
ホームページ >バックエンド開発 >Python チュートリアル >Scrapy クローラー フレームワークの概要
Scrapy クローラー フレームワークの概要

- PHP中文网オリジナル
- 2017-06-20 17:19:392450ブラウズ
scrapy クローラーフレームワークのご紹介
インストール方法: pip installscrapy でインストールできます。 condaでscrapyをインストールするにはanacondaコマンドを使用します。 1 エンジンは Spider Request からクロール リクエストを取得します
4 エンジンはミドルウェアを介してクローリング リクエストをダウンローダーに送信します5 Web ページをクロールした後、ダウンローダーは応答 (Response) を作成し、ミドルウェアを介してエンジンに送信します
6 エンジンは受信した応答をダウンローダーに送信しますスパイダーは、エンジン処理用のミドルウェアを介して、スケジューリングのためにスケジューラーに転送されます 7 スパイダーは、応答を処理し、スクレイピングされたアイテム (スクレイピングされたアイテム)
7 スパイダーは、応答を処理し、スクレイピングされたアイテム (スクレイピングされたアイテム)
8 エンジンは、スクレイピングされたアイテムを、アイテムパイプライン (フレームワーク終了)
9 エンジンはスケジューラーにクローリングリクエストを送信しますエンジンは各モジュールのデータフローを制御し、リクエストが空になるまでスケジューラーからクローリングリクエストを継続的に取得します<br>フレームエントリ: Spiderの最初のクローリングリクエスト
フレーム出口: アイテムPipelinem<br> <br><br>
<br><br> <br>
<br><br><br>
(1) すべてのモジュール間のデータフローを制御します(2) 条件に従ってイベントをトリガーします
ユーザーが変更する必要はありませんダウンローダー
リクエストに応じて Web ページをダウンロードします
ユーザーによる変更は必要ありませんスケジューラー<br>すべてのクロール リクエストのスケジュールと管理 ユーザーによる変更は必要ありません<br><br>
ダウンローダー ミドルウェア目的: エンジン、スケジューラー、ダウンローダー間のユーザー構成機能を実装します制御<br>機能: リクエストまたはレスポンスを変更、破棄、追加<br>ユーザーは設定コードを記述することができます
Spider<br>(1) ダウンローダーによって返されたレスポンスを解析します<br>(2) スクレイピングされたアイテムを生成します
(3) 追加のクローリングリクエストを生成します(リクエスト)ユーザーに構成コードの作成を要求する<br>アイテムパイプライン<br><br>(1) Spiderによって生成されたクロールされたアイテムをパイプライン方式で処理します<br>(2) パイプラインと同様に一連の操作シーケンスで構成され、各操作
はアイテム パイプライン タイプ(3) 可能な操作には以下が含まれます: クロールされたアイテム内の HTML データのクリーニング、チェック、重複チェック、データベースへのデータの保存 ユーザーは構成コードを記述する必要があります <br><br> 理解しました 基本的な概念を理解したら、書き始めましょう最初のスクレイピークローラー。 <br><br>まず、新しいクローラープロジェクトscrapy startproject xxx (プロジェクト名)を作成します
<br>このクローラーは、小説サイトのタイトルと作者をクロールするだけです。 <br><br>クローラー プロジェクト ブックを作成したので、その構成を編集しましょう<br><br><br>
