
ホームページ >バックエンド開発 >XML/RSS チュートリアル >Android での XML 解析
Android での XML 解析

- PHPzオリジナル
- 2017-04-04 10:55:521777ブラウズ
1. はじめに
先週、プロジェクトの一般的な内容を理解する必要がありましたが、xml解析について混乱していたので、ここでxml解析について学んだ知識の一部を記録します。
2. 分析Http
: //www.php.cn/wiki/1502.html "target =" _ Blank "> Androidの XML パーサーには、主に DOM パーサー、SAX 解析パーサー、プルパーサー Model) は、XML ドキュメントの各部分に直接アクセスするために使用できます。コンテンツを一度にメモリにロードし、ツリー構造を生成します。これにはコールバックや複雑な state 管理が必要ないため、大きなドキュメントを解析する場合によく使用されます。構文解析は推奨されません。 この構造を分析するには、通常、ノード情報の取得と 更新の前に、ドキュメント全体をロードしてツリー構造を構築する必要があります。変更、追加、削除 DOM の仕組み: DOM を使用して XML ファイルを操作する場合、まずファイルを解析し、ファイルを独立した要素 (
属性や コメント など) に分割してから、ノード ツリーの形式でメモリ内の XML ファイルにアクセスし、必要に応じてドキュメントを変更できます。 一般的に使用される DOM インターフェイス とクラス:
Document: このインターフェイスは以下を定義します。 DOM ドキュメントを分析および作成するための一連のメソッド。これは Document ツリー のルートであり、DOM を操作するための基盤です。 Node: このインターフェイスは、
要素の値を処理および取得するためのメソッドを提供します。 : このインターフェース は Node インターフェースを継承し、XML 要素の名前と属性を取得および変更するメソッドを提供します
Node
: 各ノードがDOMParser: このクラスは、XML ファイルを直接解析できる Apache の DOM パーサー クラスです。
イベントによって駆動されるXML APIですが、欠点は、
コールバック関数
Attrbutes: 属性の数、名前、値を取得するために使用されます。
ContentHandler: ドキュメント自体に関連付けられたイベント (開始タグと終了タグなど) を定義します。ほとんどのアプリケーションはこれらのイベントに登録します。
DTDHandler: DTD に関連付けられたイベントを定義します。 DTD を完全にレポートするのに十分なイベントが定義されていません。 DTD の解析が必要な場合は、オプションの DeclHandler を使用します。
DeclHandler は SAX の拡張機能です。すべてのパーサーがこれをサポートしているわけではありません。
EntityResolver: エンティティの読み込みに関連付けられたイベントを定義します。これらのイベントに登録するアプリケーションはわずかです。
ErrorHandler: エラー イベントを定義します。多くのアプリケーションはこれらのイベントを登録して、独自の方法でエラーを報告します。
DefaultHandler: これらのインターフェースのデフォルト実装を提供します。ほとんどの場合、アプリケーションはインターフェイスを直接実装するよりも、DefaultHandler を拡張して関連メソッドをオーバーライドする方が簡単です。 ️ SAX プロセッサの説明 立ち上がって XML ドキュメントを解析します。
SAX 解析プロセス:
startDocument --> startElement -->> endDocument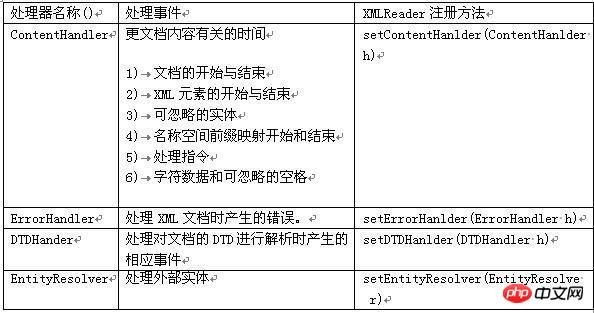
はプルによって返されます: 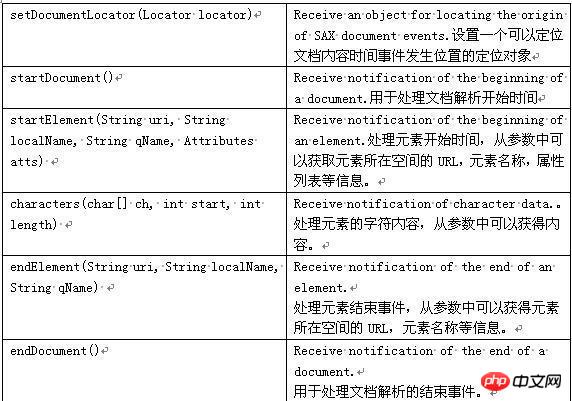
は XML の宣言を読み取り、START_DOCUMENT を返します。
は XML の開始タグを読み取り、START_TAG を返します。 XML 終わりタグは END_TAG を返します;
xml に読み込まれたテキストは TEXT を返します;
プルの仕組み: プルは開始要素と終了要素を提供します。要素が開始されると、パーサーを呼び出すことができます。
次Text は、XML ドキュメントからすべての文字データを抽出します。ドキュメントの解釈が終了すると、EndDocument イベントが自動的に生成されます。
一般的に使用される XML プル インターフェイスとクラス:XmlSerializer: XML 情報セットのシーケンスを定義するインターフェイスです。
XmlPullParserFactory: このクラスは、XMPULL V1 API で XML プル パーサーを作成するために使用されます。 XmlPullParserException: 単一の XML プル パーサー関連エラーをスローします。 PULL の解析プロセス:
Start_document -& GT; Start_tag -& End_tagAndroid では 4 番目の方法もあります。 API、アンドロイド。ユーティリティ。 XML クラスは XML ファイルを解析することもできます。使用方法は SAX と似ています。XML 解析を処理するためのハンドラーを作成する必要もありますが、以下に示すように SAX よりも簡単に使用できます。ユーティリティ。 XML は XML 解析を実装します:
MyHandler myHandler=new MyHandler0;ユーティリティ。 Xm1. parse(url.openC0nnection().getlnputStream(),
のディレクトリ)霊運河は広西チワン族自治区興安県にあり、世界最古の運河の一つであり、「世界の古代水利建築の真珠」という評判があります。霊曲は古代、秦卓曲、霊曲、斗河、興安運河として知られ、紀元前 214 年に建設され、2217 年前に航行が可能になりました。
244d3c.jpg
nan、jiaozhou、ping du、gaomi、changyi and laizhouなど、5,400平方キロメートルの排水エリアがあります北から南に黄海と渤海を結びます。焦来運河は平度耀家村の東の分水界で北から南に分かれています。南の流れは馬湾口から膠州湾に流れ込み、長さ30キロメートルの南塩来河と呼ばれます。北潮は海滄口から莱州湾に流れ込み、長さ100キロメートル以上の北焦来河です。 B8322E08244D3C.JPG東。全長は168km。
ノード情報の観察を容易にし、River クラスを抽象化するには、River オブジェクトを使用してデータを保存する必要があります
public
class River {
name;/ / 名前
Integerlength; // 長さ
String の導入;
public void setName(String name) {
this.name = name;
}
public Integer getLength() {
}
}public void set Introduction(String Introduction) {
this.introduction = Introduction;public String getImageurl( ) {}public void setImageurl(String imageurl) {}@Overridereturn "川 [name=" + name + ", length=" + length + ", Introduction=""
+ Introduction + ", Imageurl=" + Imageurl + "]";}}DOM 解析を使用する場合 具体的な処理手順は次のとおりです:
1 まず DocumentBuilderFactory を使用して、 DocumentBuilderFactory インスタンス
2 次に、DocumentBuilderFactory を使用して DocumentBuilder を作成します
3 次に、XML ドキュメント (Document) をロードします
4 次に、ドキュメントのルート ノード (Element) を取得します
5 次に、すべての子ノードのリストを取得しますルートノード (NodeList) で、
6 次に、それを使用して、子ノードリストで読み取る必要があるノードを取得します。
ここで、xml ドキュメント オブジェクトの読み取りを開始し、リストに追加します:
コードは次のとおりです: ここではアセットで River.xml ファイルを使用しています。次に、この XML ファイルを読み取り、入力ストリームを返します。 読み取りメソッドは次のとおりです: inputStream=this.context.getResources().getAssets().open(fileName); もちろん、デフォルトは XML ファイルのパスです。ルートディレクトリ。
その後、DocumentBuilder オブジェクトの parse メソッドを使用して入力ストリームを解析し、ドキュメント オブジェクトを返し、ドキュメント オブジェクトのノード属性を走査できます。
/*** DOM 解析 XML メソッド
* @param filePath
* @return
*/
private ListDOMfromXML(String filePath) {
ArrayListlist = new ArrayList();
DocumentBuilderFactory Factory = null;
DocumentBuilder ビルダー = null;
Document document = null;
InputStream inputStream = null;
//パーサーを構築します
factory = DocumentBuilderFactory.newInstance();
try {
builder = Factory.newDocumentBuilder();
/ /xml ファイルを見つけてロードします
inputStream = this.getResources().getAssets().open(filePath); //getAssets 後のデフォルトのルート ディレクトリはassets です
