
ホームページ >WeChat アプレット >ミニプログラム開発 >陰陽師ミニプログラムを24時間開発
陰陽師ミニプログラムを24時間開発
- 巴扎黑オリジナル
- 2017-04-01 15:26:122446ブラウズ
0.序文
陰陽師をプレイしている人は皆、封印ミッションが毎日午前5時と午後6時に2回更新されることを知っています。ミッションを行うたびに最も面倒なことは、あらゆる種類のモンスターを見つけることです。 . 対応するコピーと謎の手がかり。 Onmyoji は一部のデータ クエリに NetEase Genie を提供していますが、そのエクスペリエンスがあまりにも感動的であるため、ほとんどの人はモンスターの分布や謎の手がかりを検索するために検索エンジンを使用することを選択しています。
毎回検索エンジンを使用するのは非常に不便なので、作者は陰陽師のモンスターの分布をクエリする小さなプログラムを作成することにし、エクスペリエンスを高速化し、ドッグフードとより多くの時間を残せるように努めました。ユフン。
先週末はたまたま2日空いていたので、早速書き始めました。
1. コンセプトとデザイン(3時間)1.1 コンセプト
作成するミニプログラムの主な機能はクエリ機能であるため、ホームページは検索エンジンと同じくらいシンプルである必要があります検索ボックスは必ず必要です ;
ホームページには、最も人気のある式神の人気の検索とキャッシュ検索が含まれています
検索は完全一致または単一単語一致をサポートしています
式神の詳細ページに直接ジャンプします。 53. 式神の詳細ページには、式神のイラスト、名前、レア度、出没場所が含まれており、出没場所はモンスターの数が多い順に並べられています。データエラーの報告と提案の機能;
ユーザーの個人的な検索履歴をサポート; ミニプログラムの名前は、ミニプログラムの機能を考慮して、最終的に式神ハンターと呼ばれることに決定しました最終的な開発が完了してから考えました);
- 1.2 デザイン
-
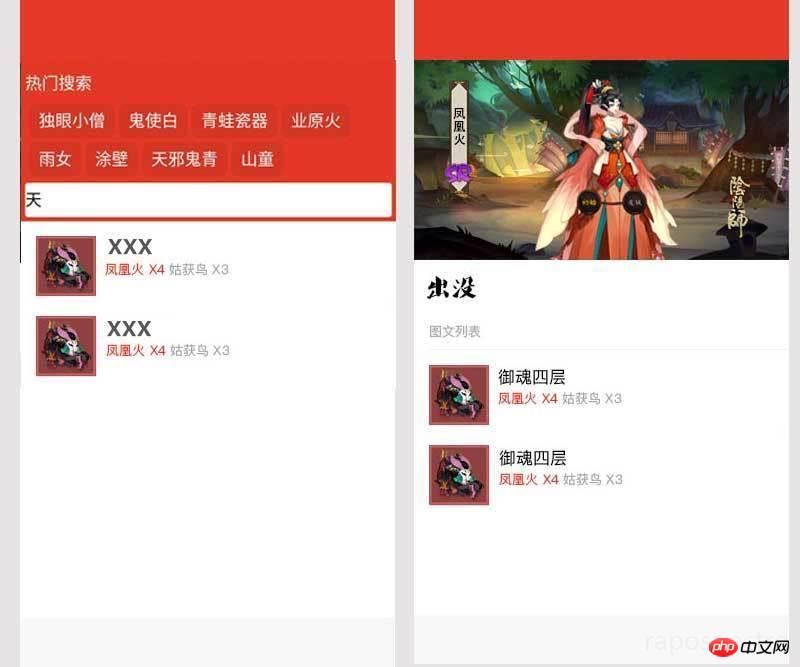
さて、最も重要なホームページと詳細 ページをデザインするだけで、その後はそれをどのように作成するかを考え始めることができます。
1.3 技術アーキテクチャフロントエンドは間違いなくWeChatアプレットです
バックエンドはRestful APIサービスを提供するためにDjangoを使用します
- 検索では Redis を使用しますキャッシュサーバーとして キャッシュ;
- 個人の検索レコードは、WeChat アプレットによって提供されるローカルストレージを使用します。データベース;
- 式神の画像とアイコンを直接クロールする;
- クロールできない式神の画像とアイコンを作成する;
- 以前にやったことがありますが、ここで直接見ることができますHTTPS 無料導入ガイド
- この時点で、正式な開発の前に適切な準備を行った後、正式な開発を開始できます
2. 5 時間)
私はこれまで Django API サービス開発をよく行ってきたので、比較的完全なソリューションを持っています。ここで参照できますdjango-simple-serializer
5 時間かかった理由は、Django ManyToManyField のスルー機能の django-simple-serializer サポートを追加する作業に 5 時間 4 時間近くかかったからです。
つまり、スルー機能を使用すると、多対多の関係の中間テーブルに追加のフィールドまたは属性を追加できます。たとえば、モンスターのコピーとモンスター間の多対多の関係では、次のことが必要になります。モンスターの数に応じてフィールド数が存在します。
サポートを通過すると、API の構築が非常に速くなります。
- 検索インターフェース。
- 神インターフェイスをコピーします。
- フィードバック インターフェイスを作成したら、テスト用のモック データを追加します。開発( 8 時間)
- フロントエンドが最も時間がかかりました。
一方で、著者は実際にはバックエンドエンジニアであり、フロントエンドは中途半端な僧侶ですが、その一方で、ミニプログラムにはいくつかの落とし穴があります。 もちろん、最も重要なことはインターフェイスの効果を常に調整することですが、これには多くの時間がかかります。
ミニプログラムを書く全体的な経験は、一部の HTML タグが使用できないことを除いて、vue.js を書くのとまったく同じであると感じています。代わりに、公式のコンポーネントに従って記述する必要があります。ミニプログラムによって提供されるものは次のとおりです。 私の印象では、ミニプログラム自体のコンポーネント化された設計思想は React に基づいており、構文は vue.js に基づいている必要があります。
最終的なフロントエンド開発が完了すると、主に次のページに分かれます:
ホームページ(検索ページ)
