
ホームページ >バックエンド開発 >Python チュートリアル >クローラー&問題解決&思考
クローラー&問題解決&思考
- 巴扎黑オリジナル
- 2017-06-23 14:47:361611ブラウズ
最近 Python に触れたばかりで、スキルを練習するための小さなタスクを探しています。実践で問題解決能力を発揮し続けられることを願っています。この小さなクローラーは、MOOC のコースから取得したもので、私が学習プロセス中に遭遇した問題と解決策、およびクローラーの外での私の考えを記録しています。
この小さなタスクは、小さなクローラーを書くことです。私がこれを練習に選んだ最も重要な理由は、武漢の現在の天気と同じように、ビッグデータが暑すぎるということです。データは「ビッグデータ」にとって、兵士にとっては武器に相当し、レンガやタイルは高層ビルに相当します。データがなければ、「ビッグデータ」は単なる空のロフトに過ぎず、地上に置いて実際に適用することはできません。データはどこから来たのでしょうか?方法は2つあり、1つは自分から奪う方法、もう1つは他人から奪う方法です。もう一つは言うまでもなく他者から物を奪うことであり、この他者とはインターネットのことを指します。
まず第一に、クローラーについて理解する必要があります: 一定のルールに従って World Wide Web 情報を自動的にクロールするプログラムまたはスクリプト (Baidu Encyclopedia より) 。名前が示すように、ページにアクセスし、ページ上のコンテンツを保存し、保存したページから興味のあるコンテンツをフィルターで除外して、個別に保存する必要があります。実生活では、私たちはこのようなことをよく行います。退屈な午後、ブラウザにアドレスを入力してページにアクセスし、興味のある記事や段落を見つけて選択し、それをコピーして単語に貼り付けます。書類。 。上記の作業を 1 ページに対して実行し、それを数百万ページに対して実行すると、データはますます大きくなります。このプロセスを「データ収集」と呼びます。
クローラーの利点は、自動化とバッチ処理です。ここで誤解があると思いますが、私はクローラーに触れる前は、クローラーは「見えない」ものをクロールできるものだと思っていました。
以下はこのクローラのアーキテクチャとクローリングプロセスです
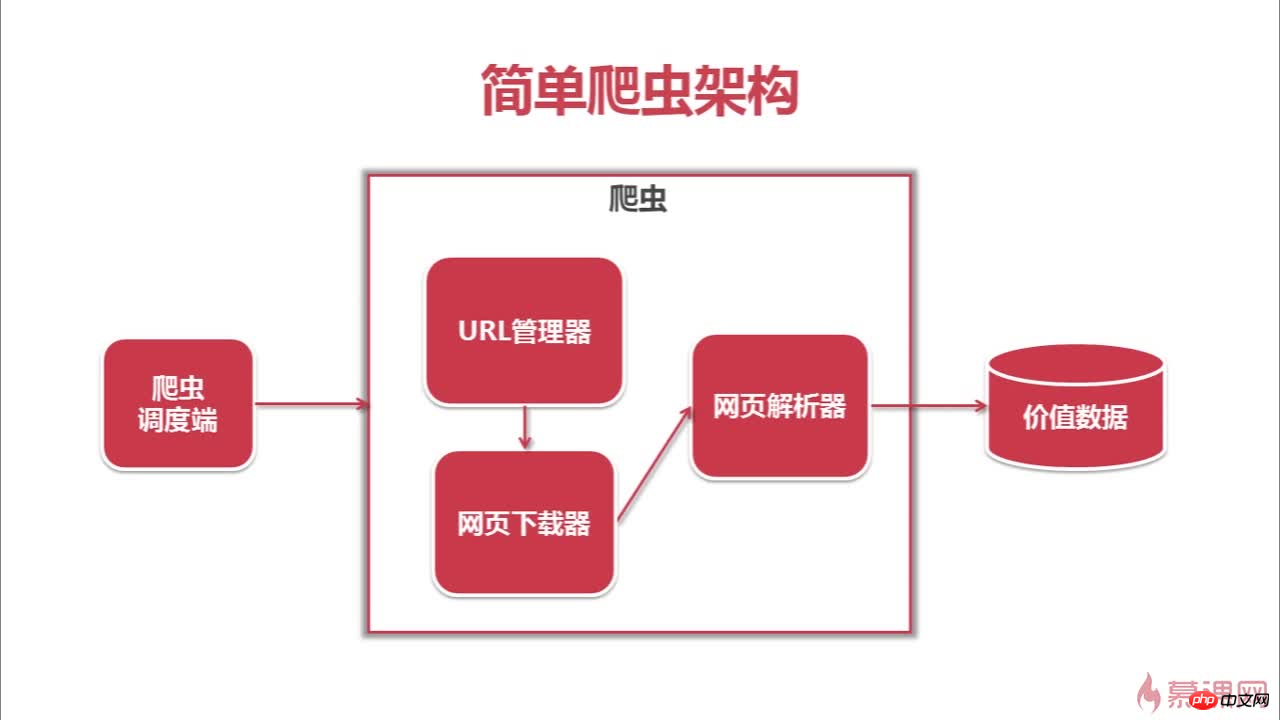
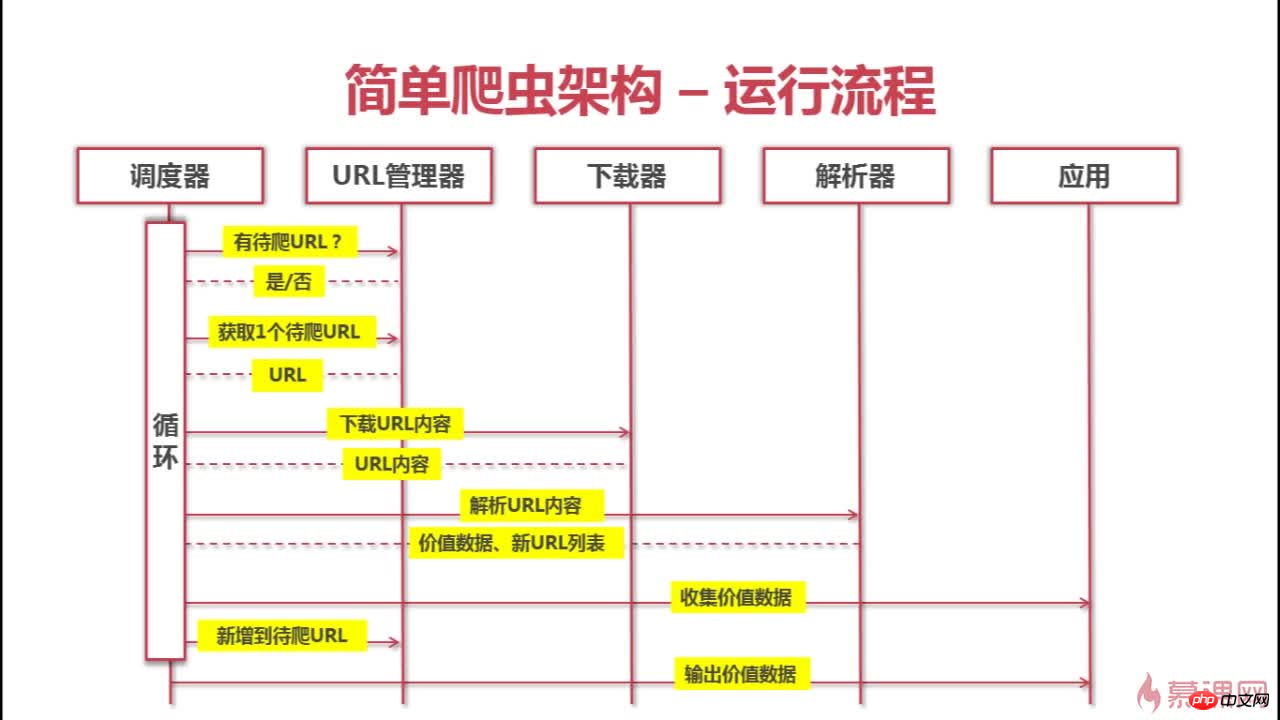
以上がクローラー&問題解決&思考の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。