
ホームページ >運用・保守 >Linuxの運用と保守 >外部ファイルシステムのメカニズム
外部ファイルシステムのメカニズム
- 巴扎黑オリジナル
- 2017-06-23 14:19:292308ブラウズ
この記事のディレクトリ:
4.1 ファイルシステムのコンポーネント
4.2 ファイルシステムの完全な構造
4.3 データブロック
4.4 inodeの基礎知識
4.5 inodeの詳細
4.6 単一ファイルシステムにおけるファイル操作の原則
4.7 マルチファイルシステムの関連付け
4.8 ext3 ファイルシステムのロギング機能 4.9 ext4 ファイルシステム ディスクのパーティショニングとは、ディスクの表面を物理的に分割することです。パーティションを分割した後、使用する前にフォーマットしてからマウントする必要があります (他の方法は考慮されていません)。パーティションをフォーマットするプロセスでは、実際にはファイル システムが作成されます。 CentOS 5 および CentOS 6 ではデフォルトで使用される ext2/ext3/ext4、CentOS 7 ではデフォルトで使用される xfs、Windows では NTFS、CD タイプのファイル システム ISO9660、MAC ではハイブリッドなど、多くの種類のファイル システムがあります。ファイルシステムHFS、ネットワークファイルシステムNFS、Oracleが開発したbtrfs、昔ながらのFAT/FAT32など。
この記事では、ext ファミリ ファイル システムを非常に包括的かつ詳細に紹介します。 ext2/ext3/ext4 があります。ext3 はログ付きの ext2 の改良版であり、ext3 と比較して多くの改良が加えられています。 xfs/btrfs などのファイルシステムは異なりますが、実装方法が異なるだけで、それぞれの特徴が異なります。
4.1 ファイルシステムの構成要素4.1.1 ブロックの出現 ハードディスクの読み取りおよび書き込み IO は、1 セクターあたり 512 バイトです。大量のファイルを読み書きしたい場合は、セクター単位は間違いなく非常に遅くなり、多くのパフォーマンスを消費するため、Linux はファイル システム制御を通じて読み取りおよび書き込み単位として「ブロック」を使用します。現在のファイル システムでは、ブロック サイズは通常 1024 バイト (1K)、2048 バイト (2K)、または 4096 バイト (4K) です。たとえば、1 つ以上のブロックを読み取る必要がある場合、ファイル システムの IO マネージャーは、どのデータ ブロックを読み取る必要があるかをディスク コントローラーに通知し、ハードディスク コントローラーはこれらのブロックをセクターごとに読み取り、これらのセクターをサーバー経由で転送します。ハードディスク コントローラ データが再構築されてコンピュータに返されます。
ブロックの出現により、ファイルシステムレベルでの読み取りおよび書き込みパフォーマンスが大幅に向上し、断片化が大幅に減少します。ただし、副作用として、スペースが無駄に消費される可能性があります。ファイル システムは読み取りおよび書き込みの単位としてブロックを使用するため、保存されているファイルのサイズが 1K しかない場合でも、1 ブロックを占有し、残りの領域は完全に無駄になります。特定のビジネス ニーズでは、多数の小さなファイルが保存される場合があり、これにより多くのスペースが無駄になります。欠点もありますが、その利点は明らかです。安価なハードディスク容量とパフォーマンスの追求の時代では、ブロックの使用は必須です。 4.1.2 inode の登場
保存されたファイルの読み取りに大量のブロックが必要な場合はどうなるでしょうか?ブロック サイズが 1KB の場合、10M ファイルを保存するだけで 10240 ブロックが必要ですが、これらのブロックは位置的に不連続である可能性が高く (隣接していません)、ファイルを読み取るときにファイル全体を前から後ろのブロックにスキャンする必要がありますか?ファイル システムのどのブロックがそのファイルに属しているかを調べますか?明らかに、これは遅すぎて愚かな行為であるため、行うべきではありません。もう一度考えてみましょう。1 ブロックしか占有しないファイルを読み込む場合、1 ブロックだけ読み取ったら終了ですか?いいえ、ファイル システム全体のすべてのブロックをスキャンします。いつスキャンされるかが分からず、スキャン後にファイルが完了し、他のブロックをスキャンする必要がないかどうかも分からないためです。さらに、各ファイルには属性 (アクセス許可、サイズ、タイムスタンプなど) があり、これらの属性クラスのメタデータはどこに保存されますか?ファイルのデータ部分もブロックに保存されますか?ファイルが複数のブロックを占める場合、ファイルに属する各ブロックにファイルのメタデータを保存する必要がありますか?しかし、ファイル システムが各ブロックにメタデータを保存しない場合、特定のブロックがそのファイルに属しているかどうかをどうやって知ることができるのでしょうか?しかし、明らかに、各データ ブロックにメタデータのコピーを保存するのはスペースの無駄です。
もちろん、ファイル システムの設計者は、この保存方法が理想的ではないことを知っているため、保存方法を最適化する必要があります。最適化するにはどうすればよいですか?この同様の問題に対する解決策は、インデックスを使用して、インデックスをスキャンすることで対応するデータを見つけることです。インデックスはデータの一部を格納できます。
ファイル システムでは、インデックス作成テクノロジはインデックス ノードとして実現され、インデックス ノードに保存されるデータの一部は、ファイルの属性メタデータとその他の少量の情報です。一般に、インデックスが占めるスペースは、インデックスを作成するファイル データのスペースよりもはるかに小さく、データ全体をスキャンするよりもはるかに高速です。そうでない場合、インデックスは意味を持ちません。これで以前の問題はすべて解決されました。
ファイル システム用語では、インデックス ノードは i ノードと呼ばれます。 i ノード番号、ファイル タイプ、権限、ファイル所有者、サイズ、タイムスタンプなどのメタデータ情報が i ノードに保存されます。最も重要なことは、ファイルに属するブロックへのポインタも保存されることです。 inode を参照すると、ファイルに属するブロックを見つけて、これらのブロックを読み取ってファイルのデータを取得できます。ポインタの一種は後で紹介するので、名前と区別の便宜上、当面、この inode レコード内のファイル データ ブロックを指すポインタをブロック ポインタと呼びます。
一般に、inode サイズは 128 バイトまたは 256 バイトで、MB または GB で計算されるファイル データよりもはるかに小さいですが、ファイルのサイズが i ノード サイズよりも小さい可能性があることも知っておく必要があります。たとえば、次のようになります。セクションファイルは 1 ワードのみを占めます。
4.1.3 bmap が表示されます
データをハードディスクに保存するとき、ファイル システムはどのブロックが空いていて、どのブロックが占有されているかを知る必要があります。もちろん、最も愚かな方法は、前から後ろにスキャンし、空きブロックが見つかったときにその一部を保存し、すべてのデータが保存されるまでスキャンを続けることです。
もちろん、最適化方法ではインデックスの使用も検討できますが、合計 1KB ブロックが 1024*1024=1048576 になるのは 1G のみです。これが 100G、500G、またはそれ以上の場合は、そのまま使用してください。このとき、占有されるインデックスの数とスペースも非常に大きくなります。ブロック ビットマップ (ビットマップは bmap と呼ばれます) を使用する方法が登場します。
ビットマップは、対応するブロックが空いているか占有されているかを識別するために 0 と 1 のみを使用します。ビットマップ内の 0 と 1 の位置は、最初のブロックを識別し、2 番目のビットはブロックを識別します。 2 つのブロック。すべてのブロックがマークされるまで順番に進みます。
ブロック ビットマップがより最適化される理由を考えてみましょう。ビットマップには 1 バイトに 8 ビットがあり、8 つのブロックを識別できます。ブロック サイズが 1KB、容量が 1G のファイル システムの場合、ブロック数は 1024*1024 であるため、ビットマップでは 1024*1024 ビットが使用され、合計 1024*1024/8=131072 バイト = 128K、これは 1G です。1 対 1 の対応を完了するには、ファイルにビットマップとして 128 ブロックだけが必要です。これらの100以上のブロックをスキャンすることで、どのブロックが空いているかが分かり、速度が大幅に向上します。
