
ホームページ >データベース >mysql チュートリアル >データベース テーブルの設計 - 隣接リスト、パス列挙、ネストされたセット、クロージャ テーブル
データベース テーブルの設計 - 隣接リスト、パス列挙、ネストされたセット、クロージャ テーブル
- 巴扎黑オリジナル
- 2017-06-23 15:05:364444ブラウズ
データベースを設計するとき、慣例を打ち破り、ニーズに最も適した設計ソリューションを見つけることができますか? 以下に例を示します:
一般的に使用される隣接テーブルの設計では、region テーブルなどのparent_id フィールドが追加されます。 (国テーブル)、州、市、地区):
CREATE TABLE Area ([id] [int] NOT NULL,[name] [nvarchar] (50) NULL,[parent_id] [int] NULL,[type] [int] NULL );
name: 地域の名前、parent_id は親 ID、州の親 ID は国、親 ID市のは州、など。
typeは地域のレベルです: 1: Country、2: Province、3: City、4: District
レベルが比較的確実な場合は、このようにテーブルを設計しても問題ありません。電話をかけるのはとても便利です。
ただし、この隣接リスト設計方法を使用してもすべてのニーズを満たすことはできません。レベルがわからない場合は、次のようなコメント構造があるとします。
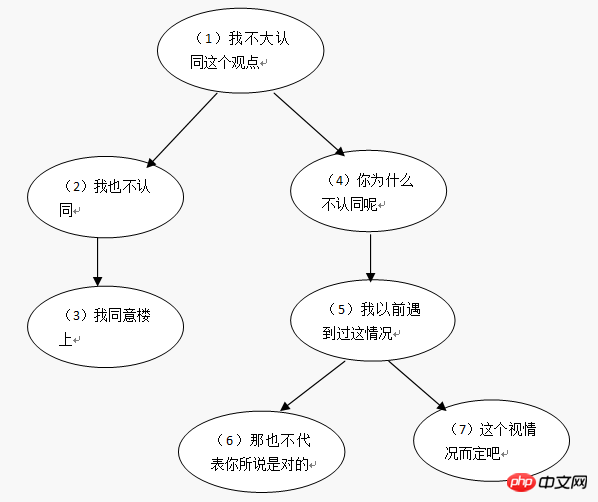
これには隣接リスト レコード データを使用します。コメント (コメントテーブル):
| comment_id | parent_id | author | comment |
| 1 | 0 | シャオミン | 私はあまり同意しません私はこの意見に同意しません |
| 2 | 1 | Xiao Zhang | 私も同意しません |
| 3 | 2 | Xiaohong | 私は上の階の人に同意します |
| 4 | 1 | Xiaoquan | なぜ同意しないのですか |
| 5 | 4 | Xiao Ming | 私は以前にもこの状況に遭遇したことがあります |
| 6 | 5 | シャオ・チャン | それはあなたの言ったことが正しいという意味ではありません |
| 7 | 5 | Xiaoxin | これは状況によります |
このように設計されたテーブルでは、ノードのすべての子孫をクエリしますか? これを実現するには、関連クエリを使用してコメントとその子孫を取得できます:
SELECT c1.*, c2.* FROM comments c1 LEFT OUTER JOIN comments c2 ON c2.parent_id = c1.comment_id;
ただし、このクエリは 2 レベルのデータしか取得できません。この種のツリーの特徴は、任意の深さまで拡張できることであり、その深さデータを取得するには対応するメソッドが必要です。たとえば、コメント分岐の数を数えたり、機械の総コストを計算したりする必要がある場合があります。
場合によっては、プロジェクトで隣接リストを使用することが適切です。隣接リスト設計の利点は、特定のノードの直接の親ノードと子ノードを迅速に取得でき、新しいノードを簡単に挿入できることです。このような要件が、プロジェクトの階層データに対するすべての操作である場合は、隣接リストの使用が適切に機能します。
上記のツリー モデルに遭遇した場合、パスの列挙、ネストされたセット、クロージャ テーブルなど、いくつかのオプションを考慮できます。これらのソリューションは多くの場合、隣接リストよりもはるかに複雑に見えますが、隣接リストを使用すると複雑または非効率になる特定の操作が簡単になります。プロジェクトで本当にこれらの操作を提供する必要がある場合は、隣接リストとしてはこれらの設計を選択することをお勧めします。
1. パスの列挙
コメント テーブルでは、varchar 型の path フィールドを使用して、元のparent_id フィールドを置き換えます。このパス フィールドに格納される内容は、現在のノードの最上位の祖先からそのノード自体のシーケンスまでのシーケンスであり、UNIX パスと同様に、パス区切り文字として「/」を使用することもできます。
| comment_id | パス | 作成者 | コメント |
| 1 | 1 | シャオミン | 私はこの意見にはあまり同意しません |
| 2 | 1/2 | Xiao Zhang | 私も同意しません |
| 3 | 1/2/3 | Xiaohong | 上記に同意します |
| 4 | 1 /4 | 小全 | なぜ同意しないのですか |
| 5 | 1/4/5 | シャオミン | 私は以前にもこの状況に遭遇したことがあります |
| 6 | 1/4/5 /6 | Xiao Zhang | あなたの言っていることが正しいというわけではありません |
| 7 | 1/4/5/7 | Xiaoxin | それは状況次第です |