マイページ (主に検索履歴、免責事項など); フィードバックインターフェース (なぜこのインターフェースが必要なのでしょうか? すべての画像と一部のリソースは陰陽師の公式リソースから直接取得されているためです)したがって、非営利使用のみであり、著作権はすべて陰陽師にあることをここに明記する必要があります)。
ねえ、醜い義理の娘は遅かれ早かれ義理の両親に会う予定なので、最終的に開発されたインターフェイス図をここに置かなければなりません
WeChat ミニ プログラムについては、ここでは WeChat アプレットの概要と基本については詳しく説明しませんが、現在 WeChat アプレットに興味がある開発者は、簡単なデモを問題なく作成できると思います。主に私の開発経験について話します:
- 3.1 背景画像属性
式神の詳細ページを作成する場合、背景画像属性を 2 つの場所で使用する必要があります。 WeChat開発者ツールでは正常に表示されましたが、実機でデバッグしたところ、最終的にアプレットの背景画像がサポートされていないことが判明しました。実マシン上のローカル リソースを参照する 解決策は 2 つあります:
ネットワーク画像を使用する: 背景画像のサイズを考慮して、作者はこの解決策を断念しました。画像をエンコードするために Base64 を使用します。
通常、CSS の背景画像は Base64 をサポートしており、この解決策は、画像を Base64 で直接エンコードして保存することと同じです。
[CSS] プレーンテキストビュー コードをコピー
background-image: url(data:image/image-format;base64,XXXX);
image-formatは画像自体の形式、xxxxはbase6後に取得された画像です4 エンコード。この方法は、実際にはローカルリソースを参照する偽装方法であり、画像リクエストの数を減らすことができるという利点がありますが、CSSファイルのサイズが大きくなり、あまり美しくないという欠点があります。
結局、作者が後者を選択したのは、主に画像のサイズとwxssの増加が許容範囲内だったからです。
3.2 テンプレート
アプレットはテンプレートをサポートしていますが、テンプレートには独自のスコープがあり、データによって渡されたデータのみを使用できることに注意してください。
さらに、データを渡すときは、関連するデータを分解して渡す必要があります。テンプレート内では、{{ item ではなく {{ xxxx }} の形式で直接アクセスされます。 xxx のループ。 }} このアクセス形式:
プレーンテキストビュー コードをコピー
<template is="xxx" data="{{...object}}"/>
3. これは構造化操作です。
通常、テンプレートは他のファイルを呼び出すために別のテンプレート ファイルに配置され、通常の wxml には直接記述されません。 。 たとえば、作成者のディレクトリはおそらく次のようになります:
[JavaScript] プレーンテキストビュー コードをコピー
├── app.js ├── app.json ├── app.wxss ├── pages │ ├── feedback │ ├── index │ ├── my │ ├── onmyoji │ ├── statement │ └── template │ ├── template.js │ ├── template.json │ ├── template.wxml │ └── template.wxss ├── static └── utils
他からのテンプレート呼び出しについてファイルを直接使用してください インポートするだけです:
[XML] プレーンテキストビュー コードをコピー
<import src="../template/template.wxml" />
編集場所:
[XML] プレーンテキストビュー コードをコピー
<template is="xxx" data="{{...object}}"/>
这里遇到另一个问题,template 对应的样式写在 template 对应的 wxss 中并没有作用,需要写在调用 template 的文件的 wxss 中,比如 index 需要使用 template 则需要将对应的 css 写在 my/my.wxss 中。
4. 爬取图片资源 ( 2小时 )
式神的图标及形象图基本上阴阳师官网都有,这里自己做也不现实,所以果断写爬虫爬下来然后存到自己的 cdn 。
大图和小图都在 http://yys.163.com/shishen/index.html 这里可以找到。 一开始考虑爬取网页然后 beautiful soup 提取数据,后面发现式神数据竟然是异步加载的,那就更简单了,分析网页得到 https://g37simulator.webapp.163.com/get_heroid_list 直接返回了式神信息的 json 信息,所以很容易写个爬虫就可以搞定了:
