
ホームページ >バックエンド開発 >Python チュートリアル >Python クローラーのデータはどのように処理されるべきですか?
Python クローラーのデータはどのように処理されるべきですか?

- PHP中文网オリジナル
- 2017-06-20 16:27:572607ブラウズ
1. まずは以下の関数を理解してください
変数 length() 関数 char_length() replace() 関数 max() 関数
1.1. 変数 set @variable name=value
set @address='中国-山东省-聊城市-莘县';select @address
1.2, length() 関数 char_length ( ) 関数の違い
select length('a') ,char_length('a') ,length('中') ,char_length('中')
1.3、replace() 関数と length() 関数の組み合わせ
set @address='中国-山东省-聊城市-莘县';select @address ,replace(@address,'-','') as address_1 ,length(@address) as len_add1 ,length(replace(@address,'-','')) as len_add2 ,length(@address)-length(replace(@address,'-','')) as _count
etl フィールドをクリーニングするときに明らかな区切り記号がある場合に、新しいデータテーブルに追加する分割されたフィールドの数を決定する方法
計算com_industry に最も多い - 追加するフィールドの数を決定するための記号がいくつかあります。最大値 +1 は分割できるフィールドの数です。このテーブルは 3 つであるため、4 つの業界フィールドを分割できます。レベル
select max(length(com_industry)-length(replace(com_industry,'-',''))) as _max_count from etl1_socom_data
1.4. 変数substring_index()を設定する 文字列インターセプト関数の使い方
set @address='中国-山东省-聊城市-莘县'; select substring_index(@address,'-',1) as china, substring_index(substring_index(@address,'-',2),'-',-1) as province, substring_index(substring_index(@address,'-',3),'-',-1) as city, substring_index(@address,'-',-1) as district
1.5. 条件判定関数case when then then else value endをフィールド名
select case when 89>101 then '大于' else '小于' end as betl1_socom_data2. ケトル変換etl1クリーニングファーストテーブル作成手順はビデオにあります
フィールド インデックス インデックス アルゴリズムについては言及されていません
2.インクルード コントロール: table input>>> ; テーブル出力
2.3. データ フローの方向: s_socom_data>>>> ;etl1_socom_data
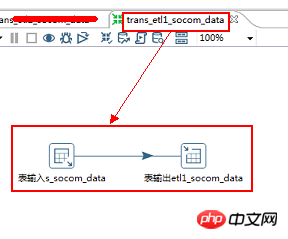
kettle 変換 1 スクリーンショット
rrreええ
2.5 , テーブル出力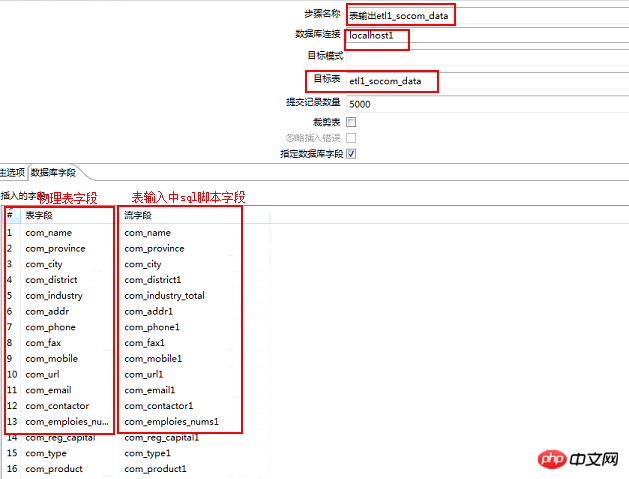
テーブル出力設定の注意点
注意事項:
① クローラーの増分操作が関係する場合は、テーブルのカット オプションをチェックしないでください
② データ接続の問題 テーブル出力のテーブルが存在するデータベースを選択してください見つかった
③ フィールド マッピングの問題 データ ストリーム内のフィールドの数が物理テーブル内のフィールドの数と一致していることを確認します
フィールド インデックスでは、インデックス アルゴリズムについては言及されていません。クエリ効率を高めるには、BTREE アルゴリズムを使用することをお勧めします。
3.1.kettle ファイル名: trans_etl2_socom_data
3.2. インクルードコントロール: テーブル入力>>>テーブル出力
3.3. データフローの方向: etl1_socom_data>>>>etl2_socom_data
注意事項:
① クローラーのインクリメントを含みます。操作中にカットテーブルオプションをチェックしないでください
②データ接続の問題 テーブル出力のテーブルが配置されているデータベースを選択します
③フィールド マッピングの問題 データ フロー内のフィールドの数と物理テーブルが一致していることを確認します
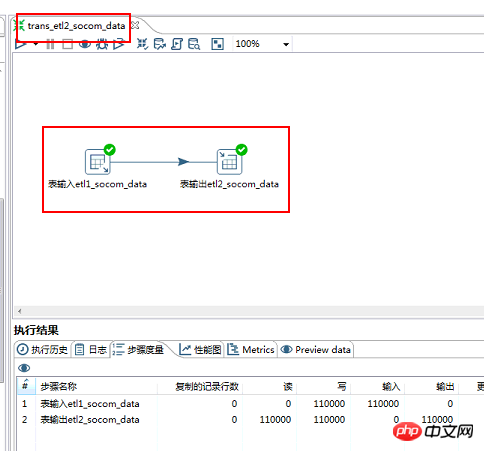
ケトル変換 2 のスクリーンショット
