
ホームページ >データベース >mysql チュートリアル >RedisとMemcachedの違いを詳しく解説
RedisとMemcachedの違いを詳しく解説
- 巴扎黑オリジナル
- 2017-04-08 10:37:041283ブラウズ
Redis の作者である Salvatore Sanfilippo は、かつて次の 2 つのメモリベースのデータ ストレージ システムを比較しました:
Redis はサーバー側のデータ操作をサポートします。Memcached と比較して、Redis はより多くのデータ構造を持ち、より豊富なデータ操作をサポートします。通常、Memcached では、データをクライアントに取得して同様の変更を行ってから、それを元に戻す必要があります。これにより、ネットワーク IO の数とデータ量が大幅に増加します。 Redis では、これらの複雑な操作は通常、通常の GET/SET と同じくらい効率的です。したがって、より複雑な構造と操作をサポートするキャッシュが必要な場合は、Redis が適切な選択肢になります。
メモリ使用効率の比較: 単純なキーと値のストレージが使用される場合、Memcached のメモリ使用率が高くなります。Redis がキーと値のストレージにハッシュ構造を使用する場合、圧縮が組み合わされているため、メモリ使用率は Memcached よりも高くなります。
パフォーマンスの比較: Redis は単一コアのみを使用し、Memcached は複数のコアを使用できるため、各コアに少量のデータを保存する場合、平均して Redis の方が Memcached よりも高いパフォーマンスを発揮します。 100k を超えるデータの場合、Memcached のパフォーマンスは Redis のパフォーマンスよりも高くなります。Redis は最近ビッグ データの保存パフォーマンスに最適化されていますが、それでも Memcached よりわずかに劣ります。
上記の結論がなぜ得られるのか具体的に説明すると、収集された情報は次のとおりです:
1. さまざまなデータ型がサポートされています
単純なキーと値の構造を持つデータ レコードのみをサポートする Memcached とは異なり、Redis はより豊富なデータ型をサポートします。最も一般的に使用されるデータ型は、文字列、ハッシュ、リスト、セット、ソート セットの 5 つです。 Redis は、内部で redisObject オブジェクトを使用して、すべてのキーと値を表します。 redisObject の主な情報は図の通りです:

type は値オブジェクトの特定のデータ型を表し、エンコーディングはさまざまなデータ型を redis 内に格納する方法です。たとえば、 type=string は値が通常の文字列として格納されることを表し、対応するエンコーディングは raw または int になります。 int の場合、実際の文字列が数値クラスとして redis の内部に保存され、表現されることを意味します。もちろん、文字列自体が「123」「456」などの数値で表現できることが前提となります。そのような文字列。 Redis の仮想メモリ機能がオンになっている場合にのみ、vm フィールドが実際にメモリを割り当てます。この機能はデフォルトではオフになっています。
1) 文字列
よく使用されるコマンド: set/get/decr/incr/mget など。 アプリケーション シナリオ: 文字列は最も一般的に使用されるデータ型であり、通常のキー/値ストレージはこのカテゴリに分類できます
。 実装方法:文字列はデフォルトで文字列としてredisに格納されており、redisObjectから参照されるが、その際に数値に変換されて計算される。 intです。
2) ハッシュ
よく使用されるコマンド: hget/hset/hgetall など
アプリケーション シナリオ: ユーザー ID、ユーザー名、年齢、誕生日を含むユーザー情報オブジェクト データを保存したいと考えています。ユーザー ID を通じて、ユーザーの名前、年齢、誕生日を取得したいと考えています。 実装方法: Redis のハッシュは実際には値を HashMap として内部に保存し、この Map のメンバーに直接アクセスするためのインターフェイスを提供します。図に示すように、Key はユーザー ID で、Value は Map です。このMapのキーはメンバーの属性名、値は属性値です。このようにして、内部マップのキー (Redis では内部マップのキーはフィールドと呼ばれます) を介してデータを直接変更およびアクセスできます。つまり、対応する属性データはキー (ユーザー ID) + フィールドを通じて操作できます。 (属性ラベル)。現在 HashMap を実装するには 2 つの方法があります。 HashMap のメンバーが比較的少ない場合、Redis はメモリを節約するために、現時点では実際の HashMap 構造を使用するのではなく、1 次元配列のようなメソッドを使用して HashMap をコンパクトに保存します。 、対応する値のredisObjectのエンコードはzipmap、メンバー数が増えると自動的に実際のHashMapに変換され、エンコードはhtとなります。
