
ホームページ >バックエンド開発 >Python チュートリアル >乱雑なテキストデータの Python 処理例
乱雑なテキストデータの Python 処理例

- PHP中文网オリジナル
- 2017-06-20 16:34:565611ブラウズ
1. 動作環境
1. Python バージョン 2.7.13. ブログのコードはこのバージョンです
2. システム環境: win7 64 ビット システム
いくつかのデータのスクリーンショットは次のとおりです。 、最初のフィールドは元のフィールドで、次の 3 つはクリーンアップされたフィールドです。データベース内の集計フィールドを観察すると、一見したところ、データは比較的規則的で、使用したい通貨の金額 10,000 元に似ています。条件判定を書いて一律に変換するSQL 「10,000元」という単位はSQLスクリプトで文字列をインターセプトするだけで完成しますが、条件が多すぎてデータが不規則で洗浄品質が定かでないことが後で判明しました。一部のフィールドには前に左括弧がありません。一部のフィールドには通貨が含まれていません。一部の数値は整数ではなく、一部の数値は 10,000 ワードを持たないため、数値と「10,000 元」の 2 つのフィールドに格納されます。 mysql にはテキストから数値を抽出できる関数が見つかりません。式は where 条件でよく使用されます。mysql にテキストのフィルタリングに似た関数があることを知っている人がいれば教えてください。テキストから数値を抽出するには、この方法でツールを学習して使用するのが最適です。
Python の使用経験と組み合わせると、Python には文字列フィルタリング用の関数が多数あります。このメソッドは、後のコードでテキストをフィルタリングするために使用されます。
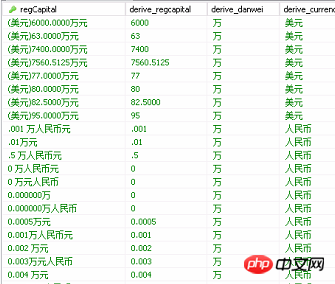 最初の部分クリーニングデータのスクリーンショット
最初の部分クリーニングデータのスクリーンショット3. データ処理のマクロロジックを考える
データを取得したら、急いでコードを書くのではなく、最初にクリーニングのロジックを考えることが、正しい方向に進むためには非常に重要です。残りの時間は、コード ロジックの実装とコード プロセスのデバッグにかかります。
3.1 コードを書かずに考えるプロセス:
私が達成したい最終的なデータクリーニングは、資金フィールドを [金額 + 単位 + 各通貨] または [金額 + 単位 + 統一人民元通貨] の組み合わせに変換することです (通貨交換)レート変換)、2 つまたは 3 つのステップで実行できます
3.1.1 数値、単位、通貨の 3 つのフィールドに分割します
(単位は万と万を除くに分けられ、通貨は人民元と人民元に分けられます)特定の外国通貨)
3.1.2 単位を万単位に統一します
最初のステップでは、単位の数値部分は万/10000ではなく、万の数値部分は変更されません
3.1。 3 通貨を統一します 人民元の場合
通貨は人民元で、最初の 2 つのフィールドは変更されず、数値以外の部分は数値になります*各外貨の人民元への為替レート、単位は変更されず、統一された「10」のままです2番目のステップで千'
3.2 各ステップのクリーニング効果データの列挙を期待します:
この結果から始めて、ステップごとに分解し、最初にクリーニングロジック部分を整理します
3.2.1 最初のステップで期待される効果クリーニングは 3 つのフィールドに分割されます。数値単位通貨:
① フィールド値 = "2000 RMB"、最初のクリーニング 2000 RMB (10,000 RMB を除く)2000 不含万 人民币
②字段值=“2000万元人民币”,第一次清洗2000 万 人民币
③字段值=“2000万元外币”, 第一次清洗2000 万 外币
3.2.2第二次清洗期望效果 将单位 统一归为万:
#二次处理条件case when 单位=‘万’ then 金额 else 金额/10000 end as 第二次金额
①字段值=“2000元人民币”0.2 万 人民币
②字段值=“2000万元人民币”2000 万 人民币
③字段值=“2000万元外币”2000 万 外币
注意:如果上面达到需求 则清洗完毕,如果想将单位换成人民币就进行下面三次清洗
3.2.3第三次清洗期望效果:单位 币种都统一为万+人民币
如果最后需求是换算成币种统一人民币,那么我们就在二次清洗后的基础上再写条件就好,
#三次处理条件case when 币种=‘人民币’ then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额
①字段值=“2000元人民币”0.2 万 人民币
②字段值=“2000万元人民币”2000 万 人民币
③字段值=“2000万元外币”2000*外币兑换人民币汇率 万 人民币
四、对具体代码的宏观逻辑思考
币种和单位这两个就2种情况,很好写
4.1、币种部分
这个条件简单,如果币种的值在字符中出现就让新字段等于这个币种的值即可。
4.2、单位(万为单位)
这个条件也简单,万字出现在字符中 单位这个变量=‘万’ 没出现就让单位变量等于‘不含万’,这样写是为了方便下一步对数字进行二次处理的时候写条件判断了。
4.3、数字部分 确保清洗后和原值逻辑上一样 做些判断
确保清洗后和原值逻辑上一样意思是假如有这样字段300.0100万清洗后变成300.01 万 人民币 也是正确的。
filter(str.isdigit,字段的值)这个代码我首先知道可以将文本中数字取出,同过对字段group by 聚合以后知道有小数点的字段,取出的值不再带有小数点,如‘20.01万’,filter(str.isdigit,‘20.01万’)②フィールド値 = "2000 万 RMB"、最初のクリーニング清掃
2000 万人民元③フィールド値 = "2000 万外貨"、1 回目の清掃
