結論LinkKeyedHashMapが空の
|
を許可するかどうかについての議論は許可されています |
| LinkedHashMap 重複データが許可されているかどうか許可されています |
キーの重複は上書きされます、値の重複は許可されています
|
LinkedHashMapは注文されていますか?LinkedHashMapの基本構造
LinkedHashMapについて、2つの点について触れておきます:
1. LinkedHashMapはHashMap+LinkedListと考えることができます。つまり、HashMapを使用してデータ構造を操作し、 LinkedLは挿入された要素の順序を維持します
2. LinkedHashMapの基本的な実装アイデアは---ポリモーフィズムです。ポリモーフィズムを理解してから LinkedHashMap の原理を理解すると、半分の労力で 2 倍の成果が得られると言えます。逆に、LinkedHashMap の原理を学習すると、ポリモーフィズムの理解が促進され、深まります。
なぜこのようなことが言えるのでしょうか? まず、LinkedHashMap の定義を見てください:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
} LinkedHashMap は HashMap のサブクラスであることを確認してください。当然のことながら、LinkedHashMap は HashMap のすべての非プライベート メソッドも継承します。 LinkedHashMap のメソッドを見てみましょう:
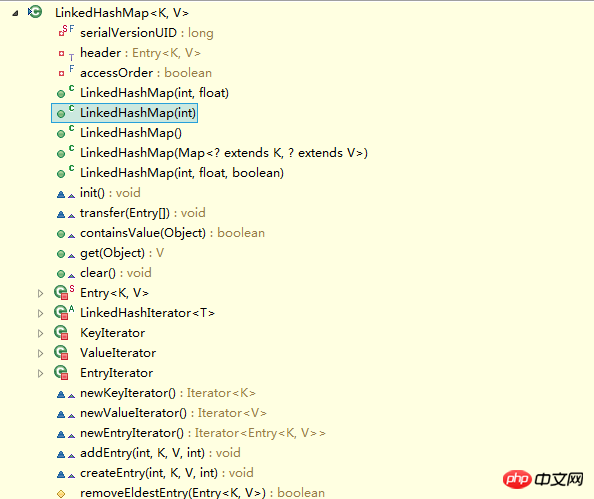 LinkedHashMap にはデータ構造を操作するメソッドがないことがわかります。つまり、LinkedHashMap はデータ構造を操作します (データの配置など)。これは HashMap とまったく同じです。データを操作します。細部にいくつかの違いがあるだけです。
LinkedHashMap にはデータ構造を操作するメソッドがないことがわかります。つまり、LinkedHashMap はデータ構造を操作します (データの配置など)。これは HashMap とまったく同じです。データを操作します。細部にいくつかの違いがあるだけです。
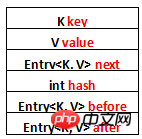
LinkedHashMap と HashMap の違いは、基本的なデータ構造にあります。Entry:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}である LinkedHashMap の基本的なデータ構造を見てください。Entry:
next は、HashMap の指定されたテーブル位置にある接続されたエントリの順序を維持するために使用されます。 before と After は、エントリの挿入順序を維持するために使用されます。 図で示して属性をリストしてみましょう:
 LinkedHashMapを初期化する
LinkedHashMapを初期化する
次のようなコードがあるとします:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}まず、3〜4行目で、新しいLinkedHashMapが出てきます。 , 何が行われるかを見てみましょう: public LinkedHashMap() {
super();
accessOrder = false;
} public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
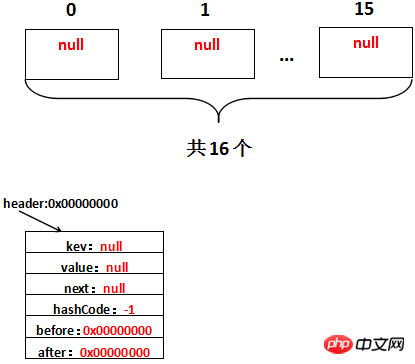
}void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header;
ここで最初のポリモーフィズムが表示されます: init() メソッドです。 init() メソッドは HashMap で定義されていますが、理由は次のとおりです: 1. LinkedHashMap は init メソッド を書き換えます。インスタンス化されるのは LinkedHashMap であるため、実際に呼び出される init メソッドは LinkedHashMap によって書き換えられた init メソッドです。ヘッダーのアドレスが 0x00000000 であると仮定すると、初期化後は実際には次のようになります:
 LinkedHashMap は要素を追加します
LinkedHashMap は要素を追加します
引き続き LinkedHashMap が要素を追加する様子、つまり put("111", "111") は、もちろん最初に HashMap の put メソッドを呼び出します:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} 17 行目は別の多態性です。LinkedHashMap が addEntry メソッドを書き換えるため、addEntry は LinkedHashMap によって書き換えられたメソッドを呼び出します: void addEntry(int hash, K key, V value, int bucketIndex) {
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
} Because LinkedHashMap 自体挿入順序が維持されるため、LinkedHashMap をキャッシュ