- 3) リスト
- よく使用されるコマンド: lpush/rpush/lpop/rpop/lrange など。 アプリケーション シナリオ: Redis リストには多くのアプリケーション シナリオがあり、Redis の最も重要なデータ構造の 1 つでもあります。たとえば、twitter のフォロー リスト、ファン リストなどは、Redis のリスト構造を使用して実装できます。
- 実装方法: Redis リストは双方向リンク リストとして実装されており、逆方向検索とトラバーサルをサポートできるため、操作がより便利になります。ただし、送信バッファ キューなど、Redis 内の多くの実装では追加のメモリ オーバーヘッドが発生します。 .、このデータ構造も使用されます。
よく使用されるコマンド:sadd/spop/smembers/sunion など。 アプリケーション シナリオ: Redis set によって提供される外部関数は list の関数と似ています。特別な機能は、データのリストを保存する必要があり、重複したデータが表示されたくない場合に set が非常に便利であることです。便利なツールです。set は、リストでは提供できない、メンバーがセット コレクションに含まれているかどうかを判断するための重要なインターフェイスを提供します。 実装方法: set の内部実装は、値が常に null である HashMap です。実際、set はメンバーがセットに含まれているかどうかを判断する方法を提供できるのはこのためです。
5) ソートセット
よく使用されるコマンド: zadd/zrange/zrem/zcard など。 アプリケーション シナリオ: Redis ソート セットの使用シナリオはセットの使用シナリオと似ていますが、セットは自動的に順序付けされないのに対し、ソート セットはユーザーが追加の優先度 (スコア) パラメーターを指定することでメンバーを並べ替えることができ、つまり、自動ソートです。順序付けされた重複しないセット リストが必要な場合は、ソートされたセット データ構造を選択できます。たとえば、Twitter の公開タイムラインをスコアとして公開時間を保存し、取得時に自動的に時間順に並べ替えることができます。
実装方法: Redis ソート セットは内部で HashMap とスキップ リスト (SkipList) を使用して、データの保存と順序付けを保証します。HashMap はメンバーからスコアへのマッピングを保存しますが、スキップ リストは HashMap に保存されているすべてのメンバーを保存します。 、ジャンプ テーブル構造を使用すると、より高い検索効率を実現でき、実装も比較的簡単です。
2. さまざまなメモリ管理メカニズム
Redis では、すべてのデータが常にメモリに保存されるわけではありません。これが Memcached との最大の違いです。物理メモリが不足すると、Redis は長期間使用されなかった一部の値をディスクにスワップできます。 Redis は、すべてのキー情報のみをキャッシュします。メモリ使用量が特定のしきい値を超えていることが判明した場合、Redis は、「swappability = age*log(size_in_memory)」に基づいて、どのキーがディスクにスワップされるかを計算します。 。その後、これらのキーに対応する値がディスクに保存され、メモリ内でクリアされます。この機能により、Redis はマシン自体のメモリ サイズを超えるデータを維持できるようになります。もちろん、マシン自体のメモリにはすべてのキーを保持できる必要があります。結局のところ、これらのデータは交換されません。同時に、Redis がメモリ内のデータをディスクにスワップすると、サービスを提供するメインスレッドとスワップ操作を実行するサブスレッドがメモリのこの部分を共有するため、必要なデータがswapped が更新されると、Redis はサブスレッドが完了するまで操作をブロックします。変更はスワップ操作の完了後にのみ行うことができます。 Redis からデータを読み取るときに、読み取ったキーに対応する値がメモリにない場合、Redis は対応するデータをスワップ ファイルからロードして、リクエスターに返す必要があります。 ここには I/O スレッド プールの問題があります。デフォルトでは、Redis はブロックします。つまり、すべてのスワップ ファイルがロードされるまで応答しません。この戦略は、クライアントの数が少なく、バッチ操作が実行される場合に適しています。しかし、Redis が大規模な Web サイト アプリケーションに適用される場合、これは明らかに大規模な同時実行の状況に対応できません。したがって、Redis を実行するときは、I/O スレッド プールのサイズを設定し、スワップ ファイルから対応するデータをロードする必要がある読み取りリクエストに対して同時操作を実行して、ブロック時間を短縮します。
