ります。
(4) スリープ状態 -> 準備完了状態: プロセスが待機しているイベントが発生すると、プロセスはスリープ状態から待機キューに入れられ、次回の実行に選択されるのを待ちます。
(5) 実行状態 -> 準備完了状態: 実行中のプロセスはタイム スライスの不足により一時停止されます。または、プリエンプティブ スケジューリング モードでは、高優先度のプロセスが実行中の低優先度のプロセスを強制的にプリエンプトします。
(6) 実行状態 -> 終了状態: プロセスが完了するか、何らかの特別なイベントが発生すると、プロセスは終了状態になります。コマンドの場合、通常、終了ステータス コードが返されます。
上の図では、「準備完了 --> スリープ」と「スリープ --> 実行」の間の状態の切り替えがないことに注意してください。わかりやすいですね。 「Ready-->Sleep」の場合、待機中のプロセスはすでに待機キューに入っており、実行可能であることを示します。スリープ状態に入るということは、一時的に実行できなくなることを意味します。これ自体が「Sleep-->Sleep」の場合は競合します。 >Run」 これも機能しません。スケジューリング クラスは、実行する次のプロセスを待機キューから選択するだけだからです。
実行状態 -> スリープ状態について話しましょう。実行状態からスリープ状態に移行するまでは、通常、シグナル通知待ちや IO 完了待ちなどのイベントの発生を待つことになります。シグナル通知は理解しやすいですが、IO待機の場合、プログラムを実行するには、CPUがプログラムの命令を実行する必要があり、同時に、変数データ、キーボード入力データ、またはデータなどのデータを入力する必要があります。ディスク ファイルでは、後の 2 種類のデータは CPU に比べて非常に遅いです。しかし、何があっても、CPU がデータを必要とする瞬間にデータを取得できない場合、CPU はアイドル状態になることしかできません。これは絶対に当てはまりません。CPU は非常に貴重なリソースなので、カーネルはそれを許可する必要があります。 CPU が実行され、データが必要になると、プロセスは一時的にスリープ状態になり、データの準備ができるまで待機してから待機キューに戻り、スケジューリング クラスによって選択されるのを待ちます。こちらはIO待機中です。
実際、上の画像にはプロセスゾンビ状態の特別な状態がありません。 ゾンビプロセスは、プロセスが終了状態に移行し、その使命を完了して消滅しましたが、カーネルがプロセスリスト内のエントリを削除する時間がなかったことを意味します。これは、カーネルが注意を払っていなかったことを意味します。これにより、プロセスが死んでいても生きているような錯覚が生じます。これは、スケジューリング クラスがそのプロセスを選択して実行することは不可能であるため、死んでいると言えます。プロセス リストにまだ存在するため、キャプチャできる対応するエントリが存在します。ゾンビ プロセスは多くのリソースを占有しません。プロセス リスト内でわずかなメモリを占有するだけです。ほとんどのゾンビ プロセスは、プロセスが正常に終了する (kill -9 を含む) ために表示されますが、親プロセスはプロセスが終了したことを確認しないため、カーネルに通知されず、カーネルはプロセスが終了したことを認識しません。ゾンビプロセスの詳細な手順については、後でを参照してください。
さらに、睡眠状態は非常に広い概念であり、中断可能なスリープと中断できないスリープに分けられます。割り込み可能なスリープは、外部信号およびカーネル信号を受信することによって目覚めることができるスリープです。スリープの大部分は、ps または top によって捕捉できる割り込み可能なスリープであり、これはほとんどの場合、割り込み可能なスリープです。カーネルが起動するための信号を開始します。主にハードウェアと対話する場合、外部の世界は信号を通じて起動できません。たとえば、ファイルを保存する場合、ハードディスクからメモリへのデータのロードは、ハードウェアとのやり取りの間、中断されないようにする必要があります。そうしないと、データのロード時に人間が送信した信号によって突然手動で起動されてしまいます。起動しても、ハードウェア対話プロセスはまだ完了していないため、起動しても CPU に実行を与えることができないため、コンテンツの一部だけを表示することはできません。ファイルを猫化しています。さらに、中断されないスリープを人工的に目覚めさせることができる場合、より深刻な結果はハードウェアのクラッシュです。無中断スリープは、特定の重要なプロセスを保護し、CPU の無駄を防ぐためであることがわかります。一般に、中断されないスリープは非常に短時間であり、プログラム以外で取得するのは非常に困難です。
実際、プロセスが存在することが判明し、ゾンビプロセスではなく、CPU リソースを占有していない限り、そのプロセスはスリープ状態になります。記事後半で出てくる一時停止状態やトラッキング状態も含めてスリープ状態です。
9.1.5 例を使ってプロセスの状態遷移プロセスを分析する
プロセス間の状態遷移は複雑になる可能性があるので、できる限り詳しく説明するために例を示します。
例として、bash で cp コマンドを実行します。現在の bash 環境では、実行可能な状態 (準備完了状態) にあるときに cp コマンドが実行されると、最初に bash サブプロセスがフォークされ、次に cp プログラムがサブプロセス上の exec によってロードされます。 cp サブプロセスは待機キューに入ります。このコマンドはコマンド ラインに入力されるため、優先順位が高く、スケジューリング クラスによってすぐに選択されます。子プロセス cp の実行中、親プロセス bash はスリープ状態に入り (CPU が 1 つしかない場合、一度に 1 つのプロセスしか実行できないだけでなく、プロセスが待機しているため)、スリープ状態になるまで待機します。現時点では、bash は人間と対話できません。 cp コマンドが実行されると、コピーが成功したか失敗したかを親プロセスに通知します。その後、cp プロセスは自動的に消滅し、親プロセス bash が目覚めて再び待機キューに入ります。 bash が終了ステータス コードを取得した時間。ステータス コードの「シグナル」に従って、親プロセス bash は子プロセスが終了したことを認識するため、カーネルに通知し、通知を受け取った後、カーネルはプロセス リストの cp プロセス エントリを削除します。この時点で、cp プロセス全体が正常に完了します。
