
ホームページ >バックエンド開発 >Python チュートリアル >DouTu.com から最新の絵文字を入手するにはどうすればよいですか?
DouTu.com から最新の絵文字を入手するにはどうすればよいですか?

- PHP中文网オリジナル
- 2017-06-20 14:29:442147ブラウズ
2: Scrapy の紹介
Scrapy は、Web サイトのデータをクロールし、構造データを抽出するために作成されたアプリケーション フレームワークです。 データマイニング、情報処理、履歴データの保存などの一連のプログラムで使用できます。
プロセスを使用する
Scrapyプロジェクトを作成する
- 抽出されたアイテムを定義する
- Webサイトを巡回してアイテムを抽出するスパイダーを作成する
- 抽出されたアイテムを保存するアイテムパイプラインを作成する(例: データ)
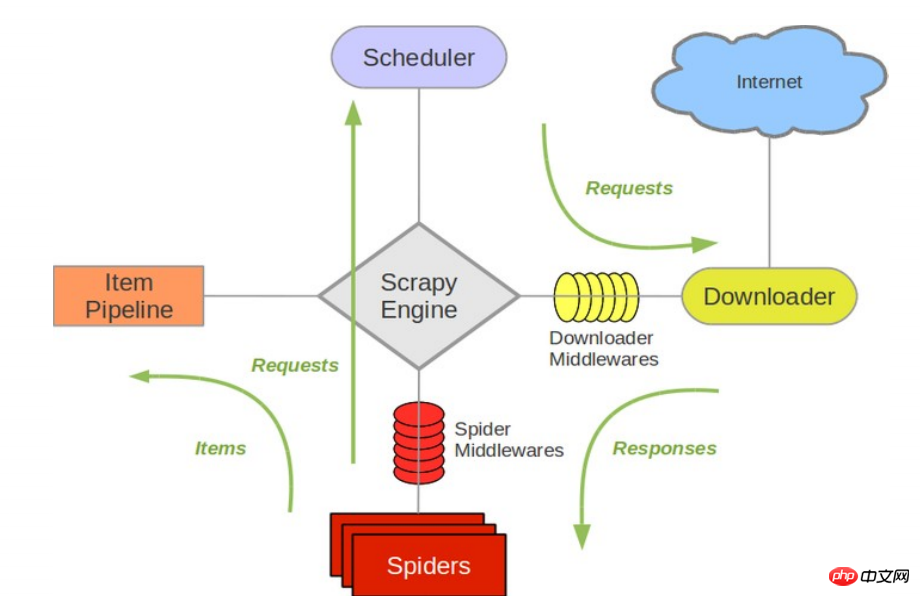
- 次の図は、システム内で発生するコンポーネントとデータ フロー (緑色の矢印で示す) の概要を含む、Scrapy のアーキテクチャを示しています。 以下に各コンポーネントの簡単な紹介と、詳細なコンテンツへのリンクを示します。データ フローについては以下で説明します
コンポーネント
- このエンジンは、システム内のすべてのコンポーネントを通るデータ フローを制御し、対応するアクションが発生したときにイベントをトリガーする役割を果たします。 詳細については、以下の「データ フロー」セクションを参照してください。
-
スケジューラ (スケジューラ) スケジューラはエンジンからリクエストを受け入れ、それらをキューに入れて、後でエンジンがリクエストしたときにエンジンに提供できるようにします。 -
ダウンローダー ダウンローダーは、ページ データを取得してエンジンに提供し、その後スパイダーに提供する責任があります。 -
Spiders Spider は、応答を分析し、アイテム (つまり、取得されたアイテム) または追加のフォローアップ URL を抽出するために Scrapy ユーザーによって作成されたクラスです。 各スパイダーは、特定の (またはいくつかの) Web サイトの処理を担当します。 詳細については「スパイダー」を参照してください。 -
Item Pipeline Item Pipeline は、スパイダーによって抽出されたアイテムの処理を担当します。一般的なプロセスには、クリーンアップ、検証、永続化 (データベースへのアクセスなど) が含まれます。 詳細については、「アイテム パイプライン」を参照してください。 -
ダウンローダーミドルウェア ダウンローダーミドルウェアは、エンジンとダウンローダーの間の特定のフックであり、ダウンローダーからエンジンに渡される応答を処理します。 カスタム コードを挿入することで Scrapy の機能を拡張する簡単なメカニズムを提供します。詳細については、「ダウンローダー ミドルウェア」を参照してください。 -
