
ホームページ >バックエンド開発 >Python チュートリアル >Python クローラーでキャプチャしたデータを PDF に変換する
Python クローラーでキャプチャしたデータを PDF に変換する

- Y2Jオリジナル
- 2017-05-08 16:56:051943ブラウズ
この記事では、Python クローラーを使用して「Liao Xuefeng の Python チュートリアル」を PDF に変換する方法とコードを共有します。必要な友人はそれを参照してください。
クローラーを作成するには、Python を使用するより適切な方法はないようです。 、Python コミュニティによって提供されています。 目がくらむほど多くのクローラー ツールがあり、直接使用できるさまざまなライブラリを使用して、数分でクローラーを作成できます。 今日は、Liao Xuefeng の Python チュートリアルをダウンロードしました。誰もがオフラインで読めるように PDF 電子書籍にしました。
クローラーを書き始める前に、まず Web サイトのページ構造を分析しましょう 1. Web ページの左側はチュートリアルのディレクトリの概要であり、各 URL は右側の記事に対応しています。記事のタイトル、中央は記事のテキスト部分です。クロールしたいデータはすべての Web ページのテキスト部分です。コメント領域はありません。私たちには慣れているので無視して構いません。
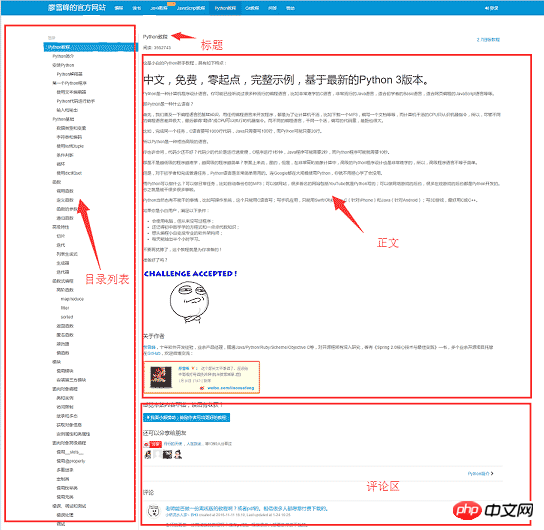
ツールの準備
Web サイトの基本構造を理解したら、クローラーが依存するツールキットの準備を開始できます。 request と beautifulsoup はクローラーの 2 つの主要なアーティファクトであり、reuqests はネットワーク リクエストに使用され、beautifusoup は HTML データの操作に使用されます。これら 2 つのシャトルを使用すると、小さなプログラムでのクローラーフレームワークを必要とせずに素早く作業できます。さらに、HTML ファイルを PDF に変換するため、wkhtmltopdf は、複数のプラットフォームに適した HTML を PDF に変換できる非常に優れたツールです。まず次の依存関係パッケージをインストールしてから、wkhtmltopdfをインストールします
wkhtmltopdfをインストールしますWindowsプラットフォームは、wkhtmltopdf公式Webサイトから安定版を直接ダウンロードします。 2 インストールが完了したら、インストールの実行パスを追加します。プログラムをシステム環境 $PATH
変数 に追加しないと、pdfkit は wkhtmltopdf を見つけることができず、「wkhtmltopdf 実行可能ファイルが見つかりません」というエラーが表示されます。 Ubuntu と CentOS は、コマンド ラインを使用して直接インストールできますpip install requests
pip install beautifulsoup
pip install pdfkit
すべての準備ができたら、コーディングを開始できますが、コードを記述する前に考えを整理する必要があります。このプログラムの目的は、すべての URL に対応する HTML テキスト部分をローカルに保存し、pdfkit を使用してこれらのファイルを PDF ファイルに変換することです。まずタスクを分割して、特定の URL に対応する HTML テキストをローカルに保存し、次にすべての URL を検索して同じ操作を実行します。
Chrome ブラウザを使用してページの本文部分でタグを見つけ、F12 キーを押して本文に対応する p タグを見つけます: 05ff9a9e18a7aecf8acff32163179ec7 (p は本文の内容)ウェブページの。リクエストを使用してページ全体をローカルにロードした後、 beautifulsoup を使用して HTML dom 要素を操作し、テキスト コンテンツを抽出できます。