<code class="sql"><span class="hljs-keyword">select a.*,<span class="hljs-keyword">case <span class="hljs-keyword">when com_district <span class="hljs-keyword">like <span class="hljs-string">'%业' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%织' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%育' <span class="hljs-keyword">then <span class="hljs-literal">null <span class="hljs-keyword">else com_district <span class="hljs-keyword">end <span class="hljs-keyword">as com_district1 ,<span class="hljs-keyword">case <span class="hljs-keyword">when com_district <span class="hljs-keyword">like <span class="hljs-string">'%业' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%织' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%育' <span class="hljs-keyword">then <span class="hljs-keyword">concat(com_district,<span class="hljs-string">'-',com_industry) <span class="hljs-keyword">else com_industry <span class="hljs-keyword">end <span class="hljs-keyword">as com_industry_total ,<span class="hljs-keyword">replace(com_addr,<span class="hljs-string">'地 址:',<span class="hljs-string">'') <span class="hljs-keyword">as com_addr1 ,<span class="hljs-keyword">replace(com_phone,<span class="hljs-string">'电 话:',<span class="hljs-string">'') <span class="hljs-keyword">as com_phone1 ,<span class="hljs-keyword">replace(com_fax,<span class="hljs-string">'传 真:',<span class="hljs-string">'') <span class="hljs-keyword">as com_fax1 ,<span class="hljs-keyword">replace(com_mobile,<span class="hljs-string">'手机:',<span class="hljs-string">'') <span class="hljs-keyword">as com_mobile1 ,<span class="hljs-keyword">replace(com_url,<span class="hljs-string">'网址:',<span class="hljs-string">'') <span class="hljs-keyword">as com_url1 ,<span class="hljs-keyword">replace(com_email,<span class="hljs-string">'邮箱:',<span class="hljs-string">'') <span class="hljs-keyword">as com_email1 ,<span class="hljs-keyword">replace(com_contactor,<span class="hljs-string">'联系人:',<span class="hljs-string">'') <span class="hljs-keyword">as com_contactor1 ,<span class="hljs-keyword">replace(com_emploies_nums,<span class="hljs-string">'公司人数:',<span class="hljs-string">'') <span class="hljs-keyword">as com_emploies_nums1 ,<span class="hljs-keyword">replace(com_reg_capital,<span class="hljs-string">'注册资金:万',<span class="hljs-string">'') <span class="hljs-keyword">as com_reg_capital1 ,<span class="hljs-keyword">replace(com_type,<span class="hljs-string">'经济类型:',<span