你可以通过比较每个节点的路径来查询一个节点祖先。比如:要找到评论#7, 路径是 1/4/5/7一 的祖先,可以这么做:
SELECT * FROM comments AS c WHERE '1/4/5/7' LIKE c.path || '%' ;
这句话查询语句会匹配到路径为 1/4/5/%,1/4/% 以及 1/% 的节点,而这些节点就是评论#7的祖先。
同时还可以通过将LIKE 关键字两边的参数互换,来查询一个给定节点的所有后代。比如查询评论#4,路径path为 ‘1/4’ 的所有后代,可以使用如下语句:
SELECT * FROM comemnts AS c WHERE c.path LIKE '1/4' || '%' ;
这句查询语句所有能找到的后台路径分别是:1/4/5、1/4/5/6、1/4/5/7。
一旦你可以很简单地获取一棵子树或者从子孙节点到祖先节点的路径,你就可以很简单地实现更多的查询,如查询一颗子树所有节点上值的总和。
插入一个节点也可以像使用邻接表一样地简单。你所需要做的只是复制一份要插入节点的父亲节点路径,并将这个新节点的ID追加到路径末尾即可。
路径枚举也存在一些缺点,比如数据库不能确保路径的格式总是正确或者路径中的节点确实存在。依赖于应用程序的逻辑代码来维护路径的字符串,并且验证字符串的正确性开销很大。无论将varchar 的长度设定为多大,依旧存在长度的限制,因而并不能够支持树结构无限扩展。
二、 嵌套集
嵌套集解决方案是存储子孙节点的相关信息,而不是节点的直接祖先。我们使用两个数字来编码每个节点,从而表示这一信息,可以将这两个数字称为nsleft 和 nsright。
每个节点通过如下的方式确定nsleft 和nsright 的值:nsleft的数值小于该节点所有后代ID,同时nsright 的值大于该节点的所有后代的ID。这些数字和comment_id 的值并没有任何关联。
确定这三个值(nsleft,comment_id,nsright)的简单方法是对树进行一次深度优先遍历,在逐层深入的过程中依次递增地分配nsleft的值,并在返回时依次递增地分配nsright的值。得到数据如下:

| comment_id | nsleft | nsright | author | comment |
| 1 | 1 | 14 | 小明 | 我不大认同这个观点 |
| 2 | 2 | 5 | 小张 | 我也不认同 |
| 3 | 3 | 4 | 小红 | 我同意楼上 |
| 4 | 6 | 13 | 小全 | 你为什么不认同呢 |
| 5 | 7 | 12 | 小明 | 我以前遇到过这情况 |
| 6 | 8 | 9 | 小张 | 那也不代表你所说是对的 |
| 7 | 10 | 11 | 小新 | 这个视情况而定吧 |
一旦你为每个节点分配了这些数字,就可以使用它们来找到指定节点的祖先和后代。比如搜索评论#4及其所有后代,可以通过搜索哪些节点的ID在评论 #4 的nsleft 和 nsright 范围之间,例:
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c2.nsleft BETWEEN c1.nsleftAND c1.nsright WHERE c1.comment_id = 4;
比如搜索评论#6及其所有祖先,可以通过搜索#6的ID在哪些节点的nsleft 和 nsright 范围之间,例:
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c1.nsleft BETWEEN c2.nsleftAND c2.nsright WHERE c1.comment_id = 6;
使用嵌套集设计的主要优势是,当你想要删除一个非叶子节点时,它的后代会自动替代被删除的节点,成为其直接祖先节点的直接后代。就是说已经自动减少了一层。
然而,某些在邻接表的设计中表现得很简单的查询,比如获取一个节点的直接父亲或者直接后代,在嵌套集设计中会变得比较复杂。在嵌套集中,如果需要查询一个节点的直接父亲,我们会这么做,比如要找到评论#6 的直接父亲:
SELECT parent.* FROM comments AS c JOIN comments AS parent ON c.nsleft BETWEEN parent.nsleft AND parent.nsrightLEFT OUTER JOIN comments AS in_between ON c.nsleft BETWEEN in_between.nsleft AND in_between.nsrightAND in_between.nsleft BETWEEN parent.nsleft AND parent.nsright WHERE c.comment_id = 6AND in_between.comment_id IS NULL;
总之有些复杂。
对树进行操作,比如插入和移动节点,使用嵌套集会比其它设计复杂很多。当插入一个新节点时,你需要重新计算新插入节点的相邻兄弟节点、祖先节点和它祖先节点的兄弟,来确保他们的左右值都比这个新节点的左值大。同时,如果这个新节点时一个非叶子节点,你还要检查它的子孙节点。