ただし、bmap の最適化は書き込みの最適化を目的としていることに注意してください。書き込みのみに空きブロックを見つけて空きブロックを割り当てる必要があるためです。読み取りの場合、ブロックの位置が inode を通じて検出される限り、CPU は物理ディスク上のブロックのアドレスを迅速に計算できます。ブロック アドレスの計算時間は非常に高速です。読み込み速度はほとんど無視できるほどなので、基本的にはハードディスク自体の性能に影響され、ファイルシステムとは関係ないと考えられます。
bmap はスキャンを大幅に最適化しましたが、依然としてボトルネックがあります。ファイル システムが 100G の場合はどうなるでしょうか? 100G ファイル システムは 128*100=12800 の 1KB ブロックを使用し、12.5M のスペースを占有します。不連続である可能性が高い 12,800 ブロックを完全にスキャンするには時間がかかることを想像してください。高速ではありますが、ファイルを保存するたびにスキャンするという膨大なオーバーヘッドに耐えることはできません。
それでは再度最適化する必要があります。最適化するにはどうすればよいでしょうか?つまり、ファイル システムはブロック グループに分割されます。ブロック グループの紹介は後で説明します。
4.1.4 i ノード テーブルの出現
i ノード関連の情報を確認してください。inode には、inode 番号、ファイル属性メタデータ、およびファイルが占有するブロックへのポインタが格納され、各 i ノードは 128 バイトまたは 256 バイトを占有します。
ここで、別の問題が発生します。ファイル システムには無数のファイルが存在する可能性がありますが、各ファイルは 128 バイトの i ノードに対応してストレージ用に個別のブロックを占有する必要があるのでしょうか。これはとてもスペースの無駄です。
したがって、より良い方法は、複数の i ノードを組み合わせて 1 つのブロックに格納することです。128 バイトの i ノードの場合、1 つのブロックには 8 つの i ノードが格納されます。これにより、inode を格納する各ブロックが無駄にならないようになります。
ext ファイル システムでは、inode を物理的に格納するこれらのブロックが結合されて、すべての i ノードを記録するための i ノード テーブルが論理的に形成されます。 例えば、各家族は警察署に戸籍情報を登録しなければなりません。各町や通りの警察署は、その町や通りのすべての戸籍を統合して、世帯の住所を知ることができます。世帯の住所を入力すると、警察署ですぐに見つけることができます。 inode テーブルはここでは警察署です。その内容を以下に示します。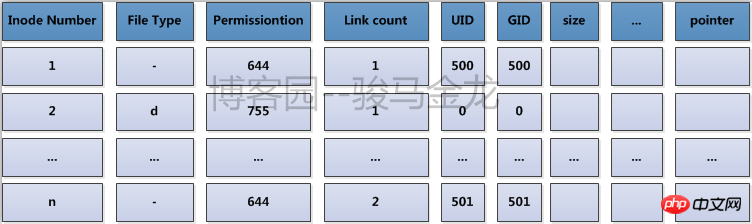
必要なのは 1 つのデータ、つまり各ブロックのサイズを決定し、bmap が最大 1 つの完全なブロックのみを占有することができるという基準に基づいてブロック グループを分割する方法を計算するだけです。ファイル システムが非常に小さく、すべての bmap が合計 1 つのブロックを占有することができない場合は、bmap ブロックを解放することしかできません。
各ブロックのサイズは、ファイルシステムの作成時に手動で指定できます。指定しない場合はデフォルト値もあります。 現在のブロック サイズが 1KB の場合、1 つのブロックを完全に占有する bmap は 1024*8= 8192 ブロックを識別できます (もちろん、これらの 8192 ブロックは、合計 8192 のデータ領域とメタデータ領域です。なぜなら、ブロックはメタデータに割り当てられているためです)エリアもbmapで特定する必要があります)。各ブロックは 1K、各ブロック グループは 8192K または 8M です。1G ファイル システムを作成するには、1024/8 = 128 個のブロック グループに分割する必要があります。1.1G ファイル システムの場合はどうなるでしょうか。 128+12.8=128+13=141 ブロック グループ。 各グループのブロック数が分かれていますが、各グループのinode番号はいくつ設定されるのでしょうか? inode テーブルは何ブロックを占有しますか? 「データ領域内の何個のブロックに i ノード番号が割り当てられるか」を表すインジケーターはデフォルトでは不明であるため、これはシステムによって決定される必要があります。 もちろん、このインジケーターまたはパーセンテージは、ファイルの作成時に手動で指定することもできます。システム。以下の「i ノードの深さ」を参照してください。ext クラスのすべてのファイル システム情報を表示するには、dumpe2fs を使用します。 もちろん、bmap はブロック グループごとに 1 つのブロックを固定し、表示する必要はありません。そのため、imap は 1 ブロックしか占有せず、表示する必要はありません。を表示する必要があります。
下の図はファイルシステムの情報の一部を示しており、この情報の背後に各ブロックグループの情報があります。
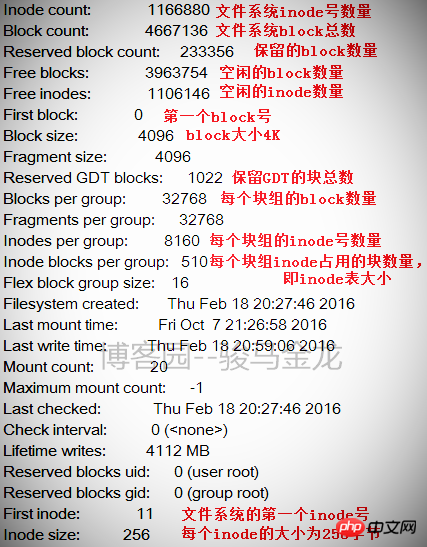
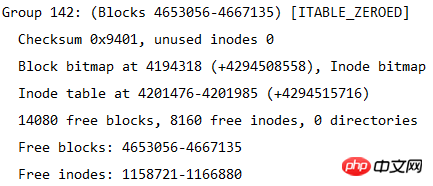
ファイル システムのサイズは、この表から計算できます。ファイル システムには合計 4667136 ブロックがあり、各ブロックのサイズは 4K であるため、ファイル システムのサイズは 4667136*4/1024/1024=17.8 となります。 GB。
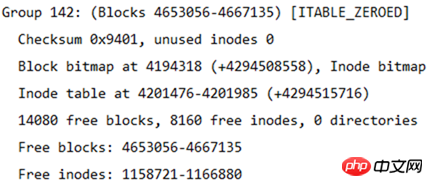
各ブロック グループのブロック数は 32768 であるため、ブロック グループが何個に分割されるかを計算することもできます。つまり、ブロック グループの数は 4667136/32768=142.4、つまり 143 ブロック グループになります。ブロック グループには 0 から始まる番号が付けられるため、最後のブロック グループ番号はグループ 142 になります。下図に示すように、最後のブロックグループの情報が表示されます。
4.2 ファイルシステムの完全な構造
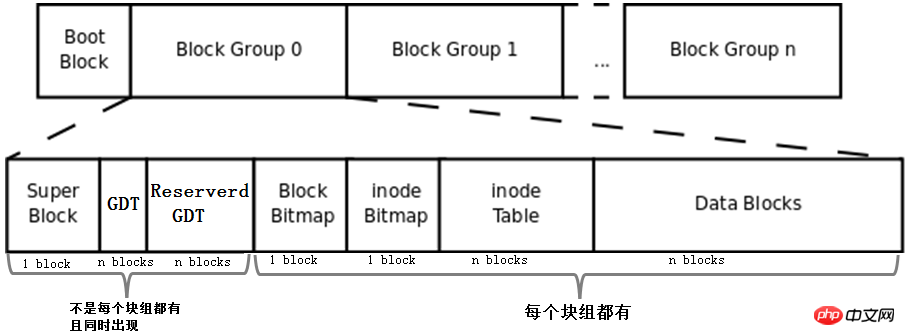
上記で説明した bmap、inode テーブル、imap、データ領域ブロック、およびブロック グループの概念を組み合わせることで、ファイル システムが形成されます。ファイルシステム。完全なファイル システムを以下に示します。
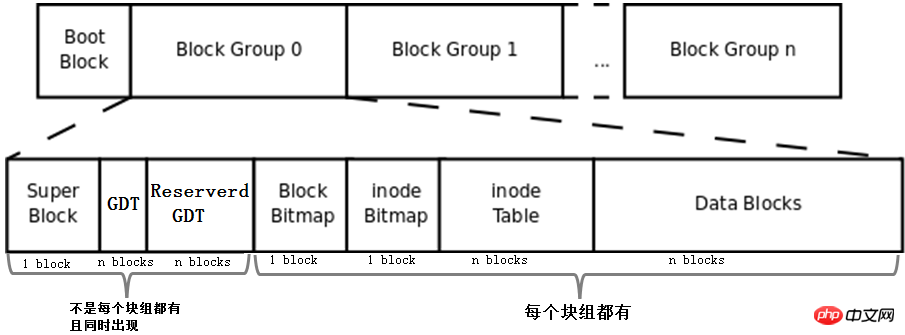
まず、この図にBoot Block、Super Block、GDT、Reserve GDTの概念を追加します。以下に分けて紹介します。
そして、図はブロックグループ内の各部分が占めるブロックの数を示しています。superblock、bmap、imapは1ブロックを占有していると判断できますが、他の部分は複数のブロックを占有していると判断できません。
最後に、この図は、Superblock、GDT、および Reserved GDT が同時に出現し、各ブロック グループに必ずしも存在するわけではないことを示しています。また、各ブロック グループに bmap、imap、inode テーブル、およびデータ ブロックが存在することも示しています。
4.2.1 ブート ブロック
は、上の図のブート ブロック部分であり、ブート セクターとも呼ばれます。これはパーティションの最初のブロックにあり、1024 バイトを占有します。すべてのパーティションにこのブート セクタがあるわけではありません。ブート ローダーもそこに格納されます。このブート ローダーは VBR になります。ここのブート ローダーと mbr 上のブート ローダーの間には時差関係があります。起動するときは、まず mbr にブートローダーをロードし、次にオペレーティング システムが配置されているパーティションのブート サークタを見つけて、ここにブート ローダーをロードします。複数のシステムがある場合、mbr にブートローダーをロードすると、オペレーティング システム メニューがリストされ、メニュー上の各オペレーティング システムは、それらが配置されているパーティションのブート セクタを指します。両者の関係を下図に示します。
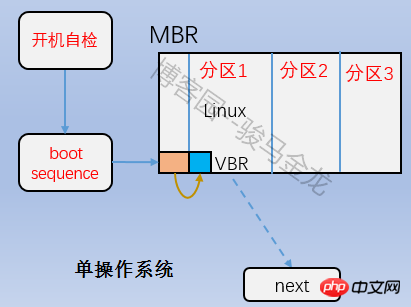
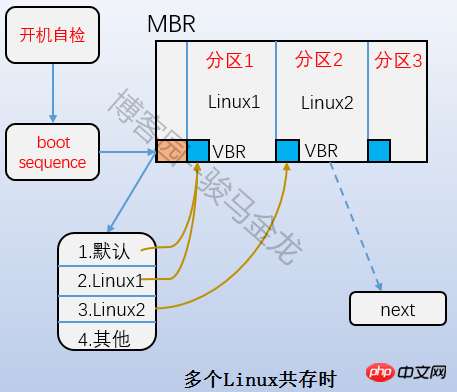
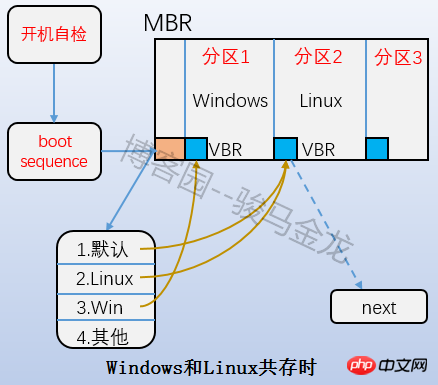
4.2.2 スーパーブロック
ファイルシステムは複数のブロックグループに分割されているため、ファイルシステムはどのようにしてブロックグループの数を知ることができるのでしょうか?各ブロック グループにはブロックの数、inode 番号、その他の情報がいくつありますか?また、各種タイムスタンプ、総ブロック数と空きブロック数、総ブロック数と空きinode数、現在のファイルシステムが正常かどうか、自己起動時にファイルシステム自体の属性情報を取得します。テストが必要など、どこに保存されていますか?