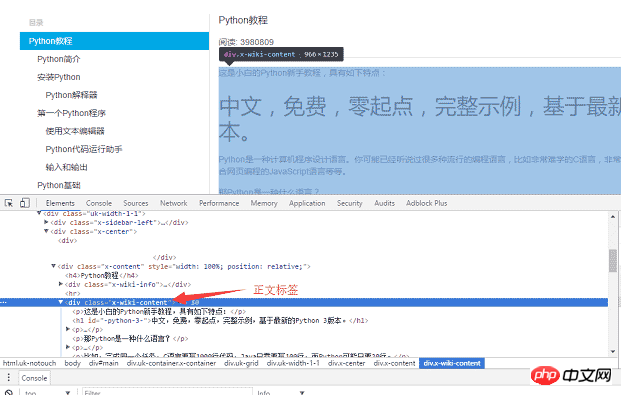
05ff9a9e18a7aecf8acff32163179ec7,该 p 是网页的正文内容。用 requests 把整个页面加载到本地后,就可以使用 beautifulsoup 操作 HTML 的 dom 元素 来提取正文内容了。
具体的实现代码如下:用 soup.find_all 函数找到正文标签,然后把正文部分的内容保存到 a.html 文件中。
$ sudo apt-get install wkhtmltopdf # ubuntu $ sudo yum intsall wkhtmltopdf # centos
第二步就是把页面左侧所有 URL 解析出来。采用同样的方式,找到 左侧菜单标签 818516a2aea8c5412fd444e4ed52d34a 具体的な実装コードは次のとおりです: スープを使用します.find_all 関数
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)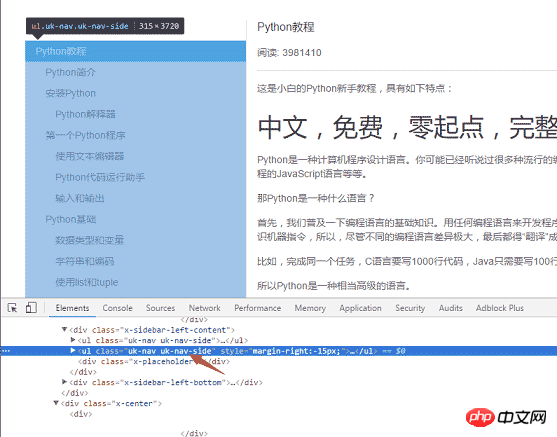 2 番目のステップは、ページの左側にあるすべての URL を解析することです。同様に、左側のメニュー ラベル
2 番目のステップは、ページの左側にあるすべての URL を解析することです。同様に、左側のメニュー ラベル 818516a2aea8c5412fd444e4ed52d34a を見つけます
特定のコード実装ロジック: uk-nav uk-nav-side の 2 つのクラス 属性があるためです。ページ
であり、実際のディレクトリのリストは 2 番目です。すべての URL が取得され、URL を HTML に変換する関数が最初のステップで記述されました。def get_url_list():
"""
获取所有URL目录列表
"""
response = requests.get("http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000")
soup = BeautifulSoup(response.content, "html5lib")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls最後のステップは、html を pdf ファイルに変換することです。 pdfkit はすべてのロジックをカプセル化しているため、pdf ファイルへの変換は非常に簡単です。関数 pdfkit.from_filedef save_pdf(htmls):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options) を呼び出して save_pdf 関数を実行するだけで、電子書籍の PDF ファイルが生成されます。
を呼び出して save_pdf 関数を実行するだけで、電子書籍の PDF ファイルが生成されます。
要約
コードの総量は 50 行未満になります。ただし、実際には、上記のコードでは、記事のタイトルを取得する方法など、いくつかの詳細が省略されています。テキストコンテンツの img タグは相対パスを使用しています。 PDF で写真を通常に表示したい場合は、相対パスを絶対パスに変更する必要があり、保存されている一時 HTML ファイルを削除する必要があります。これらの詳細はすべて github に投稿されています。
【関連おすすめ】
以上がPython クローラーでキャプチャしたデータを PDF に変換するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。