如果简单快速查询是整个程序中最重要的部分,嵌套集是最好的选择,比操作单独的节点要方便快捷很多。然而,嵌套集的插入和移动节点是比较复杂的,因为需要重新分配左右值,如果你的应用程序需要频繁的插入、删除节点,那么嵌套集可能并不合适。
三、闭包表
闭包表是解决分级存储的一个简单而优雅的解决方案,它记录了树中所有节点间的关系,而不仅仅只有那些直接的父子节点。
在设计评论系统时,我们额外创建了一个叫 tree_paths 表,它包含两列,每一列都指向 comments 中的外键。
我们不再使用comments 表存储树的结构,而是将树中任何具有(祖先 一 后代)关系的节点对都存储在treepaths 表里,即使这两个节点之间不是直接的父子关系;同时,我们还增加一行指向节点自己。
| 祖先 | 后代 | 祖先 | 后代 | 祖先 | 后代 | 祖先 | 后代 |
| 1 | 1 | 1 | 7 | 4 | 6 | 7 | 7 |
| 1 | 2 | 2 | 2 | 4 | 7 | ||
| 1 | 3 | 2 | 3 | 5 | 5 | ||
| 1 | 4 | 3 | 3 | 5 | 6 | ||
| 1 | 5 | 4 | 4 | 5 | 7 | ||
| 1 | 6 | 4 | 5 | 6 | 6 |
通过treepaths 表来获取祖先和后代比使用嵌套集更加的直接。例如要获取评论#4的后代,只需要在 treepaths 表中搜索祖先是评论 #4的行就行了。同样获取后代也是如此。
要插入一个新的叶子节点,比如评论#6的一个子节点,应首先插入一条自己到自己的关系,然后搜索 treepaths 表中后代是评论#6 的节点,增加该节点和新插入节点的“祖先一后代”关系(新节点ID 应该为8):
INSERT INTO treepaths (ancestor, descendant)SELECT t.ancestor, 8FROM treepaths AS tWHERE t.descendant = 6UNION ALL SELECT 8, 8;
要删除一个叶子节点,比如评论#7, 应删除所有treepaths 表中后代为评论 #7 的行:
DELETE FROM treepaths WHERE descendant = 7;
要删除一颗完整的子树,比如评论#4 和它所有的后代,可删除所有在 treepaths 表中后代为 #4的行,以及那些以评论#4后代为后代的行。
闭包表的设计比嵌套集更加的直接,两者都能快捷地查询给定节点的祖先和后代,但是闭包表能更加简单地维护分层信息。这两个设计都比使用邻接表或者路径枚举更方便地查询给定节点的直接后代和祖先。
然而你可以优化闭包表来使它更方便地查询直接父亲节点或者子节点: 在 treepaths 表中添加一个 path_length 字段。一个节点的自我引用的path_length 为0,到它直接子节点的path_length 为1,再下一层为2,以此类推。这样查询起来就方便多了。
总结:你该使用哪种设计:
种设计都各有优劣,如何选择设计,依赖于应用程序的哪种操作是你最需要性能上的优化。
| 方案 | 表数量 | 查询子 | 查询树 | 插入 | 删除 | 引用完整性 |
| 邻接表 | 1 | 简单 | 困难 | 简单 | 简单 | 是 |
| 枚举路径 | 1 | 简单 | 简单 | 简单 | 简单 | 否 |
| 嵌套集 | 1 | 困难 | 简单 | 困难 | 困难 | 否 |
| 闭包表 | 2 | 简单 | 简单 | 简单 | 简单 | 是 |
层级数据设计比较
1、邻接表是最方便的设计,并且很多程序员都了解它
2、如果你使用的数据库支持WITH 或者 CONNECT BY PRIOR 的递归查询,那能使得邻接表的查询更高效。
3、枚举路径能够很直观地展示出祖先到后代之间的路径,但同时由于它不能确保引用完整性,使得这个设计非常脆弱。枚举路径也使得数据的存储变得比较冗余。
4、嵌套集是一个聪明的解决方案,但可能过于聪明,它不能确保引用完整性。最好在一个查询性能要求很高而对其他要求一般的场合来使用它。
5、闭包表是最通用的设计,并且以上的方案也只有它能允许一个节点属于多棵树。它要求一张额外的表来存储关系,使用空间换时间的方案减少操作过程中由冗余的计算所造成的消耗。
这几种设计方案只是我们日常设计中的一部分,开发中肯定会遇到更多的选择方案。选择哪一种方案,是需要切合实际,根据自己项目的需求,结合方案的优劣,选择最适合的一种。
我遇到一些开发人员,为了敷衍了事,在设计数据库表时,只考虑能否完成眼下的任务,不太注重以后拓展的问题,不考虑查询起来是否耗性能。可能前期数据量不多的时候,看不出什么影响,但数据量稍微多一点的话,就已经显而易见了(例如:可以使用外联接查询的,偏偏要使用子查询)。
我觉得设计数据库是一个很有趣且充满挑战的工作,它有时能体现你的视野有多宽广,有时它能让你睡不着觉,总之痛并快乐着。
以上がデータベース テーブルの設計 - 隣接リスト、パス列挙、ネストされたセット、クロージャ テーブルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。