Spider ミドルウェア Spider ミドルウェアは、エンジンと Spider の間の特定のフックであり、Spider の入力 (応答) と出力 (項目と要求) を処理します。 カスタム コードを挿入することで Scrapy の機能を拡張する簡単なメカニズムを提供します。詳細については、「Spider ミドルウェア (ミドルウェア)」を参照してください。
1. ウェブサイトのホームページから最新の Dou Tu 絵文字を入力すると、URL は となり、2 ページ目をクリックすると URL が に変わることがわかります。 URL の構成は、ページ番号が異なります。次に、スパイダーの start_urls 開始エントリは次のように定義され、1 ページから 20 ページの画像式をクロールします。さらに絵文字ページをダウンロードしたい場合は、さらに追加することができます。
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 20)]
2. 開発者モードに入り、Web ページの構造を分析します。次の構造が表示されます。右クリックして xpath アドレスをコピーし、すべての式が配置されている a タグの内容を取得します。 a[1] は最初の a を表し、[1] を削除するとすべて a になります。 //*[@id="pic-detail"]/div/div[1]/div[2]/a
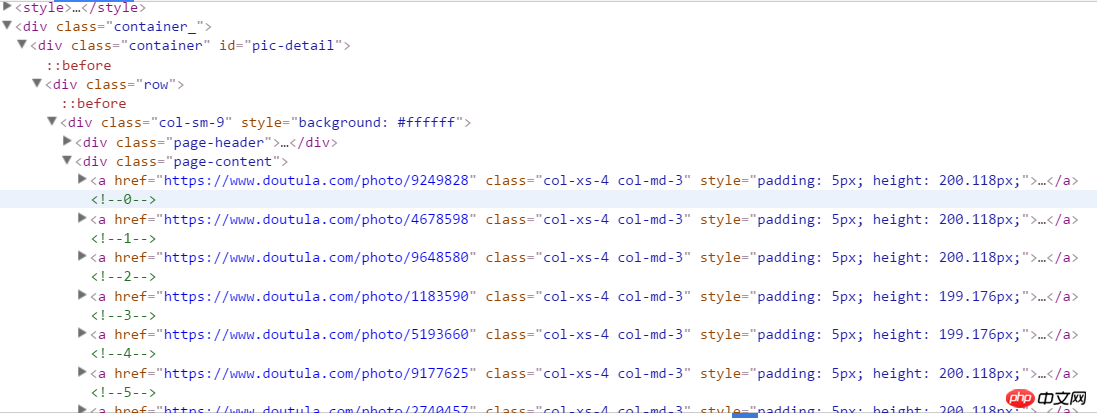
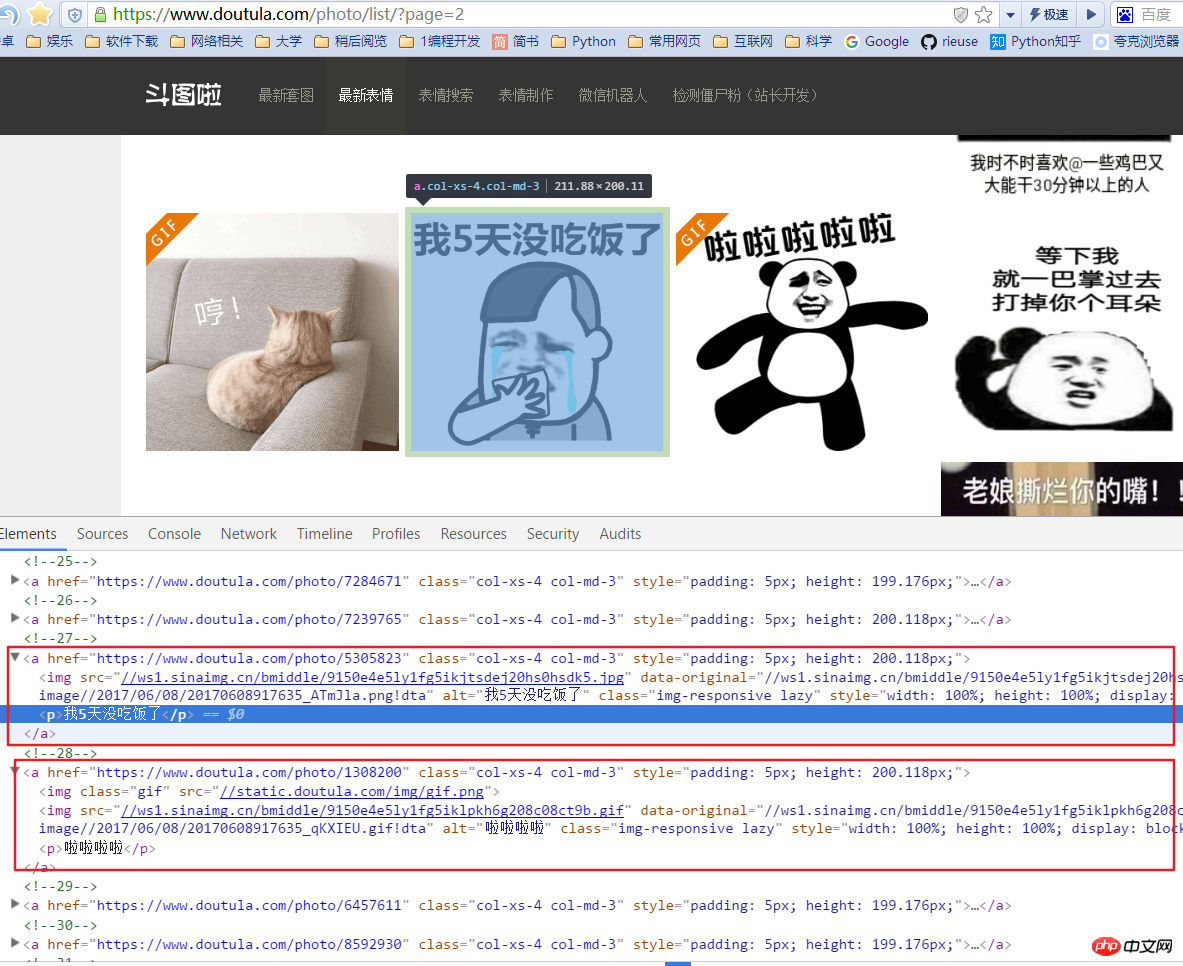
ここでは、jpg と gif の 2 種類の表現があることに注意してください。画像アドレスを取得する際に、aタグ以下の最初のimgのsrcだけを取得するとエラーが発生するため、img内のデータ元の値を取得する必要があります。ここでは画像の紹介であるaタグの下にpタグがあり、これも画像ファイルの名前として取得しています。
四:实战代码
完整代码地址 github.com/rieuse/learnPython
1.首先使用命令行工具输入代码创建一个新的Scrapy项目,之后创建一个爬虫。
scrapy startproject ScrapyDoutu cd ScrapyDoutu\ScrapyDoutu\spidersscrapy genspider doutula doutula.com
2.打开Doutu文件夹中的items.py,改为以下代码,定义我们爬取的项目。
import scrapyclass DoutuItem(scrapy.Item):
img_url = scrapy.Field()
name = scrapy.Field()3.打开spiders文件夹中的doutula.py,改为以下代码,这个是爬虫主程序。
