
ホームページ >Java >&#&チュートリアル >spring-cloud-sleuth+zipkin 追跡サービスの実装 (2)
spring-cloud-sleuth+zipkin 追跡サービスの実装 (2)
- 巴扎黑オリジナル
- 2017-06-26 11:09:162153ブラウズ
1. 簡単な説明
前のセクション「spring-cloud-sleuth+zipkin 追跡サービスの実装 (1)」では、microservice-zipkin-server、microservice-zipkin-client、microservice-zipkin-client-backend の 3 つを使用しました。プログラムは、メモリ内での通信とデータの永続化のために http メソッドを使用したサービス呼び出しリンク トラッキングを実装します。
ここでは 2 つの変更を加えます。1 つ目は、データがメモリに保存されるものからデータベースに永続化されるように変更されることです。2 つ目は、http 通信が mq 非同期通信に変更されることです。
誰もが違いを確認できるように、前のセクションの 3 つのプログラムを引き続き使用して修正を加えます。ここでは、違いを示すために各プロジェクト名にストリームが追加されています。
2. microservice-zipkin-stream-server
http メソッドを MQ 経由の通信に変更するには、元の依存関係のある io.zipkin.java:zipkin-server を spring-cloud-sleuth-zipkin-Stream に置き換える必要があります。 spring-cloud-starter-stream-rabbit
mysql 永続性を同時に使用するには、mysql 関連の依存関係を追加する必要があります。
すべての Maven 依存関係は次のとおりです:
" <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--zipkin依赖--> <!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> "
上記の Maven 依存関係を追加した後、スタートアップ クラス ZipkinServer の @EnableZipkinServer アノテーションを @EnableZipkinStreamServer に置き換えます。
詳細は次のとおりです:
package com.yangyang.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* Created by chenshunyang on 2017/5/24.
*/
@EnableZipkinStreamServer// //使用Stream方式启动ZipkinServer
@SpringBootApplication
public class ZipkinStreamServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinStreamServerApplication.class,args);
}
}
のソース コードをクリックします@EnableZipkinStreamServer アノテーションも導入されており、@EnableZipkinServer アノテーションも Rabbit-MQ メッセージ キュー リスナーを作成することがわかります。 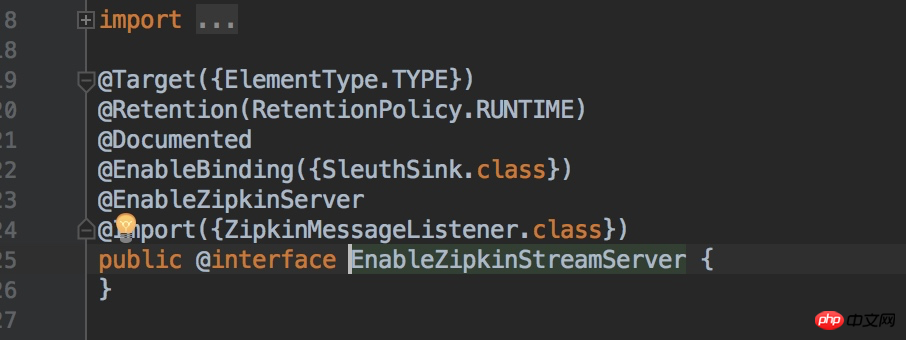
メッセージクライアントから送信された mq メッセージの受信を容易にするため。
メッセージミドルウェアのrabbit mqとmysqlを使用するため、設定ファイルapplication.propertiesに関連する設定を追加する必要もあります:
server.port=11020 spring.application.name=microservice-zipkin-stream-server #zipkin数据保存到数据库中需要进行如下配置 #表示当前程序不使用sleuth spring.sleuth.enabled=false #表示zipkin数据存储方式是mysql zipkin.storage.type=mysql #数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素 spring.datasource.schema[0]=classpath:/zipkin.sql #spring boot数据源配置 spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.initialize=true spring.datasource.continue-on-error=true #rabbitmq配置 spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
その中で、zipkin.sqlは公式Webサイトに直接コピーするか、コピーすることができますこのデモから
http 通信からの干渉を避けるために、元のリスニング ポートを 11008 から 11020 に変更してプログラムを開始しました。エラーは報告されず、プログラムが正常に開始されたことを示すウサギの接続ログが確認できました。
3.microservice-zipkin-stream-client、microservice-zipkin-client-stream-backend
前のセクションの構成と同様に、クライアントの構成も非常にシンプルです。Maven の依存関係には、元の spring-cloud のみが必要です。 - starter-zipkin を次の 2 つの依存関係に置き換えるだけです
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
さらに、構成ファイルに MQ に接続するための構成を追加します
server: port: 11021 spring: application: name: microservice-zipkin-stream-client #rabbitmq配置 rabbitmq: host: 127.0.0.1 port : 5672 username: guest password: guest
もちろん、違いを示すために、ポートもそれに応じて調整されています
4. テスト
アクセス: http://localhost:11021/call/1 前のセクションと同様に、rabbit-mq 通信の sleuth 機能が有効になったことを説明します。
私たちは消費者のアドレスを何度も訪問しており、リクエストにかかる時間が突然長くかかるわけではないことがログで確認できます。
MQ 通信がもたらすデータ損失がない機能を体験するために、データベース内のデータをクリアしてから、zipkin サーバー インターフェイスを更新します。データがなくなっていることがわかります
その後、閉じます。その後、zipkin サーバー プログラムを再起動すると、すぐに [スパン名] オプションにデータが表示されることがわかります。この時点では、データベース内のレコード数は以前と同じではなくなり、エントリが 0 になりました
以上がspring-cloud-sleuth+zipkin 追跡サービスの実装 (2)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。