
ホームページ >データベース >mysql チュートリアル >一般的に使用される SQL Server 仕様のコレクション
一般的に使用される SQL Server 仕様のコレクション
- 巴扎黑オリジナル
- 2017-05-01 11:25:151516ブラウズ
共通フィールドタイプの選択
1.文字型にはvarchar/nvarcharデータ型を使用することを推奨します
2. 金額通貨には通貨データ型を使用することをお勧めします
3. 科学表記法には数値データ型を使用することをお勧めします
4. 自己増加ロゴにはbigintデータ型を使用することをお勧めします(データ量が多くてint型では収まりきらず、後々変換が面倒になります)
5. 時刻型は日時データ型を推奨します
6. text、ntext、imageの古いデータタイプの使用は禁止されています
7. XMLデータ型、varchar(max)、nvarchar(max)の使用は禁止です
制約とインデックス
すべてのテーブルには主キーが必要です
エンティティの整合性を強制するには、各テーブルに主キーが必要です
1 つのテーブルには 1 つの主キーのみを含めることができます (空のデータと重複データは許可されません)
単一フィールドの主キーを使用してみてください
外部キーは許可されません
外部キーにより、テーブル構造の変更とデータ移行が複雑になります
外部キーは挿入と更新のパフォーマンスに影響します
データの整合性はプログラムによって制御されます
NULL 属性
新しく追加したテーブルでは、すべてのフィールドで NULL を禁止します
(新しいテーブルでは NULL が許可されないのはなぜですか?
NULL 値を許可すると、アプリケーションの複雑さが増加します。さまざまな予期せぬバグを防ぐために、特定のロジック コードを追加する必要があります
3 値ロジック。等号 ("=) を含むすべてのクエリには isnull 判定を追加する必要があります。
Null=Null、Null!=Null、not(Null=Null)、not(Null!=Null) はすべて不明、真ではありません)
例で説明しましょう:
テーブル内のデータが図に示されている場合:

aa に等しい名前を除くすべてのデータを検索したいのに、誤って SELECT * FROM NULLTEST WHERE NAME<>'aa'
を使用してしまいました。 結果は予想とは異なりました。実際、name=bb のデータ レコードのみが見つかりましたが、name=NULL のデータ レコードは見つかりませんでした
。 では、aa に等しい名前以外のすべてのデータを見つけるにはどうすればよいでしょうか? ISNULL 関数を使用することしかできません
SELECT * FROM NULLTEST WHERE ISNULL(NAME,1)<>'aa'
ただし、ISNULL が深刻なパフォーマンスのボトルネックを引き起こす可能性があることはご存じないかもしれません。そのため、多くの場合、ユーザーがクエリを実行する前に有効なデータを入力できるように、アプリケーション レベルでユーザー入力を制限することが最善です。
古いテーブルに追加される新しいフィールドは、NULL を許可する必要があります (テーブル全体のデータ更新と長期ロック保持によるブロックを避けるため) (これは主に前のテーブルの変換によるものです)
インデックスのデザインガイドライン
インデックスは、WHERE 句で頻繁に使用される列に作成する必要があります
インデックスは、テーブルの結合に頻繁に使用される列に作成する必要があります
インデックスは、ORDER BY 句で頻繁に使用される列に作成する必要があります
小さいテーブル (数ページしか使用しないテーブル) にはインデックスを作成しないでください。これは、テーブル全体のスキャン操作の方が、インデックスを使用して実行されるクエリよりも高速である可能性があるためです
1 つのテーブル内のインデックスの数は 6 を超えません
選択性の低いフィールドには単一列インデックスを構築しないでください
独自の制約を使いこなしましょう
インデックスには 5 つ以下のフィールドが含まれます (列を含む)
選択性の低いフィールドには単一列インデックスを作成しないでください
SQL SERVER にはインデックス フィールドの選択性に関する要件があります。選択性が低すぎる場合、SQL SERVER は使用を放棄します
。 インデックスの作成に適さないフィールド: 性別、0/1、TRUE/FALSE
インデックスの作成に適したフィールド: ORDERID、UID など
独自のインデックスを使いこなしましょう
一意のインデックスは、特定の列に重複する値がまったく存在しないことを保証する情報を SQL Server に提供します。クエリ アナライザーは一意のインデックスを通じてレコードを見つけると、すぐに終了し、インデックスの検索を続行しません
。 テーブルインデックスの数は6を超えません
テーブルインデックスの数は 6 を超えてはなりません (このルールはテスト後に Ctrip DBA によってのみ策定されます...)