# -*- coding: utf-8 -*-
import os
import scrapy
import requestsfrom ScrapyDoutu.items import DoutuItems
class Doutu(scrapy.Spider):
name = "doutu"
allowed_domains = ["doutula.com", "sinaimg.cn"]
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 40)] # 我们暂且爬取40页图片
def parse(self, response):
i = 0for content in response.xpath('//*[@id="pic-detail"]/div/div[1]/div[2]/a'):
i += 1item = DoutuItems()item['img_url'] = 'http:' + content.xpath('//img/@data-original').extract()[i]item['name'] = content.xpath('//p/text()').extract()[i]try:if not os.path.exists('doutu'):
os.makedirs('doutu')
r = requests.get(item['img_url'])
filename = 'doutu\\{}'.format(item['name']) + item['img_url'][-4:]with open(filename, 'wb') as fo:
fo.write(r.content)
except:
print('Error')
yield item3.这里面有很多值得注意的部分:
因为图片的地址是放在sinaimg.cn中,所以要加入allowed_domains的列表中
content.xpath('//img/@data-original').extract()[i]中extract()用来返回一个list(就是系统自带的那个) 里面是一些你提取的内容,[i]是结合前面的i的循环每次获取下一个标签内容,如果不这样设置,就会把全部的标签内容放入一个字典的值中。filename = 'doutu\{}'.format(item['name']) + item['img_url'][-4:]是用来获取图片的名称,最后item['img_url'][-4:]是获取图片地址的最后四位这样就可以保证不同的文件格式使用各自的后缀。最后一点就是如果xpath没有正确匹配,则会出现64d8292994d119f5f1f87748047c90da (referer: None)
4.配置settings.py,如果想抓取快一点CONCURRENT_REQUESTS设置大一些,DOWNLOAD_DELAY设置小一些,或者为0.