Redis や Memcached などのメモリベースのデータベース システムの場合、メモリ管理の効率はシステムのパフォーマンスに影響を与える重要な要素です。従来の C 言語の malloc/free 関数は、メモリの割り当てと解放に最も一般的に使用される方法ですが、この方法には大きな欠陥があります。まず、開発者にとって、malloc と free の不一致によりメモリ リークが発生しやすくなります。2 番目に、頻繁な呼び出しによってメモリ リークが発生します。リサイクルおよび再利用できない大量のメモリ フラグメントにより、メモリ使用率が削減されます。最後に、システム コールとしてのシステム オーバーヘッドは、通常の関数呼び出しよりもはるかに大きくなります。したがって、メモリ管理の効率を向上させるために、効率的なメモリ管理ソリューションでは malloc/free 呼び出しを直接使用しません。 Redis と Memcached はどちらも独自のメモリ管理メカニズムを使用しますが、その実装方法は大きく異なります。以下では 2 つのメモリ管理メカニズムを個別に紹介します。 -
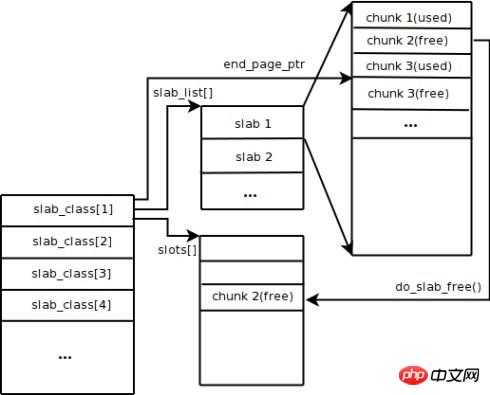
Memcached はデフォルトでスラブ割り当てメカニズムを使用してメモリを管理し、割り当てられたメモリを所定のサイズに従って特定の長さのブロックに分割し、対応する長さのキーと値のデータ レコードを格納して、メモリの断片化の問題を完全に解決します。スラブ割り当てメカニズムは、外部データを保存することのみを目的として設計されています。つまり、すべてのキーと値のデータはスラブ割り当てシステムに保存されますが、Memcached に対する他のメモリ要求は通常の malloc/free を通じて適用されます。スラブ割り当ての原理は非常に単純です。 図に示すように、まずオペレーティング システムから大きなメモリ ブロックを適用し、それをさまざまなサイズのチャンクに分割し、同じサイズのチャンクをスラブ クラスのグループに分割します。このうち、チャンクはキーと値のデータを格納するために使用される最小単位です。各スラブ クラスのサイズは、Memcached の起動時に Growth Factor を指定することで制御できます。図の Growth Factor の値が 1.25 であると仮定します。チャンクの最初のグループのサイズが 88 バイトの場合、チャンクの 2 番目のグループのサイズは 112 バイトというようになります。

Memcached がクライアントから送信されたデータを受信すると、まず受信したデータのサイズに基づいて最適なスラブ クラスを選択し、次に Memcached によって保存されたスラブ クラス内の空きチャンクのリストをクエリして、使用可能なスラブ クラスを見つけます。データを保存するために使用されます。データベース レコードが期限切れになるか破棄されると、そのレコードが占めていたチャンクをリサイクルして空きリストに再度追加できます。上記のプロセスから、Memcached のメモリ管理システムは非常に効率的でメモリの断片化を引き起こさないことがわかりますが、その最大の欠点はスペースの無駄につながることです。各チャンクには特定の長さのメモリ空間が割り当てられるため、可変長データはこの空間を完全に利用できません。図に示すように、100 バイトのデータが 128 バイトのチャンクにキャッシュされ、残りの 28 バイトは無駄になります。
Redis のメモリ管理は、主にソース コード内の 2 つのファイル RedisとMemcachedの違いを詳しく解説.h および RedisとMemcachedの違いを詳しく解説.c によって実装されます。メモリ管理を容易にするために、Redis はメモリを割り当てた後、このメモリのサイズをメモリ ブロックの先頭に保存します。図に示すように、real_ptr は、malloc を呼び出した後に redis によって返されるポインターです。 Redis はヘッダーにメモリ ブロック サイズのサイズを格納し、size_t 型の長さで占有されるメモリ サイズを返します。メモリを解放する必要がある場合、ret_ptr がメモリ マネージャーに渡されます。 ret_ptr を通じて、プログラムは real_ptr の値を簡単に計算し、real_ptr を free に渡してメモリを解放できます。