インデックスはクエリを高速化しますが、書き込みパフォーマンスに影響します
テーブルのインデックスはテーブルに関係するSQLを全て組み合わせて包括的に作成し、可能な限りマージするようにしてください
複合インデックスの原理は、フィルタリング性の高いフィールドが上位に配置されることです
インデックスが多すぎると、コンパイル時間が長くなるだけでなく、最適な実行プランを選択するデータベースの機能にも影響します
SQLクエリ
データベース内で複雑な操作を実行することは禁止されています
選択 *
インデックス付き列で関数や計算を使用することは禁止されています
カーソルは禁止です
トリガーは禁止です
クエリ内でインデックスを指定することは禁止されています
変数/パラメータ/関連するフィールドのタイプは、フィールドのタイプと一致している必要があります
パラメータ化されたクエリ
JOIN の数を制限する
SQL ステートメントの長さと IN 句の数を制限する
大規模なトランザクション操作は避けるようにしてください
影響を受ける行数情報をオフにすると
が返されます 必要な場合を除き、SELECT ステートメントに NOLOCK を追加する必要があります
UNION を UNION ALL に置き換えます
ページングまたは TOP を使用して大量のデータをクエリする
再帰クエリレベルの制限
NOT INではなくNOT EXISTS
一時テーブルとテーブル変数
ローカル変数を使用して平均実行計画を選択します
OR 演算子
の使用は避けてください。 トランザクション例外処理メカニズムを追加
出力列では 2 つの部分からなる命名形式が使用されます
データベース内で複雑な操作を行うことは禁止されています
XML 解析
文字列の類似性比較
文字列検索 (Charindex)
複雑な操作はプログラム側で完結
SELECT *
の使用は禁止されています メモリ消費量とネットワーク帯域幅を削減します
クエリ オプティマイザーにインデックスから必要な列を読み取る機会を与えます
テーブル構造が変更されると、クエリエラーが発生しやすくなります
インデックス列で関数や計算を使用することは禁止されています
インデックス列で関数や計算を使用することは禁止されています
where 句で、インデックスが関数の一部である場合、オプティマイザーはインデックスを使用せず、テーブル全体のスキャンを使用します
フィールド Col1 にインデックスが構築されていると仮定すると、そのインデックスは次のシナリオでは使用されません:
ABS[Col1]=1
[Col1]+1>9
別の例を挙げてみましょう

上記のようなクエリでは O_OrderProcess テーブルの PrintTime インデックスを使用できないため、以下に示すようにクエリ SQL を使用します
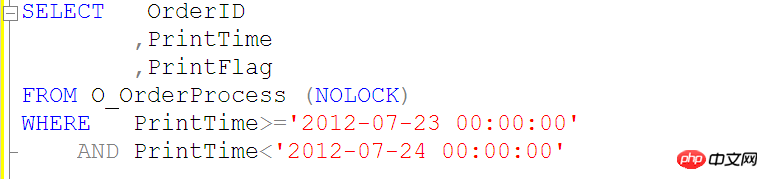
インデックス列で関数や計算を使用することは禁止されています
フィールド Col1 にインデックスが構築されていると仮定すると、そのインデックスは次のシナリオで使用できます。 [Col1]=3.14
[Col1]>100
[Col1] 0 と 99 の間
[Col1] 「abc%」のように
[Col1] IN(2,3,5,7)
LIKEクエリのインデックスの問題
1.[Col1] like “abc%” –index seen これはインデックスクエリを使用します
2.[Col1] like “%abc%” –index scan これはインデックスクエリを使用しません
3.[Col1] like “%abc” –index scan これもインデックスクエリを使用しません
上記の 3 つの例から、LIKE 条件の前であいまい一致を使用しないことが最善であることが誰でも理解できると思います。そうしないと、インデックス クエリが使用されなくなります。
カーソルの使用は禁止です
リレーショナル データベースは、集合操作に適しています。つまり、集合操作は、WHERE 句と選択列によって決定される結果セットに対して実行されます。カーソルは、非集合操作を提供する手段です。通常の状況では、カーソルによって実装される関数は、クライアント側のループによって実装される関数と同等であることがよくあります。
カーソルは結果セットをサーバー メモリに配置し、ループを通じてレコードを 1 つずつ処理します。これにより、大量のデータベース リソース (特にメモリとロック リソース) が消費されます。
(また、カーソルは非常に複雑で使いにくいので、できるだけ使用しないでください)
トリガーの使用は禁止されています
トリガーはアプリケーションに対して不透明です (アプリケーション レベルではトリガーがいつトリガーされるか、またいつ発生するかがわかりません。不可解な感じがします...)
