
ホームページ >バックエンド開発 >Python チュートリアル >Python GIL のマルチスレッド性能とは GIL について徹底解説
Python GIL のマルチスレッド性能とは GIL について徹底解説

- PHPzオリジナル
- 2017-04-23 17:08:031660ブラウズ
前書き: ブロガーは、Python に初めて触れたときに GIL という言葉をよく聞きましたが、この言葉は Python がマルチスレッドを効率的に実装できないことと同一視されることが多いことに気付きました。何が起こっているのかを知るだけでなく、なぜそれが起こっているのかを知るという研究姿勢に沿って、ブロガーはあらゆる情報を収集し、1週間以内に数時間の自由時間を費やしてGILを深く理解し、それをこのようにまとめましたまた、読者がこの記事を通じて GIL をより深く客観的に理解できることを願っています。
GIL とは
まず明確にする必要があるのは、
GILは Python の機能ではないということです。これは、Python パーサーを実装するときに導入されます。 (CPython) の概念。 C++ が一連の言語 (文法) 標準であるのと同様に、さまざまなコンパイラを使用して実行可能コードにコンパイルできます。 GCC、INTEL C++、Visual C++などの有名なコンパイラ。 Python にも同じことが当てはまります。CPython、PyPy、Psyco などの異なる Python 実行環境を通じて、同じコードを実行できます。たとえば、JPython には GIL がありません。ただし、ほとんどの環境では CPython がデフォルトの Python 実行環境です。したがって、多くの人々の概念では、CPython は Python であり、GILが Python 言語の欠陥に起因すると考えられています。ここで明確にしておきます: GIL は Python の機能ではありません。Python は GIL にまったく依存する必要はありませんGIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL那么CPython实现中的GIL又是什么呢?GIL全称
では、CPython 実装における GIL とは何でしょうか? GIL の正式名はGlobal Interpreter Lockグローバル インタプリタ ロックです。誤解を招くのを避けるために、公式の説明を見てみましょう:CPython では、グローバル インタプリタ ロック、またはGIL は、複数のネイティブ スレッドが Python バイトコードを同時に実行することを防ぐミューテックスです。このロックが必要なのは、主に CPython のメモリ管理がスレッドセーフではないためです (ただし、GIL が存在するため、他の機能はその保証に依存するようになりました)。 )わかりました、悪くありませんか?複数のスレッドがマシン コードを同時に実行できないようにする Mutex は、一見するとバグのように見えるグローバル ロックのように見えます。心配しないでください。以下でゆっくり分析していきます。 なぜ GIL があるのか物理的な制限により、コア周波数における CPU メーカー間の競争はマルチコアに取って代わられました。マルチコアプロセッサの性能をより効果的に活用するために、マルチスレッドプログラミング方式が登場しましたが、それに伴い、データの一貫性とスレッド間の状態同期が困難になります。 CPU 内の キャッシュ も例外ではなく、複数の キャッシュ
間のデータ同期を効果的に解決するために、さまざまなメーカーが多大な労力を費やしており、必然的に一定のパフォーマンスの低下が生じます。もちろん、Python はマルチコアを活用するために、マルチスレッドをサポートし始めました。 複数のスレッド間のデータの整合性とステータスの同期を解決する最も簡単な方法は、当然ロックすることです。 そのため、GIL の非常に大きなロックがあり、ますます多くのコードベース開発者がこの設定を受け入れると、この機能に大きく依存し始めます (つまり、デフォルトの Python 内部オブジェクト