Redis は配列を定義することによってすべてのメモリ割り当てを記録します。この配列の長さは ZMALLOC_MAX_ALLOC_STAT です。配列の各要素は、現在のプログラムによって割り当てられたメモリ ブロックの数を表し、メモリ ブロックのサイズは要素の添字です。ソース コードでは、この配列は RedisとMemcachedの違いを詳しく解説_allocations です。 RedisとMemcachedの違いを詳しく解説_allocations[16] は、長さが 16 バイトの割り当てられたメモリ ブロックの数を表します。 RedisとMemcachedの違いを詳しく解説.c には、現在割り当てられているメモリの合計サイズを記録する静的変数 used_memory があります。したがって、一般に、Redis はパッケージ化された mallc/free を使用します。これは、Memcached のメモリ管理方法よりもはるかに単純です。
3. データ永続化のサポート
Redis はメモリベースのストレージ システムですが、それ自体がメモリ データの永続化をサポートし、RDB スナップショットと AOF ログという 2 つの主要な永続化戦略を提供します。 Memcached はデータ永続化操作をサポートしていません。
1) RDBスナップショット
Redis は、現在のデータのスナップショット、つまり RDB スナップショットをデータ ファイルに保存する永続化メカニズムをサポートしています。しかし、継続的に書き込みを行うデータベースはどのようにしてスナップショットを生成するのでしょうか? Redis は、fork コマンドのコピー オン ライト メカニズムを使用します。スナップショットを生成すると、現在のプロセスが子プロセスにフォークされ、すべてのデータが子プロセス内を循環して RDB ファイルに書き込まれます。 Redis の save コマンドを使用して RDB スナップショット生成のタイミングを構成できます。たとえば、スナップショットが 10 分で生成されるように構成したり、1,000 回の書き込み後にスナップショットを生成するように構成したり、複数のルールをまとめて実装したりできます。これらのルールの定義は Redis 構成ファイルにあります。Redis を再起動せずに、Redis CONFIG SET コマンドを使用して Redis の実行中にルールを設定することもできます。
新しい RDB ファイルが生成されると、Redis によって生成されたサブプロセスは最初にデータを一時ファイルに書き込み、次にそれをアトミックに使用するため、Redis の RDB ファイルは損傷しません。システム コールは一時ファイルの名前を RDB ファイルに変更するため、いつ障害が発生しても Redis RDB ファイルを常に使用できるようになります。同時に、Redis の RDB ファイルは、Redis のマスター/スレーブ同期の内部実装の一部でもあります。 RDB には欠点があります。つまり、データベースに問題が発生すると、RDB ファイルに保存されたデータは最新のものではなくなり、最後の RDB ファイルの生成から Redis のシャットダウンまでのデータがすべて失われます。一部のビジネスでは、これは許容できるものです。
2) AOFログ
AOF ログの完全な名前は追加専用ファイルであり、追加で書き込まれたログ ファイルです。一般的なデータベースのbinlogとは異なり、AOFファイルは識別可能なプレーンテキストであり、その内容はRedis標準のコマンドを一つ一つ記述したものです。データの変更を引き起こすコマンドのみが AOF ファイルに追加されます。データを変更する各コマンドによってログが生成され、AOF ファイルがどんどん大きくなるため、Redis には AOF リライトと呼ばれる別の機能が用意されています。その機能は、AOF ファイルを再生成することです。同じ値に対して複数の操作が記録される可能性がある古いファイルとは異なり、新しい AOF ファイルのレコードに対する操作は 1 つだけです。生成プロセスは RDB と似ており、プロセスをフォークし、データを直接走査し、新しい AOF 一時ファイルを書き込みます。新しいファイルの書き込みプロセス中、すべての書き込み操作ログは引き続き元の古い AOF ファイルに書き込まれ、メモリ バッファーにも記録されます。冗長化操作が完了すると、バッファ内のすべてのログが一時ファイルに一度に書き込まれます。次に、atomic rename コマンドを呼び出して、古い AOF ファイルを新しい AOF ファイルに置き換えます。
AOF はファイル書き込み操作であり、その目的は操作ログをディスクに書き込むことであるため、前述の書き込み操作プロセスも実行されます。 Redis で AOF の write を呼び出した後、appendfsync オプションを使用して、fsync を呼び出してディスクに書き込む時間を制御します。以下の appendfsync の 3 つの設定のセキュリティ強度が徐々に強化されます。
appendfsync no appendfsync が no に設定されている場合、Redis は AOF ログの内容をディスクに同期するために fsync を積極的に呼び出しません。そのため、これはすべてオペレーティング システムのデバッグに完全に依存します。ほとんどの Linux オペレーティング システムでは、fsync が 30 秒ごとに実行され、バッファ内のデータがディスクに書き込まれます。