この情報がブロックに保存される必要があることに疑いの余地はありません。この情報を格納するには 1024KB を占有するため、ブロックも必要です。このブロックはスーパーブロックと呼ばれ、そのブロック番号は 0 または 1 です。 ブロック サイズが 1024K の場合、ブート ブロックは 1 つのブロックを占有します。このブロック番号は 0 であるため、スーパーブロック番号は 1 になります。ブロック サイズが 1024K を超える場合、ブート ブロックとスーパー ブロックは同じ場所に配置されます。このブロック番号は 0 です。つまり、スーパーブロックの開始位置と終了位置は 2 番目の 1024 (1024-2047) バイトです。
df コマンドを使用すると、各ファイル システムのスーパーブロックが読み取られるため、統計が非常に高速になります。逆に、du コマンドを使用して大きなディレクトリの使用済み領域を表示すると、ディレクトリ全体のすべてのファイルを走査する必要があるため、非常に時間がかかります。
スーパーブロックはファイルシステムにとって重要です。スーパーブロックの損失または損傷は、間違いなくファイルシステムに損傷を与えます。したがって、古いファイル システムはスーパー ブロックを各ブロック グループにバックアップしますが、これはスペースの無駄であるため、ext2 ファイル システムはブロック グループ 0、1 と 3、5、および 7 のパワー ブロック グループにのみスーパー ブロックを保存します。 . Group9、Group25 などのブロック情報。非常に多くのスーパーブロックが保存されていますが、ファイル システムは最初のブロック グループである Group0 のスーパーブロック情報のみを使用してファイル システム属性を取得します。Group0 のスーパーブロックが破損または紛失した場合にのみ、次のバックアップ スーパーブロックを見つけてコピーします。 Group0。ファイルシステムを復元します。
下の図は、ext4 ファイル システムのスーパーブロック情報を示しています。すべての ext ファミリ ファイル システムは、dumpe2fs -h を使用して取得できます。

4.2.3 ブロックグループ記述子テーブル(GDT)
ファイルシステムはブロックグループに分割されているため、各ブロックグループの情報と属性メタデータはどこに格納されますか?
ext ファイルシステム内の各ブロックグループ情報は 32 バイトで記述され、この 32 バイトはブロックグループ記述子と呼ばれ、ブロックグループ記述子テーブル GDT (グループ記述子テーブル) を構成します。
各ブロック グループには、ブロック グループの情報と属性メタデータを記録するためにブロック グループ記述子が必要ですが、すべてのブロック グループがブロック グループ記述子を保存するわけではありません。 ext ファイルシステムの保存方法は、GDT を作成し、その GDT を特定のブロック グループに保存することです。GDT を保存するブロック グループは、スーパーブロックとバックアップ スーパーブロックを保存するブロックと同じです。ブロックグループ内の特定のブロックグループ。
ブロック サイズが 4KB のファイル システムが 143 のブロック グループに分割され、各ブロック グループ記述子が 32 バイトの場合、GDT は 143*32=4576 バイト、つまり 2 ブロックを保存する必要があります。この2つのGDTブロックには、全ブロックグループのブロックグループ情報が記録されており、GDTが格納されているブロックグループ内のGDTは全く同一である。
下の図は、ブロックグループ記述子の情報です(dumpe2fsを通じて取得)。
4.2.4 予約済み GDT (予約済み GDT)
将来のファイル システム拡張のために予約された GDT。拡張後にブロック グループが多すぎて、ブロック グループ記述子が現在 GDT を格納しているブロックを超えることを防ぎます。 GDT と GDT は常に同時に出現するようにし、もちろんスーパーブロックと同時に出現します。
たとえば、最初の 143 ブロック グループは GDT を保存するために 2 ブロックを使用しますが、この時点では 2 番目のブロックにはまだ多くの空き領域があり、ある程度容量が拡張されると、2 ブロックでは記録できなくなります。現時点では、余分なブロック グループ記述子を格納するために 1 つ以上の予約済み GDT ブロックを割り当てる必要があります。
新たに追加された GDT ブロックにより、この GDT ブロックは GDT を格納する各ブロック グループに同時に追加される必要があるため、予約された GDT と GDT が同じブロック グループに格納されている場合は、予約された GDT を直接追加することができます。非効率的なコピー方法を使用して、GDT を格納する各ブロック グループをバックアップします。
同様に、新しく追加された GDT は、各ブロック グループのスーパーブロック内のファイル システム属性を変更する必要があるため、スーパーブロックと予約済み GDT/GDT を一緒に配置すると効率が向上します。
4.3 データブロック
上の図に示すように、データブロックを除いた他の部分について説明しました。データブロックはデータを直接格納するブロックですが、実際はそれほど単純ではありません。
データが占めるブロックは、ファイルに対応する inode レコード内のブロック ポインターによって見つかります。ファイルの種類が異なれば、データ ブロックに格納される内容も異なります。 Linux でさまざまな種類のファイルがどのように保存されるかを次に示します。
通常のファイルの場合、ファイルのデータは通常データブロックに保存されます。
ディレクトリの場合、そのディレクトリの下にあるすべてのファイルと第 1 レベルのサブディレクトリのディレクトリ名がデータ ブロックに保存されます。
ファイル名は、それ自体の i ノードには保存されませんが、ファイルが配置されているディレクトリのデータ ブロックに保存されます。
シンボリック リンクの場合、ターゲット パス名が短い場合は、検索を高速化するために i ノードに直接保存されます。ターゲット パス名が長い場合は、それを保存するためにデータ ブロックが割り当てられます。
デバイスファイル、FIFO、ソケットなどの特殊ファイルにはデータブロックがありません。デバイスファイルのメジャーデバイス番号とマイナーデバイス番号はinodeに格納されます。
通常のファイルの保存方法については説明しません。特殊ファイルの保存方法については後述します。
4.3.1 ディレクトリファイルのデータブロック
ディレクトリファイルの場合、inodeレコードにはディレクトリのinode番号、ディレクトリの属性メタデータ、およびディレクトリファイルのブロックポインタが格納されます。 ファイルに関する情報はありません。ディレクトリ自体の名前。
そのデータブロックの保存方法は下図の通りです。
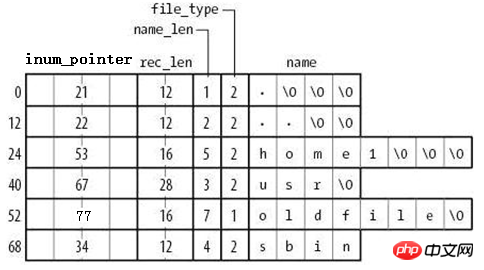
由图可知,在目录文件的数据块中存储了其下的文件名、目录名、目录本身的相对名称"."和上级目录的相对名称"..",还存储了指向inode table中这些文件名对应的inode号的指针(并非直接存储inode号码)、目录项长度rec_len、文件名长度name_len和文件类型file_type。注意到除了文件本身的inode记录了文件类型,其所在的目录的数据块也记录了文件类型。由于rec_len只能是4的倍数,所以需要使用"\0"来填充name_len不够凑满4倍数的部分。至于rec_len具体是什么,只需知道它是一种偏移即可。
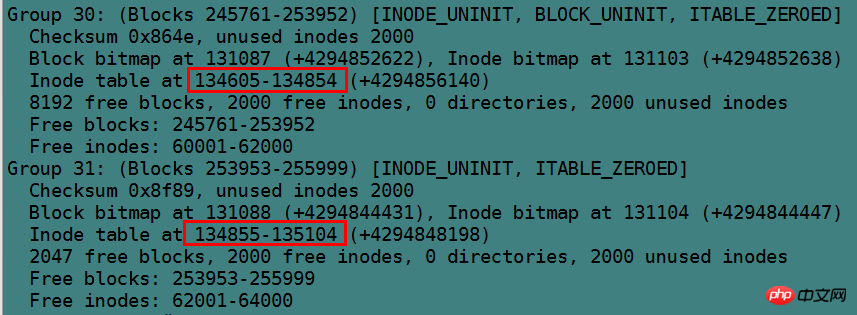
目录的data block中并没有直接存储目录中文件的inode号,它存储的是指向inode table中对应文件inode号的指针,暂且称之为inode指针(至此,已经知道了两种指针:一种是inode table中每个inode记录指向其对应data block的block指针,一个此处的inode指针)。一个很有说服力的例子,在目录只有读而没有执行权限的时候,使用"ls -l"是无法获取到其内文件inode号的,这就表明没有直接存储inode号。实际上,因为在创建文件系统的时候,inode号就已经全部划分好并在每个块组的inode table中存放好,inode table在块组中是有具体位置的,如果使用dumpe2fs查看文件系统,会发现每个块组的inode table占用的block数量是完全相同的,如下图是某分区上其中两个块组的信息,它们都占用249个block。
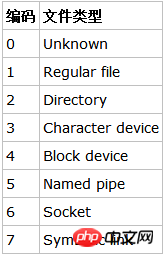
除了inode指针,目录的data block中还使用数字格式记录了文件类型,数字格式和文件类型的对应关系如下图。
注意到目录的data block中前两行存储的是目录本身的相对名称"."和上级目录的相对名称"..",它们实际上是目录本身的硬链接和上级目录的硬链接。硬链接的本质后面说明。
由此也就容易理解目录权限的特殊之处了。目录文件的读权限(r)和写权限(w),都是针对目录文件的数据块本身。由于目录文件内只有文件名、文件类型和inode指针,所以如果只有读权限,只能获取文件名和文件类型信息,无法获取其他信息,尽管目录的data block中也记录着文件的inode指针,但定位指针是需要x权限的,因为其它信息都储存在文件自身对应的inode中,而要读取文件inode信息需要有目录文件的执行权限通过inode指针定位到文件对应的inode记录上。以下是没有目录x权限时的查询状态,可以看到除了文件名和文件类型,其余的全是"?"。