はスレッドセーフであり、その必要はありません)実装中に追加のメモリ ロックと同期操作を考慮してください)。 のような「小さなプロジェクト」は、Buffer Pool Mutex の大きなロックをさまざまな小さなロックに分割するために、5.5 から 5.6 、そして 5.7 までの複数のメジャー バージョンで 5 年近くを費やし、それが今も続いています。 MySQL は企業のサポートとその背後に固定の開発チームがいる製品ですが、コア開発者と Python のようなコード貢献者からなる高度にコミュニティベースのチームは言うまでもなく、これほど困難な状況に陥っているのでしょうか? つまり、簡単に言えば、GIL の存在は歴史的な理由によるものです。これを最初からやり直す必要がある場合でも、マルチスレッドの問題に直面することになりますが、少なくとも現在の GIL アプローチよりは洗練されるでしょう。 GIL の影響 上記の紹介と公式の定義から、GIL は間違いなくグローバル排他ロックです。グローバル ロックの存在がマルチスレッドの効率に大きな影響を与えることは疑いの余地がありません。あたかも Python がシングルスレッド プログラムであるかのようです。 そうなると読者は、グローバルロックが解除されていれば効率は悪くないと言うでしょう。時間のかかる IO 操作を実行するときに GIL を解放できる限り、操作効率を向上させることができます。つまり、どんなに悪くてもシングルスレッドの効率より悪くなることはありません。これは理論的には正しいですが、実際にはどうなのでしょうか? Python はあなたが思っているよりも悪いです。 🎜マルチスレッドとシングルスレッドでの Python の効率を比較してみましょう。テスト方法は非常に簡単で、1億回ループするカウンター関数です。 1 つは単一のスレッドで 2 回実行され、もう 1 つは複数のスレッドで実行されます。最後に合計実行時間を比較します。テスト環境はデュアルコアMac proです。注: スレッド ライブラリ自体のパフォーマンス損失がテスト結果に及ぼす影響を軽減するために、ここでのシングルスレッド コードではスレッドも使用されます。単一のスレッドをシミュレートするには、これを 2 回連続して実行するだけです。
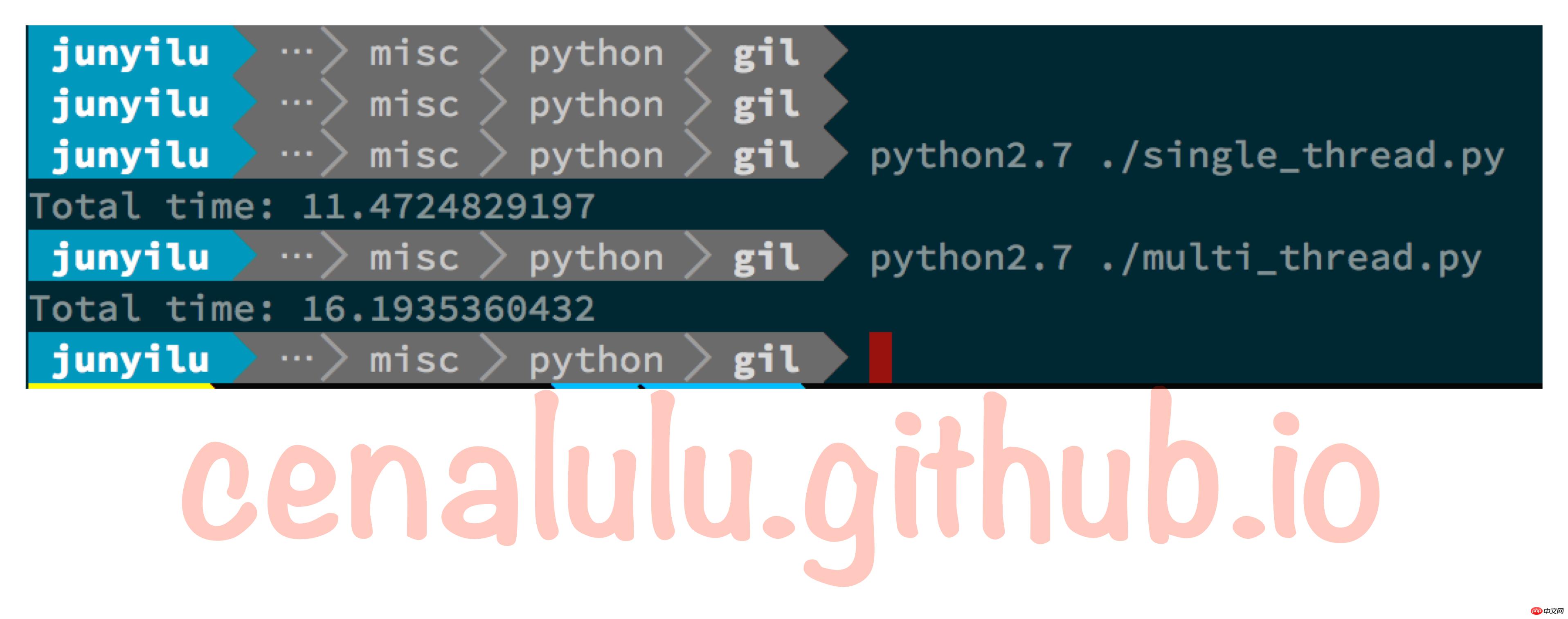
単一スレッド (single_thread.py) を順次実行
#! /usr/bin/pythonfrom threading import Threadimport timedef my_counter(): i = 0 for _ in range(100000000): i = i + 1 return Truedef main(): thread_array = {} start_time = time.time() for tid in range(2): t = Thread(target=my_counter) t.start() t.join() end_time = time.time() print("Total time: {}".format(end_time - start_time))if name == 'main': main()2 つの同時スレッド (multi_thread.py) を同時に実行
#! /usr/bin/pythonfrom threading import Threadimport timedef my_counter(): i = 0 for _ in range(100000000): i = i + 1 return Truedef main(): thread_array = {} start_time = time.time() for tid in range(2): t = Thread(target=my_counter) t.start() thread_array[tid] = t for i in range(2): thread_array[i].join() end_time = time.time() print("Total time: {}".format(end_time - start_time))if name == 'main': main()下の写真はテスト結果です
Python がマルチスレッドであることがわかりますこの場合、実際にはシングルスレッドよりも 45% 遅くなります。前の分析によると、GIL グローバル ロックが存在する場合でも、シリアル化されたマルチスレッドはシングル スレッドと同じ効率を持つはずです。では、どうしてこのような悪い結果が生じるのでしょうか?