cp サブプロセスが大きなファイルをコピーし、CPU タイム スライスがコピーを完了できない場合、CPU タイム スライスが使い果たされると待機キューに入ります。
cp サブプロセスがファイルをコピーし、ターゲットの場所に同じ名前のファイルがすでに存在する場合、クエリを送信するときに、デフォルトでそれを上書きするかどうかを尋ね、yes または no のシグナルを待ちます。 , そのため、スリープ状態に入ります (スリープは中断できます)。キーボードで cp に「yes」または「no」信号を入力すると、cp は信号を受信し、スリープ状態から準備完了状態に切り替わり、スケジューリング クラスがそれを選択して完了するのを待ちます。 CPプロセス。
cp がコピーするとき、ハードウェアと対話する短いプロセスの間、cp は中断不可能なスリープ状態になります。
cp プロセスが終了しても、終了プロセス中に何らかの事故が発生して、bash の親プロセスが終了したことを認識しない場合 (この例ではこれは不可能です)、bash はカーネルに通知しません。プロセス リストの cp エントリを再利用すると、この時点で cp はゾンビ プロセスになります。
9.1.6 プロセス構造とサブシェル
フォアグラウンド プロセス: 一般的なコマンド (cp コマンドなど) は、子プロセスをフォークして実行します。子プロセスの実行中、親プロセスはスリープ状態になります。このタイプのプロセスはフォアグラウンド プロセスです。 フォアグラウンドプロセスが実行されると、その親プロセスはスリープします、CPUが1つしかないため、複数のCPUがあっても、実行フロー(プロセス待機)により1つのプロセスしか実行できません。真のマルチタスクを実現します。 , 複数の実行ストリームは、インプロセス マルチスレッドを使用して実装する必要があります。
バックグラウンド処理:コマンド実行時にコマンドの最後に記号「&」を付けるとバックグラウンドに入ります。コマンドをバックグラウンドに置くと、すぐに親プロセスに戻り、バックグラウンド プロセスの jobid と pid が返されるため、バックグラウンド プロセスの親プロセスはスリープ状態になりません。バックグラウンドプロセスでエラーが発生した場合、または実行が完了してバックグラウンドプロセスが終了した場合、親プロセスがシグナルを受け取ります。したがって、コマンドの後に「&」を追加し、その「&」の後に別のコマンドを実行させることで、「cp /etc/fstab /tmp & cat /etc」のように「疑似並列」実行を実現できます。 /fstab」。
bash 組み込みコマンド: bash 組み込みコマンドは非常に特殊です。親プロセスはこれらのコマンドを実行するための子プロセスを作成しませんが、現在の bash プロセスで直接実行されます。ただし、組み込みコマンドをパイプの後に配置すると、組み込みコマンドはパイプの左側のプロセスと同じプロセス グループに属するため、子プロセスは引き続き作成されます。
そうは言っても、サブシェル、この特別なサブプロセスについて説明する必要があります。
通常、フォークされた子プロセスの内容は、変数も含めて親プロセスの内容と同じです。たとえば、cp コマンドを実行すると、親プロセスの変数も取得できます。しかし、cp コマンドはどこで実行されるのでしょうか?サブシェル内。 cp コマンドを実行して Enter キーを押すと、現在の bash プロセスはサブ bash をフォークアウトし、サブ bash は exec を通じて cp プログラムをロードしてサブ bash を置き換えます。ここでサブ bash とサブシェルを絡め取らないでください。それらの関係が理解できない場合は、同じものとして扱ってください。
すべてのコマンドの実行環境がサブシェル内にあることを理解できますか?明らかに、上記の bash 組み込みコマンドはサブシェルでは実行されません。他のすべてのメソッドはサブシェルで実行されますが、メソッドは異なります。完全なサブシェルについては、man bash を参照してください。サブシェルについては多くの場所で言及されています。一般的な方法をいくつか紹介します。
(1) bashコマンドを直接実行します。これは非常に偶然の順序です。 bash コマンド自体は組み込み bash コマンドです。現在のシェル環境で組み込みコマンドを実行してもサブシェルは作成されません。つまり、独立した bash プロセスは表示されず、実際の結果は新しい bash になります。子プロセス。理由の 1 つは、bash コマンドを実行すると、さまざまな環境設定項目が読み込まれるため、親の bash 環境が上書きされないように、サブシェルとして存在する必要があります。フォークから出てくる bash サブプロセスの内容は親シェルを完全に継承しますが、環境設定項目の再読み込みにより、サブシェルは通常の変数を継承しません。正確に言うと、変数は上書きされます。親シェルから継承されます。 /etc/bashrc ファイルで変数を定義してから、同じ名前で値が異なる環境変数を親シェルにエクスポートして、サブシェルに移動して変数の値を確認してみてはいかがでしょうか。