[lisi4@xuexi tmp]$ ll -i d ls: cannot access d/hehe: Permission denied ls: cannot access d/haha: Permission denied total 0? d????????? ? ? ? ? ? haha? -????????? ? ? ? ? ? hehe
注意,xfs文件系统和ext文件系统不一样,它连文件类型都无法获取。
4.3.2 符号链接存储方式
符号链接即为软链接,类似于Windows操作系统中的快捷方式,它的作用是指向原文件或目录。
软链接之所以也被称为特殊文件的原因是:它一般情况下不占用data block,仅仅通过它对应的inode记录就能将其信息描述完成;符号链接的大小是其指向目标路径占用的字符个数,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",则其文件大小为11字节;只有当符号链接指向的目标的路径名较长(60个字节)时文件系统才会划分一个data block给它;它的权限如何也不重要,因它只是一个指向原文件的"工具",最终决定是否能读写执行的权限由原文件决定,所以很可能ls -l查看到的符号链接权限为777。
注意,软链接的block指针存储的是目标文件名。也就是说,链接文件的一切都依赖于其目标文件名。这就解释了为什么/mnt的软链接/tmp/mnt在/mnt挂载文件系统后,通过软链接就能进入/mnt所挂载的文件系统。究其原因,还是因为其目标文件名"/mnt"并没有改变。
例如以下筛选出了/etc/下的符号链接,注意观察它们的权限和它们占用的空间大小。
[root@xuexi ~]# ll /etc/ | grep '^l'lrwxrwxrwx. 1 root root 56 Feb 18 2016 favicon.png -> /usr/share/icons/hicolor/16x16/apps/system-logo-icon.png lrwxrwxrwx. 1 root root 22 Feb 18 2016 grub.conf -> ../boot/grub/grub.conf lrwxrwxrwx. 1 root root 11 Feb 18 2016 init.d -> rc.d/init.d lrwxrwxrwx. 1 root root 7 Feb 18 2016 rc -> rc.d/rc lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc0.d -> rc.d/rc0.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc1.d -> rc.d/rc1.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc2.d -> rc.d/rc2.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc3.d -> rc.d/rc3.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc4.d -> rc.d/rc4.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc5.d -> rc.d/rc5.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc6.d -> rc.d/rc6.d lrwxrwxrwx. 1 root root 13 Feb 18 2016 rc.local -> rc.d/rc.local lrwxrwxrwx. 1 root root 15 Feb 18 2016 rc.sysinit -> rc.d/rc.sysinit lrwxrwxrwx. 1 root root 14 Feb 18 2016 redhat-release -> centos-release lrwxrwxrwx. 1 root root 11 Apr 10 2016 rmt -> ../sbin/rmt lrwxrwxrwx. 1 root root 14 Feb 18 2016 system-release -> centos-release
4.3.3 设备文件、FIFO、套接字文件
关于这3种文件类型的文件只需要通过inode就能完全保存它们的信息,它们不占用任何数据块,所以它们是特殊文件。
设备文件的主设备号和次设备号也保存在inode中。以下是/dev/下的部分设备信息。注意到它们的第5列和第6列信息,它们分别是主设备号和次设备号,主设备号标识每一种设备的类型,次设备号标识同种设备类型的不同编号;也注意到这些信息中没有大小的信息,因为设备文件不占用数据块所以没有大小的概念。
[root@xuexi ~]# ll /dev | tailcrw-rw---- 1 vcsa tty 7, 129 Oct 7 21:26 vcsa1 crw-rw---- 1 vcsa tty 7, 130 Oct 7 21:27 vcsa2 crw-rw---- 1 vcsa tty 7, 131 Oct 7 21:27 vcsa3 crw-rw---- 1 vcsa tty 7, 132 Oct 7 21:27 vcsa4 crw-rw---- 1 vcsa tty 7, 133 Oct 7 21:27 vcsa5 crw-rw---- 1 vcsa tty 7, 134 Oct 7 21:27 vcsa6 crw-rw---- 1 root root 10, 63 Oct 7 21:26 vga_arbiter crw------- 1 root root 10, 57 Oct 7 21:26 vmci crw-rw-rw- 1 root root 10, 56 Oct 7 21:27 vsock crw-rw-rw- 1 root root 1, 5 Oct 7 21:26 zero
4.4 inode基础知识
每个文件都有一个inode,在将inode关联到文件后系统将通过inode号来识别文件,而不是文件名。并且访问文件时将先找到inode,通过inode中记录的block位置找到该文件。
4.4.1 硬链接
虽然每个文件都有一个inode,但是存在一种可能:多个文件的inode相同,也就即inode号、元数据、block位置都相同,这是一种什么样的情况呢?能够想象这些inode相同的文件使用的都是同一条inode记录,所以代表的都是同一个文件,这些文件所在目录的data block中的inode指针目的地都是一样的,只不过各指针对应的文件名互不相同而已。这种inode相同的文件在Linux中被称为"硬链接"。
硬链接文件的inode都相同,每个文件都有一个"硬链接数"的属性,使用ls -l的第二列就是被硬链接数,它表示的就是该文件有几个硬链接。
[root@xuexi ~]# ls -l total 48drwxr-xr-x 5 root root 4096 Oct 15 18:07 700-rw-------. 1 root root 1082 Feb 18 2016 anaconda-ks.cfg-rw-r--r-- 1 root root 399 Apr 29 2016 Identity.pub-rw-r--r--. 1 root root 21783 Feb 18 2016 install.log-rw-r--r--. 1 root root 6240 Feb 18 2016 install.log.syslog
例如下图描述的是dir1目录中的文件name1及其硬链接dir2/name2,右边分别是它们的inode和datablock。这里也看出了硬链接文件之间唯一不同的就是其所在目录中的记录不同。注意下图中有一列Link Count就是标记硬链接数的属性。

每创建一个文件的硬链接,实质上是多一个指向该inode记录的inode指针,并且硬链接数加1。
删除文件的实质是删除该文件所在目录data block中的对应的inode指针,所以也是减少硬链接次数,由于block指针是存储在inode中的,所以不是真的删除数据,如果仍有其他指针指向该inode,那么该文件的block指针仍然是可用的。当硬链接次数为1时再删除文件就是真的删除文件了,此时inode记录中block指针也将被删除。
不能跨分区创建硬链接,因为不同文件系统的inode号可能会相同,如果允许创建硬链接,复制到另一个分区时inode可能会和此分区已使用的inode号冲突。
硬链接只能对文件创建,无法对目录创建硬链接。之所以无法对目录创建硬链接,是因为文件系统已经把每个目录的硬链接创建好了,它们就是相对路径中的"."和"..",分别标识当前目录的硬链接和上级目录的硬链接。每一个目录中都会包含这两个硬链接,它包含了两个信息:(1)一个没有子目录的目录文件的硬链接数是2,其一是目录本身,其二是".";(2)一个包含子目录的目录文件,其硬链接数是2+子目录数,因为每个子目录都关联一个父目录的硬链接".."。很多人在计算目录的硬链接数时认为由于包含了"."和"..",所以空目录的硬链接数是2,这是错误的,因为".."不是本目录的硬链接。另外,还有一个特殊的目录应该纳入考虑,即"/"目录,它自身是一个文件系统的入口,是自引用(下文中会解释自引用)的,所以"/"目录下的"."和".."的inode号相同,硬链接数除去其内的子目录后应该为3,但结果是2,不知为何?