GIL の実装原理を通してその理由を分析してみましょう。
現在の GIL 設計の欠陥
pcode の数に基づくスケジューリング方法
Python コミュニティの考えによれば、オペレーティング システム自体のスレッド スケジューリングはすでに非常に成熟していて安定しており、自分で作成する必要があります。したがって、Python スレッドは
C 言語の pthread であり、オペレーティング システムのスケジューリング アルゴリズム (たとえば、linux は CFS) を通じてスケジュールされます。各スレッドが CPU 時間を均等に利用できるようにするために、Python は現在実行されているマイクロコードの数を計算し、特定のしきい値に達すると GIL を強制的に解放します。このとき、オペレーティング システムのスレッド スケジューリングもトリガーされます (もちろん、コンテキスト スイッチが実際に実行されるかどうかはオペレーティング システムによって決定されます)。 疑似コード
while True: acquire GIL for i in 1000: do something release GIL /* Give Operating System a chance to do thread scheduling */このモードは、CPU コアが 1 つしかない場合、問題なく動作します。どのスレッドも、起動されると GIL を正常に取得できます (スレッドのスケジューリングは GIL が解放されたときにのみ行われるため)。しかし、CPU に複数のコアがある場合、問題が発生します。疑似コードからわかるように、
の間にはほとんど隙間がありません。したがって、他のコア上の他のスレッドが起動されると、ほとんどの場合、メインスレッドが GIL を再度取得します。現時点では、実行のために目覚めたスレッドは、別のスレッドが GIL で問題なく実行されるのを監視して、無駄に CPU 時間を浪費することしかできません。そして切り替え時刻に達すると待機状態に入り、再び覚醒し、また待機するという悪循環を繰り返します。
release GIL到acquire GIL追記: もちろん、この実装は原始的で醜いものですが、GIL とスレッド スケジューリングの間の相互作用は、Python の各バージョンで徐々に改善されています。たとえば、まずスレッド コンテキストの切り替えを実行している間は GIL を保持し、IO を待機している間は GIL を解放してみます。しかし、変えられないのは、GIL の存在によって、オペレーティング システムのスレッド スケジューリングという、すでに高価な操作がさらに贅沢なものになるということです。 GIL の影響に関する詳細な説明マルチスレッドに対する GIL のパフォーマンスへの影響を直感的に理解するために、直接借用したテスト結果のグラフを次に示します (下図を参照)。この図は、デュアルコア CPU での 2 つのスレッドの実行を示しています。どちらのスレッドも、CPU 集中型のコンピューティング スレッドです。緑色の部分は、スレッドが実行中で有用な計算を実行していることを示します。赤色の部分は、スレッドが起動するようにスケジュールされているが、GIL を取得できないため、効果的な計算の待ち時間が発生していることを示します。
図からわかるように、GIL の存在により、マルチスレッドはマルチコア CPU の同時処理
GILの影響を受けないようにする方法
ここまで言って、解決策について言及しないと、単なる人気の科学投稿ですが、役に立ちません。 GIL は非常に悪いのですが、回避方法はありますか?どのような解決策があるかを見てみましょう。
スレッドをマルチプロセッシングに置き換える
マルチプロセッシング ライブラリの登場は主に、GIL によるスレッド ライブラリの非効率性を補うことです。移行を容易にするために、スレッドによって提供される一連のインターフェースを完全に複製します。唯一の違いは、複数のスレッドではなく複数のプロセスを使用することです。各プロセスには独自の独立した GIL があるため、プロセス間で GIL の競合は発生しません。