2000 万外貨3.2.2 2 回目の清掃で期待される効果1万に統一されます: #带小数点的以小数点分割 取出小数点前后部分进行拼接if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)#单位 以万和不含万 为统一if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万' #币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
①フィールド値 = "2000元"0.200万元
2000百万元
③フィールド値 = "2000 万元" 外貨"2000 万外貨

3.2.3 3 回目のクリーニングで期待される効果: 単位すべての通貨が万 + 人民元に統一されます最終要件が通貨を統一人民元に変換することである場合は、条件を記述するだけです。 2 回目のクリーニングに基づいて、
#coding:utf-8from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_datafor data in data_tuple:
item={}#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])if data[-2]:if len(data[-2]) >0 :
info=data[-2].encode('utf-8')else:
info=''if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万'if '美元' in info:
derive_currency='美元'elif '港币' in info:
derive_currency = '港币'elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'elif '澳元' in info:
derive_currency = '澳元'elif '英镑' in info:
derive_currency = '英镑'elif '加拿大元' in info:
derive_currency = '加拿大元'elif '日元' in info:
derive_currency = '日元'elif '港币' in info:
derive_currency = '港币'elif '法郎' in info:
derive_currency = '法郎'elif '欧元' in info:
derive_currency = '欧元'elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)#print len(old_data)for i in range(len(old_data)):if not old_data[i] :
old_data[i]=''else:pass
data2=old_data[i].replace('"','')
item[i+1]=data2print item[1] #插入测试环境 的表
project2.insert(item=item,db='local_db')①フィールド値 = "2000 RMB"
0.20000000 人民元②フィールド値 = "2000 万元"
2000 百万元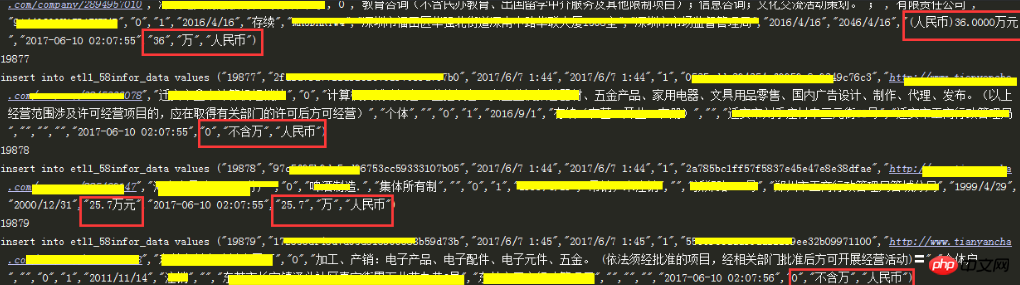
2000* 10,000 RMB の外国為替レートfilter(str.isdigital, field value)このコードでは、フィールドをグループ化することでテキスト内の数値を抽出できることが初めてわかり、小数点を含むフィールドは抽出されないことがわかりました。 '200,100' などの小数点を使用すると、filter(str.isdigit,'200,100') によって取り出される数値は 2001 になります。この数値は明らかに間違っているため、次の値が必要になります。小数点があるかどうかを考慮するには、小数点があるものは元のフィールドと同じである必要があります 🎜🎜 4. データベースのデータを読み込まずに初めてメインコードをクリーンアップします 🎜🎜 データベースから約 10 個の外れ値を抽出しますテスト中、info は regCapital フィールドの値です 🎜import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestoday🎜 5. すべてのコード: データベース データを読み取り、完全にクリーンアップします 🎜🎜 4 番目のステップは、コードが正しいことを確認するためにデータの一部をテストすることです。 、ロジックはマクロの観点から拡張され、情報変数はデータベースに動的に変更される必要があります。すべての値は完全にクリーンアップされます 🎜rrreee🎜 6. コード操作 🎜🎜6.1 データベースとフィールドの元のテーブル データを読み取ります。新しいテーブルによって作成されました🎜🎜🎜🎜🎜 データベースの元のテーブルデータと新しいテーブルによって作成されたフィールドを読み込みます🎜🎜🎜 6.2 新しいテーブルを挿入し、最初のデータクリーニングを実行します🎜🎜 赤枠部分がクリーニング部分です、その他のデータは感度が解除されています🎜🎜🎜🎜🎜新しいテーブルを挿入し、最初のデータ クリーニングを実行します🎜🎜6.3 数据表数据清洗结果
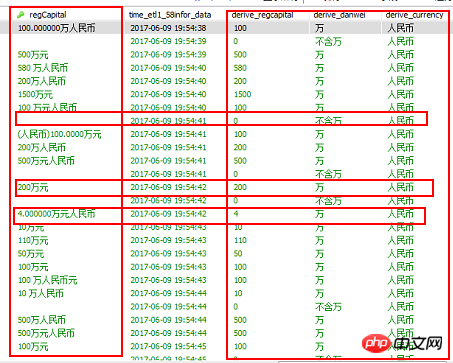
七、增量数据处理
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestoday以上が乱雑なテキストデータの Python 処理例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。