[root@xuexi ~]# ln /tmp /mydataln: `/tmp': hard link not allowed for directory
为什么文件系统自己创建好了目录的硬链接就不允许人为创建呢?从"."和".."的用法上考虑,如果当前目录为/usr,我们可以使用"./local"来表示/usr/local,但是如果我们人为创建了/usr目录的硬链接/tmp/husr,难道我们也要使用"/tmp/husr/local"来表示/usr/local吗?这其实已经是软链接的作用了。若要将其认为是硬链接的功能,这必将导致硬链接维护的混乱。
不过,通过mount工具的"--bind"选项,可以将一个目录挂载到另一个目录下,实现伪"硬链接",它们的内容和inode号是完全相同的。
硬链接的创建方法:ln file_target link_name。
4.4.2 软链接
软链接就是字符链接,链接文件默认指的就是字符文件,使用"l"表示其类型。
软链接在功能上等价与Windows系统中的快捷方式,它指向原文件,原文件损坏或消失,软链接文件就损坏。可以认为软链接inode记录中的指针内容是目标路径的字符串。
创建方式:ln –s file_target softlink_name
查看软链接的值:readlink softlink_name
在设置软链接的时候,target虽然不要求是绝对路径,但建议给绝对路径。是否还记得软链接文件的大小?它是根据软链接所指向路径的字符数计算的,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",它的文件大小为11字节,也就是说只要建立了软链接后,软链接的指向路径是不会改变的,仍然是"../sbin/rmt"。如果此时移动软链接文件本身,它的指向是不会改变的,仍然是11个字符的"../sbin/rmt",但此时该软链接父目录下可能根本就不存在/sbin/rmt,也就是说此时该软链接是一个被破坏的软链接。
4.5 inode深入
4.5.1 inode大小和划分
inode大小为128字节的倍数,最小为128字节。它有默认值大小,它的默认值由/etc/mke2fs.conf文件中指定。不同的文件系统默认值可能不同。
[root@xuexi ~]# cat /etc/mke2fs.conf
[defaults]
base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
enable_periodic_fsck = 1blocksize = 4096inode_size = 256inode_ratio = 16384[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
inode_size = 256}同样观察到这个文件中还记录了blocksize的默认值和inode分配比率inode_ratio。inode_ratio=16384表示每16384个字节即16KB就分配一个inode号,由于默认blocksize=4KB,所以每4个block就分配一个inode号。当然分配的这些inode号只是预分配,并不真的代表会全部使用,毕竟每个文件才会分配一个inode号。但是分配的inode自身会占用block,而且其自身大小256字节还不算小,所以inode号的浪费代表着空间的浪费。
既然知道了inode分配比率,就能计算出每个块组分配多少个inode号,也就能计算出inode table占用多少个block。
如果文件系统中大量存储电影等大文件,inode号就浪费很多,inode占用的空间也浪费很多。但是没办法,文件系统又不知道你这个文件系统是用来存什么样的数据,多大的数据,多少数据。
当然inodesize、inode分配比例、blocksize都可以在创建文件系统的时候人为指定。
4.5.2 ext文件系统预留的inode号
Ext预留了一些inode做特殊特性使用,如下:某些可能并非总是准确,具体的inode号对应什么文件可以使用"find / -inum NUM"查看。
Ext4的特殊inode
Inode号 用途
0 不存在0号inode
1 虚拟文件系统,如/proc和/sys
2 根目录
3 ACL索引
4 ACL数据
5 Boot loader
6 未删除的目录
7 预留的块组描述符inode
8 日志inode
11 第一个非预留的inode,通常是lost+found目录
所以在ext4文件系统的dumpe2fs信息中,能观察到fisrt inode号可能为11也可能为12。
并且注意到"/"的inode号为2,这个特性在文件访问时会用上。
需要注意的是,每个文件系统都会分配自己的inode号,不同文件系统之间是可能会出现使用相同inode号文件的。例如:
[root@xuexi ~]# find / -ignore_readdir_race -inum 2 -ls 2 4 dr-xr-xr-x 22 root root 4096 Jun 9 09:56 / 2 2 dr-xr-xr-x 5 root root 1024 Feb 25 11:53 /boot 2 0 c--------- 1 root root Jun 7 02:13 /dev/pts/ptmx 2 0 -rw-r--r-- 1 root root 0 Jun 6 18:13 /proc/sys/fs/binfmt_misc/status 2 0 drwxr-xr-x 3 root root 0 Jun 6 18:13 /sys/fs
結果から、ルート Inode 番号 2 に加えて、inode 番号 2 を持つファイルがいくつかあることがわかります。それらはすべて独立したファイル システムに属しており、一部は /proc や /sys などの仮想ファイル システムです。 。
4.5.3 ext2/3 i ノードの直接および間接アドレス指定
前に述べたように、ブロック ポインタは i ノードに保存されますが、inode レコードに保存できるポインタの数は制限されており、そうでない場合は制限を超えます。 inode サイズ (128 バイトまたは 256 バイト)。
ext2 および ext3 ファイル システムでは、inode 内に存在できるポインターは最大 15 個のみであり、各ポインターは i_block[n] で表されます。
最初の 12 個のポインター i_block[0] から i_block[11] は直接アドレス指定ポインターであり、各ポインターはデータ領域内のブロックを指します。以下に示すように。
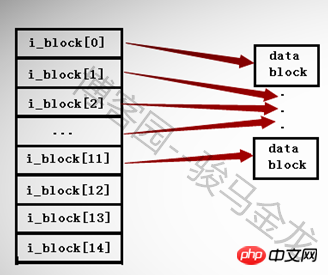
13 番目のポインター i_block[12] は、第 1 レベルの間接アドレス指定ポインターであり、まだポインターを格納しているブロック、つまり i_block[13] --> Pointerblock --> datablock を指します。
14 番目のポインター i_block[13] は、2 次間接アドレス指定ポインターであり、ポインターをまだ格納しているブロックを指しますが、このブロック内のポインターは、ポインターを格納している他のブロック、つまり i_block[13] を指し続けます。 - > ポインターブロック 1 --> ポインターブロック 2 -->
15 番目のポインター i_block[14] は、第 3 レベルの間接アドレス指定ポインターであり、このポインター ブロックの下にポインターがまだ格納されているブロックを指します。つまり、i_block[13] --> Pointerblock1 --> PointerBlock3 --> データブロックです。
各ポインタのサイズは4バイトなので、各ポインタブロックに格納できるポインタの数はBlockSize/4byteになります。たとえば、ブロックサイズが 4KB の場合、ブロックには 4096/4=1024 個のポインターを格納できます。
以下に示すように。
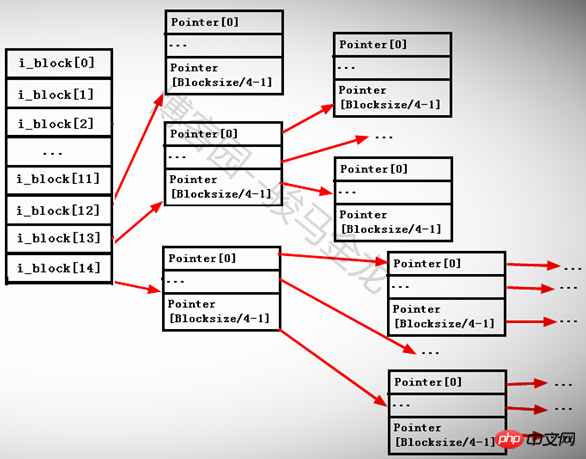
なぜ間接ポインタと直接ポインタが分かれているのでしょうか? i ノード内の 15 個のポインターがすべてダイレクト ポインターであり、各ブロックのサイズが 1KB である場合、15 個のポインターは 15 個のブロック (サイズは 15KB) のみを指すことができます。各ファイルは i ノード番号に対応するため、これにより制限が制限されます。各ブロックのサイズは、ファイルの最大サイズは 15*1=15KB ですが、これは明らかに不合理です。
15KBを超えるファイルを保存する場合、それが大きすぎない場合、第1レベルの間接ポインタi_block[12]が占有されます。このとき、保存できるポインタの数は1024/4+12=268になります。 , したがって、268KBのファイルを保存できます。
268K より大きくても大きすぎないファイルを保存すると、そのファイルは引き続き 2 次ポインター i_block[13] を占有し、この時点で保存できるポインターの数は [1024/4]^2+1024 になります。 /4+12=65804 なので、約 65804KB=64M のファイルを保存できます。
保存されたファイルが 64M より大きい場合は、引き続き第 3 レベルの間接ポインター i_block[14] を使用し、保存されるポインターの数は [1024/4]^3+[1024/4]^2+[ 1024/4]+12 =16843020 ポインターなので、約 16843020KB=16GB のファイルを保存できます。
ブロックサイズ = 4KB の場合はどうなりますか?すると、保存できる最大ファイルサイズは、([4096/4]^3+[4096/4]^2+[4096/4]+12)*4/1024/1024/1024=約4Tとなります。
もちろん、この方法で計算されるのは、必ずしも保存できる最大ファイルサイズではありません。また、別の条件にも影響されます。ここでの計算は、大きなファイルがどのようにアドレス指定され、割り当てられるかを示すだけです。
実際、ここで計算された値を見ると、特にブロックサイズが 4KB の場合、非常に大きなファイルに対する ext2 と ext3 のアクセス効率が低すぎることがわかります。 Ext4 はこの点に合わせて最適化されており、エクステント管理を使用して ext2 と ext3 のブロック マッピングを置き換えるため、効率が大幅に向上し、断片化が減少します。
4.6 単一ファイルシステムにおけるファイル操作の原則
Linux 上で削除、コピー、名前変更、移動などの操作を行う場合、どのように行われるのでしょうか?ファイルにアクセスするときに、どうやってそのファイルを見つけるのでしょうか?実は、前回の記事で紹介したいくつかの用語とその機能を理解していれば、ファイル操作の原理を理解するのは簡単です。