(2). シェルスクリプトを実行します。スクリプトの最初の行は常に「#!/bin/bash」または直接「bash xyz.sh」であるため、これは実際には、bash を実行して上記のサブシェルに入るのと同じことです。どちらも bash コマンドを使用して、サブシェル。実行スクリプトにはもう 1 つのアクションがあるというだけです。コマンドの実行後にサブシェルを自動的に終了します。したがって、スクリプトを実行するときに、親シェルの環境変数はスクリプトに継承されません。 - (3). 非組み込みコマンドのコマンド置換。コマンドにコマンド置換部分が含まれる場合、この部分が最初に実行され、この部分が組み込みコマンドでない場合はサブシェル内で完了し、実行結果が現在のコマンドに返されます。このサブシェルは bash コマンドによって入力されたサブシェルではないため、親シェルの変数の内容をすべて継承します。これは、「$(echo $$)」の「$$」の結果が現在の bash の pid 番号であり、サブシェルの pid 番号ではないことも説明しています。これは、bash コマンドを使用して入力されたサブシェルではないためです。
- exec とsource という 2 つの特別なスクリプト呼び出しメソッドもあります。
- exec: exec は現在のプロセスを置き換えるローダーであるため、サブシェルを開きませんが、現在のシェルでコマンドまたはスクリプトを直接実行します。 exec の実行後、exec が配置されているシェルを直接終了します。これは、bash で cp コマンドを実行すると、cp の実行後に cp が配置されているサブシェルが自動的に終了する理由を説明しています。
- source: ソースは通常、環境設定スクリプトをロードするために使用され、コマンドを直接ロードすることはできません。また、サブシェルを開かず、呼び出し元のスクリプトを現在のシェルで直接実行し、スクリプトの実行後に現在のシェルを終了しないため、スクリプトは現在の既存の変数を継承し、スクリプトの実行後にロードされた環境変数は、現在のシェルに固執し、現在のシェルで有効になります。
[root@server2 ~]# cp /etc/fstab /tmp/ &[1] 8701
jobs [--l:jobs默认不会列出后台工作的PID,加上---s:显示后台工作处于stopped状态的jobs「&」によってバックグラウンドに配置されたタスクは、引き続きバックグラウンドで実行されます。もちろん、vim などの対話型コマンドの場合は、実行が一時停止された状態になります。
[root@server2 ~]# sleep 10 &[1] 8710[root@server2 ~]# jobs [1]+ Running sleep 10 &
ここで表示されるのは、running や ps または top によって表示される R ステータスであることに注意してください。待機キュー内のプロセスも、実行中であることを意味するわけではありません。これらはすべて task_running 識別子に属します。 手動でバックグラウンドに参加するもう 1 つの方法は、CTRL+Z キーを押すことです。これにより、実行中のプロセスをバックグラウンドに追加できますが、バックグラウンドに追加されたプロセスはバックグラウンドで一時停止されます。
[root@server2 ~]# sleep 10^Z [1]+ Stopped sleep 10[root@server2 ~]# jobs [1]+ Stopped sleep 10
[root@server2 ~]# sleep 30&vim /etc/my.cnf&sleep 50&[1] 8915[2] 8916[3] 8917
[root@server2 ~]# jobs [1] Running sleep 30 &[2]+ Stopped vim /etc/my.cnf [3]- Running sleep 50 &
上記の例では、次に実行されるタスクはvimですが、停止しているのは最初のプロセスが停止しているため、他のプロセスは実行されないのでしょうか?明らかにそうではありません。実際、すぐに他の 2 つのスリープ タスクが完了していることがわかりますが、vim はまだ停止状態です。
[root@server2 ~]# jobs [1] Done sleep 30[2]+ Stopped vim /etc/my.cnf [3]- Done sleep 50
[root@server2 ~]# sleep 20^Z # 按下CTRL+Z进入暂停并放入后台 [3]+ Stopped sleep 20
[root@server2 ~]# jobs [2]- Stopped vim /etc/my.cnf [3]+ Stopped sleep 20 # 此时为stopped状态
[root@server2 ~]# bg %3 # 使用bg或fg可以让暂停状态的进程变会运行态 [3]+ sleep 20 &
[root@server2 ~]# jobs [2]+ Stopped vim /etc/my.cnf [3]- Running sleep 20 & # 已经变成运行态
りー
如果不给定任何选项,该shell中所有的job都会被移除,移除是disown的默认操作,如果也没给定jobid,而且也没给定-a或-r,则表示只针对当前任务即带有"+"号的任务项。
9.3 终端和进程的关系
使用pstree命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是tty终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是ssh连接到Linux上执行的进程。
[root@server2 ~]# pstree -c | grep bash|-login---bash---bash---vim|-sshd-+-sshd---bash| `-sshd---bash-+-grep
正常情况下杀死父进程会导致子进程变为孤儿进程,即其PPID改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用nohup命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到init(或systemd)进程下执行。如:
shell> nohup tar rf a.tar.gz /tmp/*.txt