クエリ内でインデックスを指定することは禁止されています
With(index=XXX)(クエリでは、通常、インデックスを指定するために With(index=XXX) を使用します)
-
データが変化すると、クエリ ステートメントで指定されたインデックスのパフォーマンスが最適化されない可能性があります
。
新しく作成されたインデックスはアプリケーションですぐには使用できないため、有効にするには公開する必要があります
変数/パラメータ/関連フィールドのタイプは、フィールドのタイプと一致している必要があります (これは、これまであまり注意を払わなかったことです)
型変換による余分な CPU 消費を回避します。これは、大規模なテーブル スキャンの場合に特に深刻です
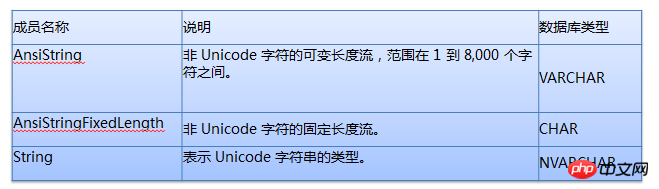
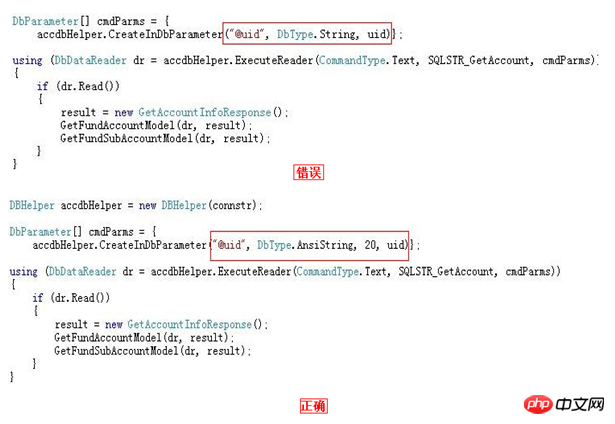
上の 2 つの写真を見れば、説明する必要はないと思います。誰もがすでに知っているはずです。
データベースフィールドの型が VARCHAR の場合は、アプリケーションで型を AnsiString として指定し、その長さを明確に指定するのが最善です
データベースフィールドの型が CHAR の場合、アプリケーションで型を AnsiStringFixedLength として指定し、その長さを明確に指定することが最善です
データベースフィールドの型がNVARCHARの場合は、アプリケーションで型を文字列として指定し、その長さを明確に指定することが最善です
パラメータ化されたクエリ
クエリ SQL は次の方法でパラメータ化できます:
sp_executesql
準備されたクエリ
ストアドプロシージャ
写真で説明しましょう(笑)。


JOIN の数を制限する
単一の SQL ステートメント内のテーブル JOIN の数は 5 を超えることはできません
JOIN が多すぎると、クエリ アナライザーが間違った実行プランに入ります
JOIN が多すぎると、実行計画をコンパイルするときに大量のコストを消費します
IN 句内の条件の数を制限します
IN 句に非常に多くの値 (数千) を含めると、リソースが消費され、エラー 8623 または 8632 が返される可能性があります。 IN 句の条件の数は 100 に制限する必要があります。
大規模なトランザクション操作は避けるようにしてください
データを更新する必要がある場合にのみトランザクションを開始し、リソース ロックの保持時間を短縮します
トランザクション例外キャプチャ前処理メカニズムを追加
データベース上の分散トランザクションの使用は禁止されています
写真を使って説明します
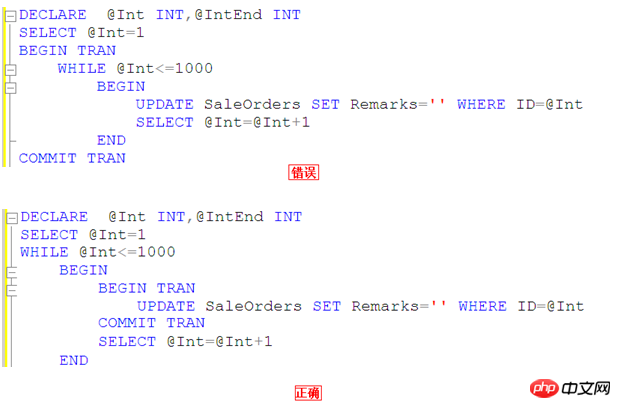
つまり、1,000 行のデータがすべて更新された後に tran をコミットすべきではありません。これらの 1,000 行のデータを更新するときにリソースを独占し、他のトランザクションが処理できなくなる可能性があることを考慮してください。
クローズによって影響を受ける行数情報を返します
SQL ステートメントで Set Nocount On を表示し、影響を受ける行数情報の戻りをキャンセルし、ネットワーク トラフィックを削減します
必要な場合を除き、SELECT ステートメントに NOLOCK を追加する必要があります
必要がない限り、すべての選択ステートメントに NOLOCK を追加してみてください
ダーティ リードが許可されることを指定します。共有ロックは、現在のトランザクションによって読み取られたデータが他のトランザクションによって変更されるのを防ぐために発行されるものではありません。また、他のトランザクションによって設定された排他ロックは、現在のトランザクションによるロックされたデータの読み取りを妨げません。ダーティ リードを許可すると、同時操作が増加する可能性がありますが、その代償として、読み取り後に他のトランザクションによってロールバックされるデータ変更が発生します。これにより、トランザクションがエラーになったり、コミットされていないユーザー データが表示されたり、ユーザーがレコードを 2 回表示したり (またはレコードがまったく表示されなかったり) する可能性があります