注: このセクションで説明するのは、単一のファイル システムでの動作です。複数のファイル システムの使用方法については、次のセクション「マルチ ファイル システムの関連付け」を参照してください。
4.6.1 ファイルの読み取り
「cat /var/log/messages」コマンドを実行すると、システム内でどのような手順が実行されますか?このコマンドを正常に実行するには、cat コマンドの検索、権限の判断、メッセージ ファイルの権限の検索と判断など、複雑な処理が必要です。ここでは、このセクションの内容に関連する /var/log/messages ファイルを見つける方法のみを説明します。
ルート ファイル システムのブロック グループ記述子テーブルが配置されているブロックを見つけ、GDT (メモリ内に既にある) を読んで i ノード テーブルのブロック番号を見つけます。
GDT は常にスーパーブロックと同じブロック グループにあり、スーパーブロックは常にパーティションの 1024 ~ 2047 バイトにあるため、最初の GDT が配置されているブロック グループとその中のブロックを知るのは簡単です。どの GDT が配置されているか、どのブロックがグループ内で占有されているか。
実際、GDT はすでにメモリ内にあり、システムの起動時にすべての GDT がメモリ内にマウントされます。
inode テーブルのブロック内でルート "/" の i ノードを見つけ、"/" が指すデータ ブロックを見つけます。
前に述べたように、ext ファイルシステムはいくつかの i ノード番号を予約しており、そのうち "/" の i ノード番号は 2 であるため、ルート ディレクトリ ファイルのデータ ブロックは i ノード番号に基づいて直接見つけることができます。
「/」のデータブロックにvarディレクトリ名とvarディレクトリファイルのinodeへのポインタが記録されており、inodeレコードにはvarへのブロックポインタが格納されているので、varディレクトリファイルが見つかります。データブロックも見つかりました。
var ディレクトリの i ノード レコードは、var ディレクトリの i ノード ポインタを介して見つけることができます。ただし、ポインタの位置決めプロセス中に、inode レコードが配置されているブロック グループと i ノード テーブルも知る必要があります。 , したがって、GDT を読み取る必要があります。同様に、GDT はメモリにキャッシュされています。
ログディレクトリ名とそのinodeポインタはvarのデータブロックに記録されており、inodeが配置されているブロックグループとinodeテーブルはこのポインタを介して特定され、ログのデータブロックはそれに基づいて検索されます。 inode レコード。
メッセージファイル名と対応するinodeポインタは、ログディレクトリファイルのデータブロックに記録され、このポインタを通じて、inodeが配置されているブロックグループとinodeテーブル、およびデータが記録されます。メッセージは inode ブロックに基づいて検出されます。
最後にメッセージに対応するデータブロックを読み取ります。
上記の手順の GDT 部分を簡略化すると理解しやすくなります。次のようになります。 GDT を検索します--> "/" の i ノードを検索します--> / のデータ ブロックを検索し、var の i ノードを読み取ります--> var のデータ ブロックを検索します-- > ログ ブロックのデータを見つけてメッセージの i ノードを読み取ります --> メッセージのデータ ブロックを見つけて読み取ります。
4.6.2 ファイルの削除、名前変更、移動
これはファイル システムを横断しない操作であることに注意してください。
削除されたファイルは、通常のファイルとディレクトリ ファイルに分けられます。これら 2 種類のファイルの削除原理を理解していれば、他の種類の特殊ファイルを削除する方法もわかります。
通常のファイルを削除する場合: ファイルの i ノードとデータ ブロックを見つけます (前のセクションの方法に従って見つけます)。ファイルの i ノード番号を imap で未使用としてマークします。 bmap のデータ ブロック 番号は未使用としてマークされます。レコードが配置されているディレクトリのデータ ブロック内のファイル名が存在するレコード行を削除します。レコードが削除されると、I ノードへのポインタが失われます。
ディレクトリ ファイルを削除する場合: ディレクトリとディレクトリ内のすべてのファイル、サブディレクトリ、およびサブファイルの i ノードとデータ ブロックを検索し、これらの i ノード番号を imap で未使用としてマークし、bmap でこれらのファイルが占有しているブロック番号を未使用としてマークします。ディレクトリの親ディレクトリのデータ ブロック内でディレクトリ名が含まれるレコード行を削除します。親ディレクトリ データ ブロック内のレコードの削除は最後のステップであることに注意してください。このステップを事前に実行すると、ディレクトリ内にまだファイルが占有されているため、ディレクトリが空ではないというエラーが報告されます。
ファイルの名前変更は、同じディレクトリ内での名前変更と、異なるディレクトリ内での名前変更に分かれます。別のディレクトリでの名前変更は、実際にはファイルを移動するプロセスです。以下を参照してください。
同じディレクトリ内のファイルの名前を変更する操作は、それが配置されているディレクトリのデータブロックに記録されているファイル名を変更するだけであり、削除して再構築するプロセスではありません。
名前変更中にファイル名が競合した場合(ファイル名がディレクトリにすでに存在している場合)、上書きするかどうかを尋ねるメッセージが表示されます。上書きプロセスでは、ディレクトリ データ ブロック内の競合するファイルのレコードが上書きされます。たとえば、/tmp/ には a.txt と a.log があります。a.txt の名前を a.log に変更すると、データ内の a.log に関するレコードを上書きするように求められます。 /tmp のブロックは上書きされます。この時点で、そのポインターは a.txt の i ノードを指しています。
ファイルの移動
同じファイルシステムの下でファイルを移動することは、実際には、ターゲットファイルが配置されているディレクトリのデータブロックを変更し、そのファイルのinodeポインタを指す行をそれに追加することです。 i ノード テーブルに移動するファイルが同じ名前を持つ場合、それを上書きするかどうかを尋ねるメッセージが表示されます。実際には、ディレクトリ データ ブロック内の競合するファイルのレコードが上書きされます。同じ名前のファイルの i ノード レコード ポインタが上書きされ、ファイルのデータ ブロックが見つからなくなります。これは、ファイルが削除としてマークされていることを意味します (複数のハード リンクがある場合は、別の問題になります)。
そのため、同じファイル システム内でのファイルの移動は、そのファイルが存在するディレクトリのデータ ブロックにレコードを追加または上書きするだけで非常に高速になります。したがって、ファイルを移動しても、ファイルの i ノード番号は変わりません。
異なるファイルシステム内で移動する場合、最初にコピーしてから削除することと同じです。以下を参照してください。
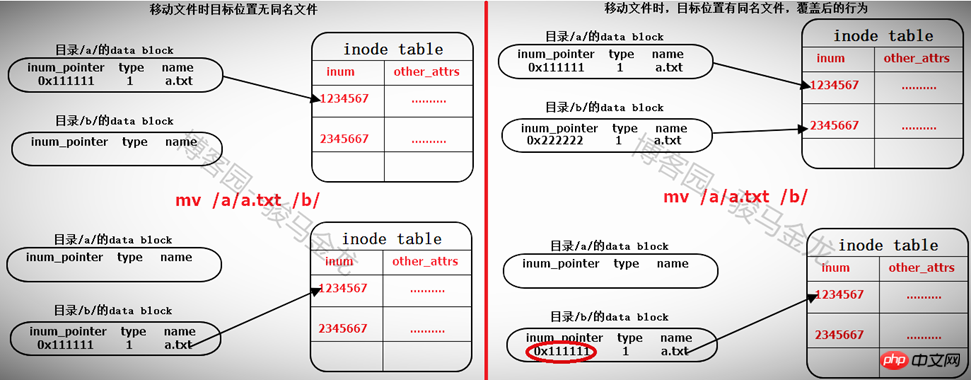
4.6.1 存储和复制文件
对于文件存储
(1).读取GDT,找到各个(或部分)块组imap中未使用的inode号,并为待存储文件分配inode号;
(2).在inode table中完善该inode号所在行的记录;
(3).在目录的data block中添加一条该文件的相关记录;
(4).将数据填充到data block中。
注意,填充到data block中的时候会调用block分配器:一次分配4KB大小的block数量,当填充完4KB的data block后会继续调用block分配器分配4KB的block,然后循环直到填充完所有数据。也就是说,如果存储一个100M的文件需要调用block分配器100*1024/4=25600次。
另一方面,在block分配器分配block时,block分配器并不知道真正有多少block要分配,只是每次需要分配时就分配,在每存储一个data block前,就去bmap中标记一次该block已使用,它无法实现一次标记多个bmap位。这一点在ext4中进行了优化。
(5)填充完之后,去inode table中更新该文件inode记录中指向data block的寻址指针。
对于复制,完全就是另一种方式的存储文件。步骤和存储文件的步骤一样。
4.7 多文件系统关联
在单个文件系统中的文件操作和多文件系统中的操作有所不同。本文将对此做出非常详细的说明。
4.7.1 根文件系统的特殊性
这里要明确的是,任何一个文件系统要在Linux上能正常使用,必须挂载在某个已经挂载好的文件系统中的某个目录下,例如/dev/cdrom挂载在/mnt上,/mnt目录本身是在"/"文件系统下的。而且任意文件系统的一级挂载点必须是在根文件系统的某个目录下,因为只有"/"是自引用的。这里要说明挂载点的级别和自引用的概念。
假如/dev/sdb1挂载在/mydata上,/dev/cdrom挂载在/mydata/cdrom上,那么/mydata就是一级挂载点,此时/mydata已经是文件系统/dev/sdb1的入口了,而/dev/cdrom所挂载的目录/mydata/cdrom是文件系统/dev/sdb1中的某个目录,那么/mydata/cdrom就是二级挂载点。一级挂载点必须在根文件系统下,所以可简述为:文件系统2挂载在文件系统1中的某个目录下,而文件系统1又挂载在根文件系统中的某个目录下。
再解释自引用。首先要说的是,自引用的只能是文件系统,而文件系统表现形式是一个目录,所以自引用是指该目录的data block中,"."和".."的记录中的inode指针都指向inode table中同一个inode记录,所以它们inode号是相同的,即互为硬链接。而根文件系统是唯一可以自引用的文件系统。
[root@xuexi /]# ll -ai /total 102 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 . 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 ..