# -*- coding: utf-8 -*-BOT_NAME = 'ScrapyDoutu'SPIDER_MODULES = ['ScrapyDoutu.spiders']NEWSPIDER_MODULE = 'ScrapyDoutu.spiders'DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'ScrapyDoutu.middlewares.RotateUserAgentMiddleware': 400,
}ROBOTSTXT_OBEY = False # 不遵循网站的robots.txt策略CONCURRENT_REQUESTS = 16 #Scrapy downloader 并发请求(concurrent requests)的最大值DOWNLOAD_DELAY = 0.2 # 下载同一个网站页面前等待的时间,可以用来限制爬取速度减轻服务器压力。COOKIES_ENABLED = False # 关闭cookies5.配置middleware.py配合settings中的UA设置可以在下载中随机选择UA有一定的反ban效果,在原有代码基础上加入下面代码。这里的user_agent_list可以加入更多。
import randomfrom scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
print(ua)
request.headers.setdefault('User-Agent', ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]6.到现在为止,代码都已经完成了。那么开始执行吧!scrapy crawl doutu
之后可以看到一边下载,一边修改User Agent。
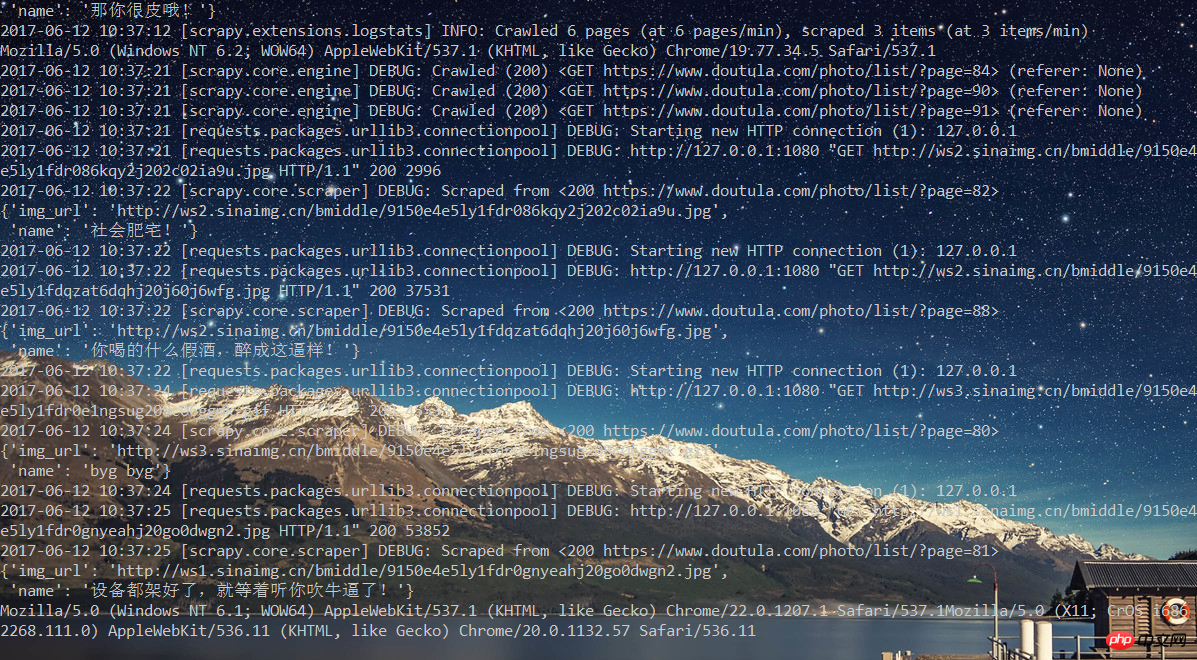
五:总结
学习使用Scrapy遇到很多坑,但是强大的搜索系统不会让我感觉孤单。所以感觉Scrapy还是很强大的也很意思,后面继续学习Scrapy的其他方面内容。
以上がDouTu.com から最新の絵文字を入手するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。