appendfsync Everysec appendfsync が Everysec に設定されている場合、Redis はデフォルトで fsync 呼び出しを毎秒実行して、バッファー内のデータをディスクに書き込みます。ただし、この fsync 呼び出しが 1 秒以上続く場合。 Redis は fsync を遅らせる戦略を採用し、さらに 1 秒待ちます。つまり、fsync は実行にどれだけ時間がかかっても 2 秒後に実行されます。このとき、fsync 中にファイル記述子がブロックされるため、現在の書き込み操作はブロックされます。したがって、結論としては、ほとんどの場合、Redis は毎秒 fsync を実行します。最悪の場合、fsync 操作は 2 秒ごとに発生します。この操作は、ほとんどのデータベース システムではグループ コミットと呼ばれ、複数の書き込み操作のデータを結合し、ログを一度にディスクに書き込みます。
appednfsync always appendfsync が always に設定されている場合、fsync は書き込み操作ごとに 1 回呼び出されます。もちろん、fsync は毎回実行されるため、そのパフォーマンスにも影響します。
一般的なビジネス ニーズでは、永続化のために RDB を使用することをお勧めします。その理由は、データ損失を許容できないアプリケーションでは、RDB のオーバーヘッドが AOF ログの使用よりもはるかに低いためです。
4. クラスター管理の違い
Memcached はフルメモリのデータ バッファリング システムです。Redis はデータの永続化をサポートしていますが、フルメモリこそがその高パフォーマンスの本質です。メモリベースのストレージ システムとして、マシンの物理メモリのサイズが、システムが収容できるデータの最大量となります。処理する必要があるデータの量が単一マシンの物理メモリ サイズを超える場合は、分散クラスタを構築してストレージ機能を拡張する必要があります。
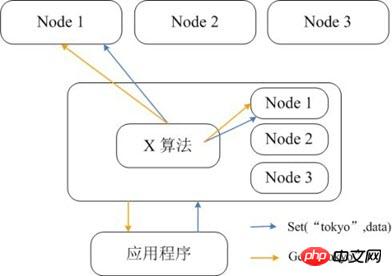
Memcached 自体は分散をサポートしていないため、Memcached の分散ストレージは、コンシステント ハッシュなどの分散アルゴリズムを通じてのみクライアントに実装できます。以下の図は、Memcached の分散ストレージ実装アーキテクチャを示しています。クライアントが Memcached クラスターにデータを送信する前に、まずデータのターゲット ノードが組み込みの分散アルゴリズムによって計算され、次にデータは保存のためにノードに直接送信されます。ただし、クライアントがデータをクエリする場合は、クエリ データが配置されているノードも計算し、データを取得するためにクエリ リクエストをノードに直接送信する必要があります。
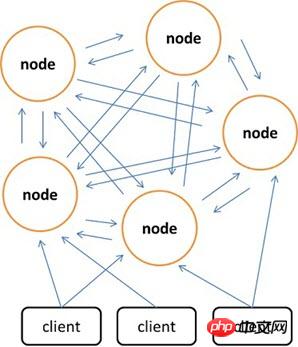
クライアントを使用して分散ストレージを実装することしかできない Memcached と比較して、Redis はサーバー側に分散ストレージを構築することを好みます。最新バージョンの Redis はすでに分散ストレージ機能をサポートしています。 Redis Cluster は、分散を実装し、単一障害点を可能にする Redis の高度なバージョンであり、中央ノードがなく、線形のスケーラビリティを備えています。以下の図は、Redis Cluster の分散ストレージ アーキテクチャを示しています。ノード間はバイナリ プロトコルを通じて通信し、ノードとクライアント間は ASCII プロトコルを通じて通信します。データ配置戦略の観点から、Redis Cluster はキー値フィールド全体を 4096 個のハッシュ スロットに分割し、各ノードは 1 つ以上のハッシュ スロットを保存できます。つまり、Redis Cluster で現在サポートされているノードの最大数は 4096 です。 Redis Cluster で使用される分散アルゴリズムも非常に単純です: crc16(key) % HASH_SLOTS_NUMBER。
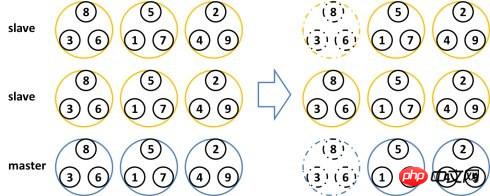
単一障害点下でデータの可用性を確保するために、Redis Cluster にはマスター ノードとスレーブ ノードが導入されています。 Redis クラスターでは、冗長性を確保するために、各マスター ノードに 2 つの対応するスレーブ ノードがあります。このようにして、クラスター全体で、2 つのノードのダウンタイムによってデータが利用できなくなることはありません。マスター ノードが終了すると、クラスターは新しいマスター ノードとなるスレーブ ノードを自動的に選択します。


以上がRedisとMemcachedの違いを詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。