document = builder.parse(inputStream);
//ルート要素を検索
Element root=document.getDocumentElement();
NodeList ノード=root.getElementsByTagName(RIVER);
//ルートノードのすべての子ノード、川の下のすべての川を走査します
River River = null;
for (int i = 0; i
river = new River();
//川要素ノードを取得します
Element RiverElement = (Element )nodes.item(i);
//riverに名前と長さの属性値を設定します
river.setName(riverElement.getAttribute("name"));
river.setLength(Integer.parseInt(riverElement) .getAttribute("length"))) ;
//サブタグを取得
要素の導入 = (要素) RiverElement.getElementsByTagName(INTRODUCTION).item(0);
要素 imageurl = (要素) RiverElement.getElementsByTagName( IMAGEURL).item(0);
//紹介属性と imageurl 属性を設定します
river.set Introduction(introduction.getFirstChild().getNodeValue());
river.setImageurl(imageurl.getFirstChild().getNodeValue() );
list.add(river);
}
} catch (ParserConfigurationException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
} catch (IOException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
} catch (SAXException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
}
for (River River : list) {
Log.w("DOM Test", River.toString());
}
return list;
}
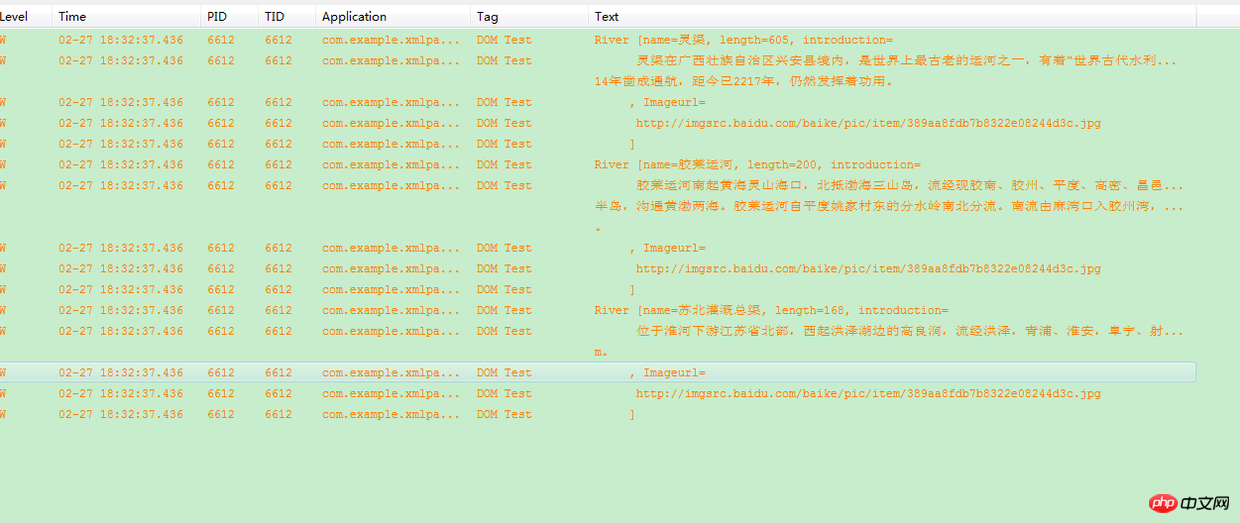
ここでリストに追加します。そして、ログを使用してそれらを出力します。図に示すように:
XML 解析結果
SAX 解析を使用する場合の具体的な処理手順は次のとおりです:
1 SAXParserFactory オブジェクトを作成します
2 SAXPars に従ってerFactory.newSAXParser ()メソッド SAXParserパーサーを返す
3 SAXParserパーサーに従ってイベントソースオブジェクトXMLReaderを取得する
4 DefaultHandlerオブジェクトをインスタンス化する
5 イベントソースオブジェクトXMLReaderをイベント処理クラスDefaultHandlerに接続する
6 parseメソッドを呼び出す取得した XML データ
7 は、DefaultHandler を通じて必要なデータセットを返します。コードは次のとおりです:
/**&#&*/Privatelistsaxfromxml(string filepath){
rayList= new ArrayList(); Factory = SAXParserFactory .newInstance();
SAXParser parser = null;
XMLReader xReader = null;
try {
parser = Factory.newSAXParser();
//データソースを取得
xReader = parser. getXMLReader(); //プロセッサを設定しますRiverHandler handler = new RiverHandler();xReader.setContentHandler(handler);//xml ファイルを解析しますxReader.parse(new InputSource(this.getAssets) ().open( filePath)));list = handler.getList();} catch (ParserConfigurationException e) {e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
for (川: list) {
Log.w("DOM Test", River.toString());
}
return list;
}
以上がAndroid での XML 解析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。