class="hljs-string">'') <span class="hljs-keyword">as com_type1 ,<span class="hljs-keyword">replace(com_product,<span class="hljs-string">'公司产品:',<span class="hljs-string">'') <span class="hljs-keyword">as com_product1 ,<span class="hljs-keyword">replace(com_desc,<span class="hljs-string">'公司简介:',<span class="hljs-string">'') <span class="hljs-keyword">as com_desc1<span class="hljs-keyword">from s_socom_data <span class="hljs-keyword">as a</span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></code><br/><br/><br/>コードの詳細な分解と調整を行わずに、登録資本フィールドの時間関係を調整できます4.1 クローラーのデータソースデータがWebサイトのデータと一致するかどうか
自分の作業がクローラとデータ処理を一緒に処理するもので、クローリング時にすでに判断が行われている場合、上流のクローラの同僚に接続する場合は、この手順を最初に判断する必要があります。そうでない場合は、クリーニングが行われます。一般に、クローラーの同僚はリクエストを保存する必要があります。URL は、その後のデータ処理でデータの品質を確認するのに便利です4.2 クローラーのデータ ソースと各 ETL クリーニング データ テーブルのデータ量を計算します注: SQL スクリプトで集計およびフィルタリングされていない 3 つのテーブルのデータ量は等しいはずです4.2.1、SQL クエリ以下のテーブルが同じデータベース内にある場合、同じデータベース内にない場合は、テーブルが存在するデータベースは from の後に追加する必要があります。データ量が大きい場合は使用しないでください。 4.2.2 ケトル変換完了後のテーブルの合計出力の比較。 kettle テーブルによって出力されるデータの総量
select a.*,case #行业为''的值 置为空when length(com_industry)=0 then null #其他的取第一个-分隔符之前else substring_index(com_industry,'-',1) end as com_industry1,case when length(com_industry)-length(replace(com_industry,'-',''))=0 then null #'交通运输、仓储和邮政业-' 这种值 行业2 也置为nullwhen length(com_industry)-length(replace(com_industry,'-',''))=1 and length(substring_index(com_industry,'-',-1))=0 then nullwhen length(com_industry)-length(replace(com_industry,'-',''))=1 then substring_index(com_industry,'-',-1)else substring_index(substring_index(com_industry,'-',2),'-',-1)end as com_industry2,case when length(com_industry)-length(replace(com_industry,'-',''))<=1 then nullwhen length(com_industry)-length(replace(com_industry,'-',''))=2 then substring_index(com_industry,'-',-1)else substring_index(substring_index(com_industry,'-',3),'-',-1)end as com_industry3,case when length(com_industry)-length(replace(com_industry,'-',''))<=2 then nullelse substring_index(com_industry,'-',-1)end as com_industry4from etl1_socom_data as a
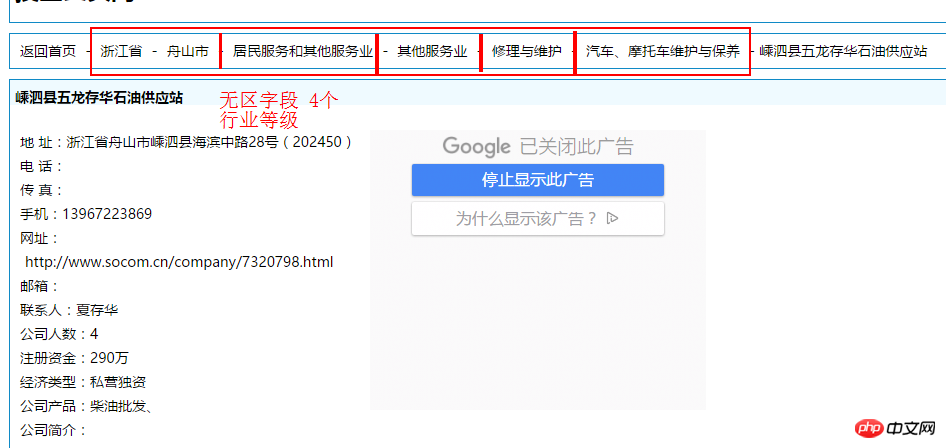
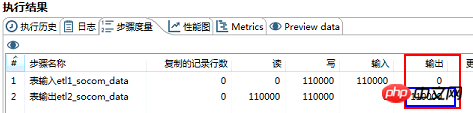 このページのデータ etl2_socom_data テーブルの最終的なクリーニング データとの比較
このページのデータ etl2_socom_data テーブルの最終的なクリーニング データとの比較Web サイトのページ データ
学習プロセス中に問題が発生した場合、または学習リソースを入手したい場合は、学習交換グループ
以上がPython クローラーのデータはどのように処理されるべきですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。