UNION を置き換えるには UNION ALL を使用してください
UNION を置き換えるには UNION ALL を使用してください
UNION は SQL 結果セットの順序を変更し、CPU、メモリなどの消費量を増加させます
大量のデータをクエリするには、ページングまたは TOP を使用します
IO とネットワーク帯域幅のボトルネックを回避するために、返されるレコードの数を合理的に制限します
再帰クエリレベルの制限
MAXRECURSION を使用して、不当な再帰 CTE が無限ループに入るのを防ぎます
一時テーブルとテーブル変数
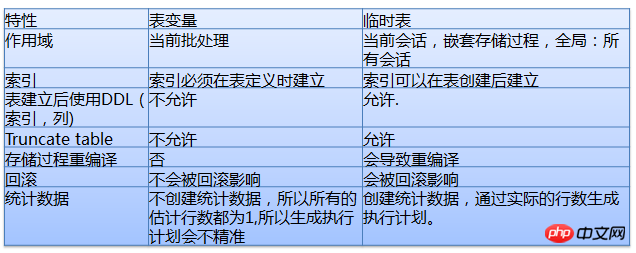
ローカル変数を使用して平均的な実行計画を選択します
ストアド プロシージャまたはクエリで、データが非常に不均等に分散されているテーブルにアクセスすると、ストアド プロシージャまたはクエリで次善の実行プランが使用され、場合によっては不十分な実行プランが使用され、CPU 使用率の上昇や大量の IO 読み取りなどの問題が発生します。間違った実行計画を防ぎます。
ローカル変数を使用する場合、SQL はコンパイル時にこのローカル変数の値を知りません。このとき、SQL はテーブル内のデータの一般的な分布に基づいて戻り値を「推測」します。ストアド プロシージャまたはステートメントを呼び出すときにユーザーがどの変数値を代入しても、生成されるプランは同じです。このような計画は一般的により穏やかであり、必ずしも最良の計画であるとは限りませんが、一般に最悪の計画でもありません
クエリ内のローカル変数が不等式演算子を使用する場合、クエリ アナライザーは単純な 30% 計算を使用して推定します
推定行数 =(合計行数 * 30)/100
クエリ内のローカル変数が等価演算子を使用する場合、クエリ アナライザーは次を使用します: 精度 * 推定するテーブル レコードの総数
推定行数 = 密度 * 合計行数
OR 演算子の使用は避けてください
OR 演算子の場合は、通常、テーブル全体のスキャンが使用されます。複数のクエリに分割し、UNION/UNION ALL を実装することを検討してください。ここでは、クエリがインデックスに移動して、より小さい結果セットを返すことができることを確認する必要があります。 トランザクション例外処理メカニズムを追加します
アプリケーションはアクシデントを適切に処理し、時間内にロールバックを実行する必要があります。
接続プロパティを「set xact_abort on」に設定します
出力列では 2 部構成の命名形式が使用されます
2 段階の命名形式: テーブル名.フィールド名
JOIN 関係のある TSQL では、フィールドがどのテーブルに属しているかを示す必要があります。そうしないと、将来テーブル構造が変更された後、曖昧な列名によるプログラム互換性エラーが発生する可能性があります
。 建築設計
-
読み書きの分離
- 読み書きの分離
-
設計当初から読み書きの分離が考慮されており、同じライブラリを読み書きしても迅速な拡張につながります
- スキーマの分離
クロスデータベース JOIN は禁止されています
データのライフサイクル
データの使用頻度に応じて、大きなテーブルは定期的に別のデータベースにアーカイブされます
メインライブラリ/アーカイブライブラリは物理的に分離されています
ログタイプのテーブルはパーティション化するかテーブルに分割する必要があります
大きなテーブルの場合、パーティション化が必要です。パーティション操作では、テーブルとインデックスを複数のパーティションに分割することで、新しいパーティションと古いパーティションをすばやく置き換えることができ、データのクリーニングが高速化され、IO リソースの消費が大幅に削減されます
。 頻繁に書き込まれるテーブルはパーティション化するかテーブルに分割する必要があります
自己成長とラッチロック
ラッチは SQL Server によって内部的に適用され、制御されます。ユーザーが介入することはできません。ロック レベルはページ レベルのロックです。
以上が一般的に使用される SQL Server 仕様のコレクションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。