由此也能解释cd /.和cd /..的结果都还是在根下,这是自引用最直接的表现形式。
[root@xuexi tmp]# cd /. [root@xuexi /]# [root@xuexi tmp]# cd /.. [root@xuexi /]#
但是有一个疑问,根目录下的"."和".."都是"/"目录的硬链接,所以除去根目录下目录数后的硬链接数位3,但实际却为2,不知道这是为何?
[root@server2 tmp]# a=$(ls -al / | grep "^d" |wc -l) [root@server2 tmp]# b=$(ls -l / | grep "^d" |wc -l) [root@server2 tmp]# echo $((a - b))2
4.7.2 挂载文件系统的细节
挂载文件系统到某个目录下,例如"mount /dev/cdrom /mnt",挂载成功后/mnt目录中的文件全都暂时不可见了,且挂载后权限和所有者(如果指定允许普通用户挂载)等的都改变了,知道为什么吗?
下面就以通过"mount /dev/cdrom /mnt"为例,详细说明挂载过程中涉及的细节。
在将文件系统/dev/cdrom(此处暂且认为它是文件系统)挂载到挂载点/mnt之前,挂载点/mnt是根文件系统中的一个目录,"/"的data block中记录了/mnt的一些信息,其中包括inode指针inode_n,而在inode table中,/mnt对应的inode记录中又存储了block指针block_n,此时这两个指针还是普通的指针。
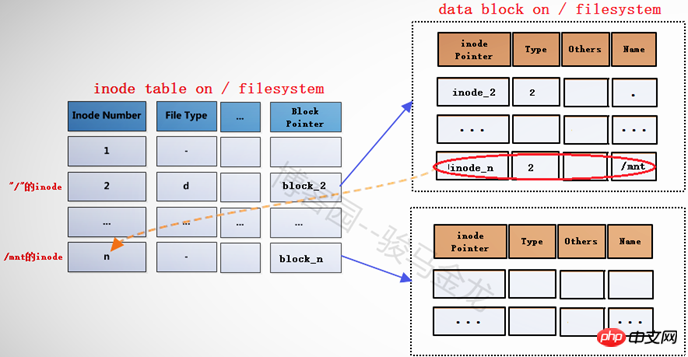
当文件系统/dev/cdrom挂载到/mnt上后,/mnt此时就已经成为另一个文件系统的入口了,因此它需要连接两边文件系统的inode和data block。但是如何连接呢?如下图。
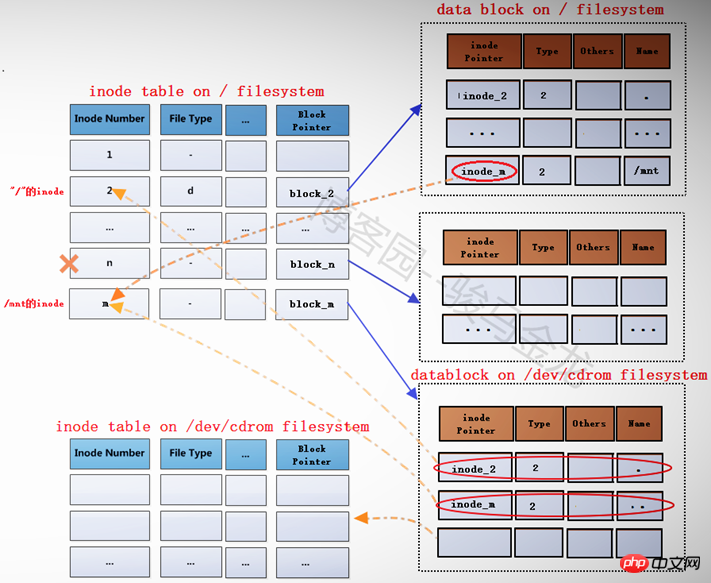
在根文件系统的inode table中,为/mnt重新分配一个inode记录m,该记录的block指针block_m指向文件系统/dev/cdrom中的data block。既然为/mnt分配了新的inode记录m,那么在"/"目录的data block中,也需要修改其inode指针为inode_m以指向m记录。同时,原来inode table中的inode记录n就被标记为暂时不可用。
block_m指向的是文件系统/dev/cdrom的data block,所以严格说起来,除了/mnt的元数据信息即inode记录m还在根文件系统上,/mnt的data block已经是在/dev/cdrom中的了。这就是挂载新文件系统后实现的跨文件系统,它将挂载点的元数据信息和数据信息分别存储在不同的文件系统上。
挂载完成后,将在/proc/self/{mounts,mountstats,mountinfo}这三个文件中写入挂载记录和相关的挂载信息,并会将/proc/self/mounts中的信息同步到/etc/mtab文件中,当然,如果挂载时加了-n参数,将不会同步到/etc/mtab。
而卸载文件系统,其实质是移除临时新建的inode记录(当然,在移除前会检查是否正在使用)及其指针,并将指针指回原来的inode记录,这样inode记录中的block指针也就同时生效而找回对应的data block了。由于卸载只是移除inode记录,所以使用挂载点和文件系统都可以实现卸载,因为它们是联系在一起的。
下面是分析或结论。
(1).挂载点挂载时的inode记录是新分配的。
# 挂载前挂载点/mnt的inode号
[root@server2 tmp]# ll -id /mnt100663447 drwxr-xr-x. 2 root root 6 Aug 12 2015 /mnt [root@server2 tmp]# mount /dev/cdrom /mnt
# 挂载后挂载点的inode号 [root@server2 tmp]# ll -id /mnt 1856 dr-xr-xr-x 8 root root 2048 Dec 10 2015 mnt
由此可以验证,inode号确实是重新分配的。
(2).挂载后,挂载点的内容将暂时不可见、不可用,卸载后文件又再次可见、可用。
# 在挂载前,向挂载点中创建几个文件 [root@server2 tmp]# touch /mnt/a.txt [root@server2 tmp]# mkdir /mnt/abcdir
# 挂载 [root@server2 tmp]# mount /dev/cdrom /mnt # 挂载后,挂载点中将找不到刚创建的文件 [root@server2 tmp]# ll /mnt total 636-r--r--r-- 1 root root 14 Dec 10 2015 CentOS_BuildTag dr-xr-xr-x 3 root root 2048 Dec 10 2015 EFI-r--r--r-- 1 root root 215 Dec 10 2015 EULA-r--r--r-- 1 root root 18009 Dec 10 2015 GPL dr-xr-xr-x 3 root root 2048 Dec 10 2015 images dr-xr-xr-x 2 root root 2048 Dec 10 2015 isolinux dr-xr-xr-x 2 root root 2048 Dec 10 2015 LiveOS dr-xr-xr-x 2 root root 612352 Dec 10 2015 Packages dr-xr-xr-x 2 root root 4096 Dec 10 2015 repodata-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7-r--r--r-- 1 root root 2883 Dec 10 2015 TRANS.TBL # 卸载后,挂载点/mnt中的文件将再次可见 [root@server2 tmp]# umount /mnt [root@server2 tmp]# ll /mnt total 0drwxr-xr-x 2 root root 6 Jun 9 08:18 abcdir-rw-r--r-- 1 root root 0 Jun 9 08:18 a.txt
これが発生する理由は、ファイル システムのマウント後、マウント ポイントの元の i ノード レコードが一時的に使用不可としてマークされるためです。重要なのは、その i ノード レコードを指す i ノード ポインターが存在しないことです。ファイル システムがアンインストールされると、マウント ポイントの元の i ノード レコードが再び有効になり、「/」ディレクトリ内の mnt の i ノード ポインタが再び i ノード レコードを指すようになります。
(3). マウント後、マウント ポイントのメタデータとデータ ブロックは別のファイル システムに保存されます。
(4). マウント ポイントはマウントされた後でも、ソース ファイル システムのファイルに属します。
4.7.3 マルチファイルシステム操作の関連付け
下の図の円がハードディスクを表し、3つの領域、つまり3つのファイルシステムに分割されているとします。このうち、root はルート ファイル システム、/mnt は別のファイル システム A のエントリ、ファイル システム A は /mnt にマウントされ、/mnt/cdrom はファイル システム B のエントリでもあり、ファイル システム B は/mnt/cdrom より優れています。各ファイル システムはいくつかの i ノード テーブルを保持しています。図の i ノード テーブルは、各ファイル システムのすべてのブロック グループ内の i ノード テーブルの集合テーブルであると想定されています。

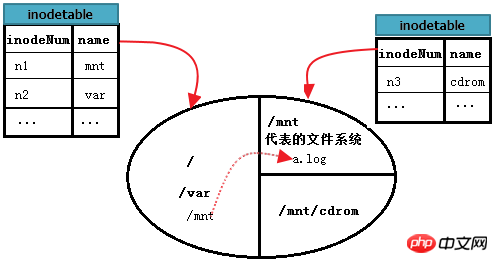
/var/log/messages を読むには?これは、以前の単一ファイルシステムで詳しく説明した、「/」と同じファイルシステムでのファイルの読み取りです。
しかし、A ファイル システムの /mnt/a.log を読み取るにはどうすればよいでしょうか?まず、ルート ファイル システムから /mnt の i ノード レコードを見つけます。これは単一のファイル システム内での検索です。次に、この i ノード レコードのブロック ポインターに基づいて /mnt のデータ ブロックを見つけます。ファイル システム A; 次に、/mnt のデータ ブロックから a.log レコードを読み取り、最後に、a.log の i ノード ポインタに従って、A ファイル システムの i ノード テーブル内で a.log に対応する i ノード レコードを見つけます。この i ノード ログ データ ブロックのブロック ポインターから を見つけます。この時点で、/mnt/a.log ファイルの内容を読み取ることができます。