另一种方法是使用screen这个工具,该工具可以模拟多个物理终端,虽然模拟后screen进程仍然挂在其所在的终端上的,但同nohup一样,当其所在终端退出后将自动挂到init/systemd进程下继续存在,只要screen进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。它的实现方式其实和nohup差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用nohup足以。
另外,可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及daemon类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
9.4 信号
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
9.4.1 需知道的信号
Linux中支持非常多种信号,它们都以SIG字符串开头,SIG字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。但由于不少信号在不同架构的计算机上数值不同(例如CTRL+Z发送的SIGSTP信号就有三种值18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
以下是需要了解的信号。
中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+ 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean- 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-- 该信号是可被忽略的进程停止信号(CTRL+ 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & 用户自定义信号2
只有SIGKILL和SIGSTOP这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过trap或其他编程手段捕捉到或忽略掉。
更多更详细的信号理解或说明,可以参考wiki的两篇文章:
jobs控制机制:(Unix)
信号说明:
9.4.2 SIGHUP
(1).当控制终端退出时,会向该终端中的进程发送sighup信号,因此该终端上行的shell进程、其他普通进程以及任务都会收到sighup而导致进程终止。
两种方式可以改变因终端中断发送sighup而导致子进程也被结束的行为:一是使用nohup命令启动进程,它会忽略所有的sighup信号,使得该进程不会随着终端退出而结束;二是使用disown,将任务列表中的任务移除出job table或者直接使用disown -h的功能设置其不接收终端发送的sighup信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在init/systemd下。
(2).对于daemon类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是Init或systemd),它们收到sighup信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
9.4.3 僵尸进程和SIGCHLD
一个编程完善的程序,在子进程终止、退出的时候,会发送SIGCHLD信号给父进程,父进程收到信号就会通知内核清理该子进程相关信息。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了SIGCHLD信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送SIGCHLD信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短(倒霉的僵尸),几乎是不可被ps或top这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到SIGCHLD信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被ps或top捕捉到。僵尸不倒霉,人类就要倒霉,但是僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,僵尸道长即内核见不到小僵尸,所以也没法收尸。悲催的是,人类能力不足,直接发送信号(如kill)给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,不占用任何运行资源,也收不到信号,只有内核从进程列表中将僵尸进程表项移除才能收尸。
要解决掉永存的僵尸有几种方法:
(1).杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了僵尸道长的直系弟子init/systemd,init/systemd会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
(2).手动发送SIGCHLD信号给僵尸进程的父进程。僵尸道长找不到僵尸,但被僵尸祸害的人类能发现僵尸,所以人类主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
当然,第二种手动发送SIGCHLD信号的方法要求父进程能收到信号,而SIGCHLD信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般daemon类的程序在编程上都是很完善的,发送SIGCHLD总是会收到,不用担心。
9.4.4 手动发送信号(kill命令)
使用kill命令可以手动发送信号给指定的进程。
kill [-s signal] pid...kill [-signal] pid...kill -l
使用kill -l可以列出Linux中支持的信号,有64种之多,但绝大多数非编程人员都用不上。
使用-s或-signal都可以发送信号,不给定发送的信号时,默认为TREM信号,即kill -15。
shell> kill -9 pid1 pid2... shell> kill -TREM pid1 pid2... shell> kill -s TREM pid1 pid2...