に使用できます。 5 行目から 7 行目は FIFO アルゴリズムをサポートするために使用されているため、当面は気にする必要はありません。 createEntry メソッドを見てください:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
} 2 行目から 4 行目のコードは、新しく追加された要素が table[i] に配置される点が異なります。 addBefore オペレーション。これらの 4 行のコードの意味は、新しいエントリと元のリンク リストの間に二重リンク リストを生成することです。
文字列
111 がロケーション テーブル [1] に配置され、生成されたエントリ アドレスが 0x00000001 であると仮定すると、グラフィック表現は次のようになります。
LinkedList のソース コードに精通している場合は、次のようになります。理解するのは難しくないので、説明しましょう。以下の既存のエントリはヘッダーを表します。
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001
这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的:

就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。
总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。
利用LinkedHashMap实现LRU算法缓存
前面讲了LinkedHashMap添加元素,删除、修改元素就不说了,比较简单,和HashMap+LinkedList的删除、修改元素大同小异,下面讲一个新的内容。
LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已:
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点:
1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致
2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU
那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。
我们看一下LinkedList带boolean型参数的构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}就是这个accessOrder,它表示:
(1)false,所有的Entry按照插入的顺序排列
(2)true,所有的Entry按照访问的顺序排列
第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。
"访问",这个词有两层意思:
1、根据Key拿到Value,也就是get方法
2、修改Key对应的Value,也就是put方法
首先看一下get方法,它在LinkedHashMap中被重写:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}然后是put方法,沿用父类HashMap的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}修改数据也就是第6行~第14行的代码。看到两端代码都有一个共同点:都调用了recordAccess方法,且这个方法是Entry中的方法,也就是说每次的recordAccess操作的都是某一个固定的Entry。
recordAccess,顾名思义,记录访问,也就是说你这次访问了双向链表,我就把你记录下来,怎么记录?把你访问的Entry移到尾部去。这个方法在HashMap中是一个空方法,就是用来给子类记录访问用的,看一下LinkedHashMap中的实现:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}private void remove() {
before.after = after;
after.before = before;
}private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}看到每次recordAccess的时候做了两件事情:
1、把待移动的Entry的前后Entry相连
2、把待移动的Entry移动到尾部
当然,这一切都是基于accessOrder=true的情况下。最后用一张图表示一下整个recordAccess的过程吧:

代码演示LinkedHashMap按照访问顺序排序的效果
最后代码演示一下LinkedList按照访问顺序排序的效果,验证一下上一部分LinkedHashMap的LRU功能:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator();
while (iterator.hasNext())
{
System.out.print(iterator.next() + "\t");
}
System.out.println();
}注意这里的构造方法要用三个参数那个且最后的要传入true,这样才表示按照访问顺序排序。看一下代码运行结果:
111=111 222=222 333=333 444=444
222=222 333=333 444=444 111=111
333=333 444=444 111=111 222=2222
代码运行结果证明了两点:
1、LinkedList是有序的
2、每次访问一个元素(get或put),被访问的元素都被提到最后面去了
【相关推荐】
1. Java免费视频教程
2. 全面解析Java注解
3. Java教程手册