下の図は、上記のプロセスをより完全に説明できます。
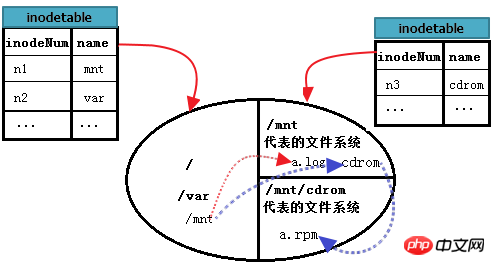
では、/mnt/cdrom の /mnt/cdrom/a.rpm を読み取るにはどうすればよいでしょうか?ここで cdrom で表されるファイル システム B のマウント ポイントは /mnt の下にあるため、もう 1 つの手順があります。まず「/」を見つけ、次にルートで mnt を見つけ、mnt ファイル システムに入り、cdrom のデータ ブロックを見つけ、次に cdrom と入力して a.rpm を見つけます。つまり、mnt ディレクトリ ファイルが保存されている場所はルート、cdrom ディレクトリ ファイルが保存されている場所は mnt、最後に a.rpm が保存されている場所は cdrom です。
上の写真を改善し続けます。次のように。
4.8 ext3 ファイルシステムのログ機能
ext2 ファイルシステムと比較して、ext3 には追加のログ機能があります。
ext2 ファイルシステムには、データ領域とメタデータ領域の 2 つの領域しかありません。データブロックへのデータの書き込み中に突然停電が発生した場合、次回起動時にファイルシステム内のデータと状態の整合性がチェックされ、修復に時間がかかる場合があります。点検後でも修理は出来ません。これが起こる理由は、ファイルシステムが突然電源を失った後、保存されている最後のファイルのブロックがどこで始まりどこで終わるのか分からないため、ファイルシステム全体をスキャンしてそれを除外するためです(おそらくこの方法でチェックされます) )。
ext3 ファイルシステムを作成すると、データ領域、ログ領域、メタデータ領域の 3 つの領域に分割されます。データが保存されるたびに、ext2 のメタデータ領域のアクティビティが最初にログ領域で実行され、ファイルにコミットのマークが付けられて初めて、ログ領域のデータがメタデータ領域に転送されます。ファイルの保存中に突然停電が発生した場合、次回ファイル システムをチェックして修復するときは、ログ領域内のレコードをチェックし、bmap に対応するデータ ブロックを未使用としてマークし、inode 番号をマークするだけで済みます。ファイル全体をスキャンする必要がないため、システムに多くの時間がかかります。
ext3 にはメタデータ領域を変換するためのログ領域が ext2 よりも 1 つ多くありますが、ext3 のパフォーマンスは、特に小さなファイルを多数書き込む場合に ext2 よりわずかに劣ります。ただし、ext3 のその他の最適化により、ext3 と ext2 の間にパフォーマンスの差はほとんどありません。
4.9 ext4 ファイル システム
ext2 および ext3 ファイル システムの以前のストレージ形式を思い出してください。ブロックを分割する方法ではありますが、各ブロックは bmap 内のビットを使用して空きかどうかをマークします。最適化により効率が向上しますが、ブロック グループ内のブロックをマークするために bmap が引き続き使用されます。巨大なファイルの場合、bmap 全体をスキャンすると大規模なプロジェクトになります。さらに、inode アドレス指定に関して、ext2/3 は 3 レベルの間接ポインタの場合、直接および間接アドレス指定方法を使用するため、通過できるポインタの数は非常に膨大になります。
ext4 ファイルシステムの最大の特徴は、ext3 をベースとしたエクステント(エクステント、またはセグメント)の概念を用いて管理されていることです。エクステントには、物理的に連続したブロックができるだけ多く含まれます。 i ノードのアドレス指定もセクション ツリーを使用して改善されました。
デフォルトでは、EXT4 は EXT3 のブロック マッピング割り当て方法を使用せず、代わりにエクステント割り当て方法を使用します。
(1). EXT4 の構造的特徴について
EXT4 は、その全体的な構造において EXT3 と似ており、同じサイズのブロック グループに基づいて、それぞれに固定数の inode と可能なスーパーブロックが割り当てられます。ブロック グループ (またはバックアップ) と GDT。
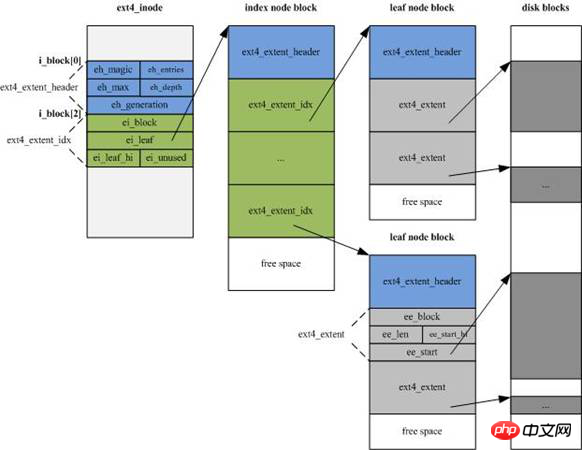
新しい情報を追加するために、EXT4 の i ノード構造が大幅に変更され、サイズが EXT3 の 128 バイトからデフォルトの 256 バイトに増加しました。同時に、inode アドレス指定インデックスは EXT3 の「12 ダイレクト」を使用しなくなりました。 「1 レベル 1 間接アドレッシング ブロック + 1 レベル 2 間接アドレッシング ブロック + 1 レベル 3 間接アドレッシング ブロック」のインデックス モードが 4 エクステント フラグメント ストリームに変更され、各フラグメント ストリームがフラグメントの開始を設定します。番号と連続するブロックの数 (データ領域を直接指す場合もあれば、インデックス ブロック領域を指す場合もあります)。
フラグメントストリームは、下図のインデックスノードブロック(indeノードブロック)内の緑色の部分で、それぞれ15バイト、合計60バイトです。
(2)。EXT4 はデータの構造変更を削除します。
データを削除した後、EXT4 はファイルシステムのビットマップ空間ビットを解放し、ディレクトリ構造を更新し、inode 空間ビットを順番に解放します。
(3). ext4 はマルチブロック割り当てを使用します。
データを保存するとき、ext3 のブロック アロケーターは一度に 4KB ブロックのみを割り当てることができ、bmap は各ブロックが保存される前に 1 回マークされます。 1G ファイルが保存され、ブロックサイズが 4KB の場合、各ブロックが保存された後にブロック アロケーターが 1 回呼び出されます。つまり、呼び出し回数は 1024*1024/4KB=262144 回で、bmap の回数はマークも 1024*1024/4= 262,144 回です。
ext4 では、割り当てはセクションに基づいて行われます。ブロック アロケーターを 1 回呼び出すことで、一連の連続したブロックを割り当て、このブロックの束を保存する前に、対応する bmap を一度にマークすることができます。これにより、大きなファイルのストレージ効率が大幅に向上します。
4.10 ext ファイルシステムの欠点
最大の欠点は、ファイルシステムを作成するときに分割する必要があるものをすべて分割し、将来使用するときに直接割り当てることができることです。動的パーティショニングと動的割り当てはサポートしません。小さなパーティションの場合、速度は問題ありませんが、非常に大きなディスクの場合、速度は非常に遅くなります。たとえば、数十テラバイトのディスク アレイを ext4 ファイル システムにフォーマットすると、忍耐力がすべて失われる可能性があります。
フォーマット速度が非常に遅いことに加えて、ext4 ファイル システムが依然として非常に好ましいです。もちろん、さまざまな企業が開発したファイル システムにはそれぞれ独自の特徴があります。最も重要なことは、ニーズに応じて適切なファイル システムの種類を選択することです。
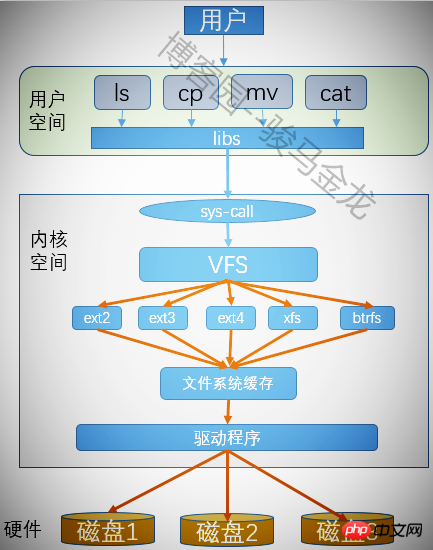
4.11 仮想ファイルシステム VFS
Linux はフォーマット後にファイルシステムを作成できますが、どのように認識されるのでしょうか?さらに、パーティション内のファイルを操作するときに、それがどのファイルシステムに属するかを指定していないため、ユーザーはどのようにしてさまざまなファイルシステムを無差別に操作できるのでしょうか。これが仮想ファイル システムの機能です。
仮想ファイル システムは、ユーザーがさまざまなファイル システムを操作するための共通のインターフェイスを提供するため、プログラムを実行するときに、ユーザーはファイルがどの種類のファイル システムにあるか、ファイルを操作するためにどのようなシステム コールを使用する必要があるかを考慮する必要がありません。 . 文書。仮想ファイル システムを使用すると、実行する必要があるすべてのプログラムに対して VFS のシステム コールを呼び出すだけで済み、VFS が残りのアクションの完了を支援します。
転載の際は出典を明記してください:
以上が外部ファイルシステムのメカニズムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。