9.4.5 pkill和killall
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是TERM。
(1).pkill
pkill和pgrep命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill)或列出匹配的进程(pgrep),pgrep就不介绍了。
pkill能够指定模式匹配,所以可以使用进程名来删除,想要删除指定pid的进程,反而还要使用"-s"选项来指定。默认发送的信号是SIGTERM即数值为15的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern] 选项说明:-P ppid,... :匹配PPID为指定值的进程-s pid,... :匹配PID为指定值的进程-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端-v :反向匹配-signal :指定发送的信号,可以是数值也可以是字符代表的信号
在CentOS 7上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。
例如踢出终端:
shell> pkill -t pts/0
(2).killall
killall主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser和lsof命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ... 选项说明:-I :匹配时不区分大小写-r :使用扩展正则表达式进行模式匹配-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号-u, --user :匹配该用户的进程-v, :给出详细信息-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。 如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去
9.5 fuser和lsof
fuser可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount的时候提示the device busy可以判断出来哪个进程在使用。而lsof则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以lsof出来的结果可能会非常多。
9.5.1 fuser
fuser [-ki] [-signal] file/dir-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL-i:一般和-k一起使用,指的是在kill掉pid之前询问。-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9不加选项:直接显示出文件或目录的pid
在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
c:在当前目录下
e:可被执行的
f:是一个被开启的文件或目录
F:被打开且正在写入的文件或目录
r:代表root directory
例如:
[root@xuexi ~]# fuser /usr/sbin/crond/usr/sbin/crond: 1425e
表示/usr/sbin/crond被1425这个进程打开了,后面的修饰符e表示该文件是一个可执行文件。
[root@xuexi ~]# ps aux | grep 142[5] root 1425 0.0 0.1 117332 1276 ? Ss Jun10 0:00 crond
9.5.2 lsof
例如:
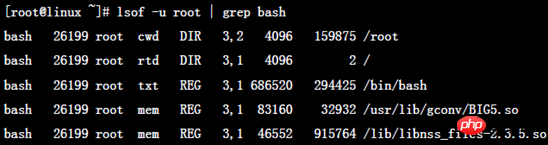
输出信息中各列意义:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
lsof的各种用法:
lsof /path/to/somefile:显示打开指定文件的所有进程之列表;建议配合grep使用 lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;可多次使用该选项lsof -p PID:查看该进程打开了哪些文件lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -Ulsof -u uid/name:显示指定用户的进程打开的文件;可使用脱字符"^"取反,如"lsof -u ^root"将显示非root用户打开的所有文件lsof +d /DIR/:显示指定目录下被进程打开的文件 lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢 lsof -a:按"与"组合多个条件,如lsof -a -c apache -u apache lsof -N:列出所有NFS(网络文件系统)文件 lsof -n:不反解IP至HOSTNAME lsof -i:用以显示符合条件的进程情况lsof -i[46] [protocol][@host][:service|port]46:IPv4或IPv6 protocol:TCP or UDP host:host name或ip地址,表示搜索哪台主机上的进程信息 service:服务名称(可以不只一个) port:端口号 (可以不只一个)
大概"-i"是使用最多的了,而"-i"中使用最多的又是服务名或端口了。
[root@www ~]# lsof -i :22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 1390 root 3u IPv4 13050 0t0 TCP *:ssh (LISTEN) sshd 1390 root 4u IPv6 13056 0t0 TCP *:ssh (LISTEN) sshd 36454 root 3r IPv4 94352 0t0 TCP xuexi:ssh->172.16.0.1:50018 (ESTABLISHED)
回到系列文章大纲:
转载请注明出处:
以上がLinuxのプロセスとシグナルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。