[Python] 纯文本查看 复制代码
# coding: utf-8
import json
import requests
import urllib
from xpinyin import Pinyin
url = "https://g37simulator.webapp.163.com/get_heroid_list?callback=jQuery11130959811888616583_1487429691764&rarity=0&page=1&per_page=200&_=1487429691765"
result = requests.get(url).content.replace('jQuery11130959811888616583_1487429691764(', '').replace(')', '')
json_data = json.loads(result)
hellspawn_list = json_data['data']
p = Pinyin()
for k, v in hellspawn_list.iteritems():
file_name = p.get_pinyin(v.get('name'), '')
print 'id: {0} name: {1}'.format(k, v.get('name'))
big_url = "https://yys.res.netease.com/pc/zt/20161108171335/data/shishen_big/{0}.png".format(k)
urllib.urlretrieve(big_url, filename='big/{0}@big.png'.format(file_name))
avatar_url = "https://yys.res.netease.com/pc/gw/20160929201016/data/shishen/{0}.png".format(k)
urllib.urlretrieve(avatar_url, filename='icon/{0}@icon.png'.format(file_name))然而,爬完数据后发现一个问题,网易官方的图片都是无码高清大图,对于笔者这种穷 ds 大图放在 cdn 上两天就得破产,所以需要批量将图片转成既不太大又能看的过去。嗯,这里就可以用到 ps 的批处理能力了。
打开 ps ,然后选择爬到的一张图片;
选择菜单栏上的“窗口”然后选择“动作;
在“动作”选项下,新建一个动作;
点击圆形录制按钮开始录制动作;
按正常处理图片等顺序将一张图片存为 web 格式;
点击方形停止按钮停止录制动作;
选择菜单栏上的 文件-自动-批处理-选择之前录制的动作-配置好输入文件夹和输出文件夹;
点击确定就可以啦;
等批处理结束,期间刷个御魂啥的应该就好了,然后将得到的所有图片上传到静态资源服务器,图片这里就处理完啦。
5. 式神数据爬取 ( 4小时 )
式神分布数据网上比较杂并且数据很多有偏差,所以斟酌再三决定采用半人工半自动的方式,爬到的数据输出为 json:
[JavaScript]
{
"scene_name": "探索第一章",
"team_list": [{
"name": "天邪鬼绿1",
"index": 1,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "天邪鬼绿2",
"index": 2,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "提灯小僧1",
"index": 3,
"monsters": [{
"name": "天邪鬼绿",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "提灯小僧2",
"index": 4,
"monsters": [{
"name": "灯笼鬼",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "首领",
"index": 5,
"monsters": [{
"name": "九命猫",
"count": 3
}]
}]
}然后再人工检查一遍,当然还是会有遗漏,所以数据报错的功能就很重要啦。
这一部分实际写代码的时间可能只有半个多小时,剩下时间一直在检查数据;
一切检查结束后写个脚本直接将 json 导入到数据库中,检查无误后用 fabric 发布到线上服务器进行测试;
6. 测试 ( 2小时 )
最后一步基本上就是在手机上体验查错,修改一些效果,关闭调试模式准备提交审核;
もう日曜日だ、ああ、いや、月曜の朝一時のはずだ:
ミニプログラムチーム 月曜日の午後に承認されて、思い切ってオンラインになりました。
最終レンダリング:
以上が陰陽師ミニプログラムを24時間開発の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。