次に、第 1 レベルのブック ディレクトリの下にブックを作成します。start.py は、IDE で Scrapy クローラーを実行するために使用されます。ファイルに次のコードを記述します。 最初の2つのパラメーターが固定されており、3番目のパラメーターはクモの名前です次に、Items のフィールドに次のように入力します:
そして、スパイダー内に爬虫類マスター プログラム Book.py
を作成します。小説では、Web サイトのアドレスが 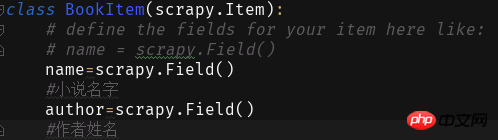 +Novel Type Pinyin であることがわかります。 .html
+Novel Type Pinyin であることがわかります。 .html
これを介してWebページのコンテンツを読み書きします
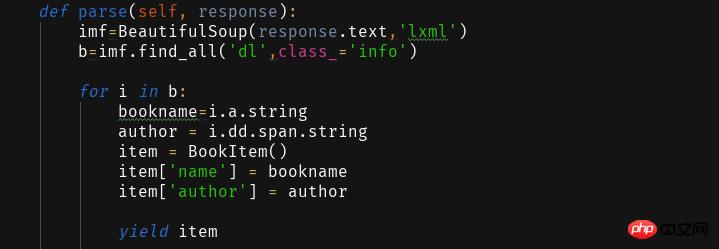
これを取得した後、取得したWebページをparse関数を使用して解析し、必要な情報を抽出します。
Webページ分析抽出データはBeautifulSoupライブラリを通じて取得されますが、ここでは省略します。 2333を自分で分析してください~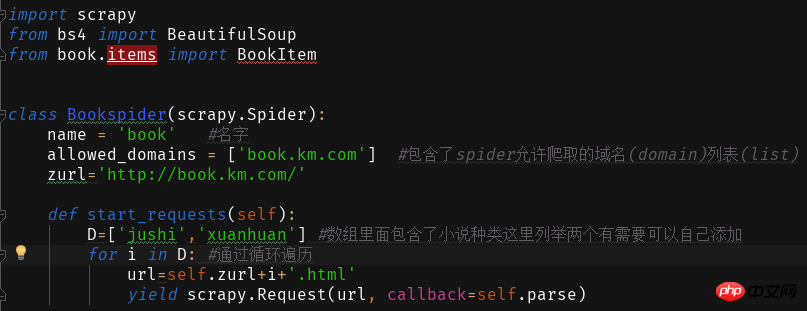 プログラムを書いた後、クロールした情報を保存したい場合はPipelines.pyを編集する必要があります
プログラムを書いた後、クロールした情報を保存したい場合はPipelines.pyを編集する必要があります
これを正常に実行するには、setting.py で
<span style="color: #000000">ITEM_PIPELINES = { 'book.pipelines.xxx': 300,}<br>xxx为存储方法的类名,想用什么方法存储就改成那个名字就好运行结果没什么看头就略了<br>第一个爬虫框架就这样啦期末忙没时间继续完善这个爬虫之后有时间将这个爬虫完善成把小说内容等一起爬下来的程序再来分享一波。<br>附一个book的完整代码:<br></span>
import scrapyfrom bs4 import BeautifulSoupfrom book.items import BookItemclass Bookspider(scrapy.Spider):
name = 'book' #名字
allowed_domains = ['book.km.com'] #包含了spider允许爬取的域名(domain)列表(list)
zurl=''def start_requests(self):
D=['jushi','xuanhuan'] #数组里面包含了小说种类这里列举两个有需要可以自己添加for i in D: #通过循环遍历
url=self.zurl+i+'.html'yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
imf=BeautifulSoup(response.text,'lxml')
b=imf.find_all('dl',class_='info')for i in b:
bookname=i.a.stringauthor = i.dd.span.stringitem = BookItem()
item['name'] = bookname
item['author'] = authoryield item
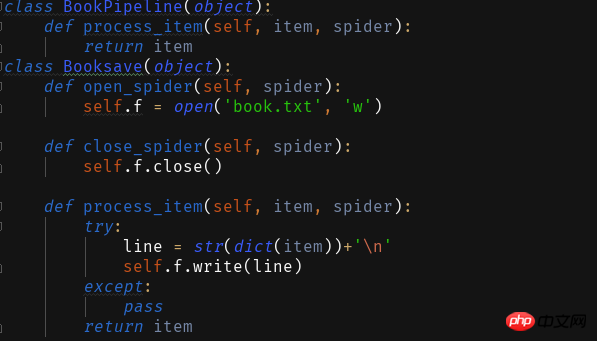
<br>を構成する必要もあります
以上がScrapy クローラー フレームワークの概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。