もちろん、マルチプロセッシングは万能薬ではありません。これを導入すると、プログラム内のタイム スレッド間のデータ通信と同期が難しくなります。例としてカウンタを取り上げます。複数のスレッドで同じ 変数 を蓄積したい場合は、スレッドに対してグローバル変数を宣言し、thread.Lock コンテキストを 3 行で囲みます。マルチプロセッシングでは、プロセスは互いのデータを参照できないため、メインスレッドでキューを宣言し、キューを配置してから取得するか、共有メモリを使用することしかできません。この追加の実装コストにより、すでに非常に困難なマルチスレッド プログラムのコーディングがさらに困難になります。具体的な問題点は何ですか? 興味のある方はこの記事をさらに読んでください
他のパーサーを使用してください
前に述べたように、GIL は CPython の製品にすぎないため、他のパーサーの方が優れていますか?はい、JPython や IronPython などのパーサーは、実装言語の性質上、GIL の助けを必要としません。ただし、パーサーの実装に Java/C# を使用することで、コミュニティの C 言語モジュールの多くの便利な機能を活用する機会も失いました。したがって、これらのパーサーは常に比較的ニッチなものでした。結局、初期段階では誰もが機能や性能よりも前者を選ぶでしょう
Done is better than perfect。それでは絶望的ですか?
もちろん、Python コミュニティも GIL を継続的に改善するために非常に熱心に取り組んでおり、さらには GIL を削除しようとしています。そして、各マイナーバージョンでは多くの改善が行われています。興味のある方は、このスライドをさらに読んでください。 別の改善 GIL の再加工 - スイッチング粒度をオペコードカウントからタイムスライスカウントに変更 - 最近 GIL ロックを解放したスレッドがすぐに再度スケジュールされるのを回避 - 新しい スレッド 優先度 機能 (高) -優先スレッドは、他のスレッドが保持している GIL ロックを強制的に解放することができます)
概要
Python GIL は、実際には機能とパフォーマンスの間のトレードオフの産物であり、存在するのは特に合理的ですが、客観的な要因による困難もあります。変化。この部分の分析から、次のような簡単な結論を下すことができます。 - GIL の存在により、IO バウンド シナリオでは複数のスレッドのみがパフォーマンスを向上させます。 - 高い並列コンピューティング パフォーマンスを備えたプログラムを作成したい場合は、次のことを考慮できます。コアを使用する それらのいくつかは C モジュールに変換されたり、他の言語で単純に実装されたりすることもあります - GIL は長期間存在し続けますが、改善され続けます
参考
Python の最も難しい問題についての公式ドキュメントGIL スレッドの優先順位と新しい GIL の再検討
 Python がマルチスレッドであることがわかりますこの場合、実際にはシングルスレッドよりも 45% 遅くなります。前の分析によると、GIL グローバル ロックが存在する場合でも、シリアル化されたマルチスレッドはシングル スレッドと同じ効率を持つはずです。では、どうしてこのような悪い結果が生じるのでしょうか?
Python がマルチスレッドであることがわかりますこの場合、実際にはシングルスレッドよりも 45% 遅くなります。前の分析によると、GIL グローバル ロックが存在する場合でも、シリアル化されたマルチスレッドはシングル スレッドと同じ効率を持つはずです。では、どうしてこのような悪い結果が生じるのでしょうか?  機能を十分に活用できなくなります。
機能を十分に活用できなくなります。  簡単にまとめると、次のとおりです。マルチコア CPU での Python のマルチスレッドは、IO 集中型の計算にのみプラスの影響を及ぼし、CPU 集中型のスレッドが少なくとも 1 つある場合、次のような理由でマルチスレッド効率が大幅に低下します。ギル。
簡単にまとめると、次のとおりです。マルチコア CPU での Python のマルチスレッドは、IO 集中型の計算にのみプラスの影響を及ぼし、CPU 集中型のスレッドが少なくとも 1 つある場合、次のような理由でマルチスレッド効率が大幅に低下します。ギル。 以上がPython GIL のマルチスレッド性能とは GIL について徹底解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。