
ホームページ >Java >&#&チュートリアル >JavaにおけるHashMapの実装原理を深く理解する(写真)
JavaにおけるHashMapの実装原理を深く理解する(写真)

- 黄舟オリジナル
- 2017-03-28 10:32:591929ブラウズ
この記事は主に Java での HashMap の実装原理を深く理解するための関連情報を紹介します。必要な方は参照してください
1 のデータ構造。構造体には実装する配列とリンク リストが含まれます。 データ ストレージの場合、これら 2 つは基本的に両極端です。
配列の保存間隔は連続的で、多くのメモリを占有するため、スペースが非常に複雑になります。ただし、配列の
二分探索時間計算量は小さく、O(1); 配列の特徴は次のとおりです: アドレス指定が簡単、
リンクリストストレージ。間隔は離散的であり、占有されるメモリは比較的緩やかであるため、空間計算量は非常に小さいですが、時間計算量は非常に大きく、O(N) に達します。
リンクリストの特徴は、アドレス指定が難しく、挿入と削除が簡単であることです。
ハッシュ テーブルそれでは、2 つの特性を組み合わせて、アドレス指定が簡単で、挿入と削除が簡単なデータ構造を作成できるでしょうか?答えは「はい」です。これがこれから説明するハッシュ テーブルです。ハッシュテーブル(ハッシュテーブル)は、データ検索の利便性を満たすだけでなく、コンテンツスペースをあまり占有せず、非常に使いやすいです
ハッシュテーブルにはさまざまな実装方法があります。次は最も一般的に使用されるメソッドであるジッパーメソッドで、図に示すように「リンクされたリストの配列」として理解できます。
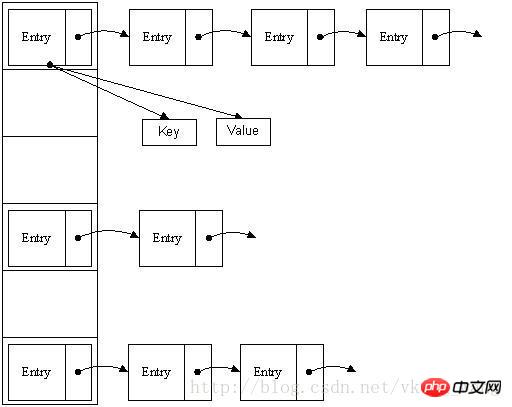
上の図から、ハッシュ テーブルは
で構成されます。長さ 16 の配列では、各要素がリンク リストの先頭ノードを格納します。では、これらの要素を配列に格納するには、どのようなルールが使用されますか? key)%len を取得します。つまり、要素のキーのハッシュ値が配列長を法として取得されます。たとえば、上記のハッシュ テーブルでは、12%16=12、28%16=12、108%16=12 となります。 , 140%16=12. 108 と 140 は両方とも配列インデックス 12 に格納されます。HashMap は実際には線形配列として実装されているため、データを格納するコンテナーは線形配列であると理解できます。配列内のキーと値のペアによってデータにアクセスするにはどうすればよいでしょうか? ここで、HashMap は、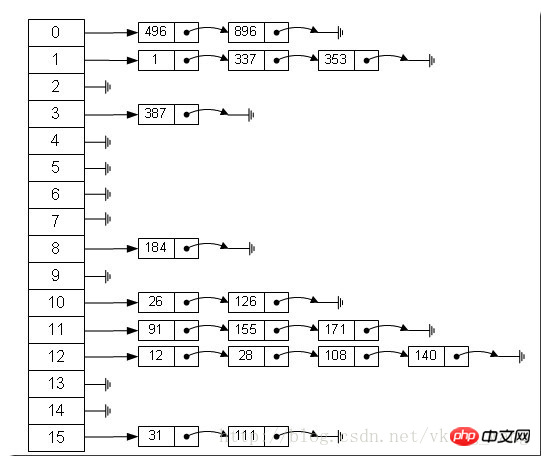 static
static
内部クラス Entry を実装します。その重要な
には、属性キーと値が含まれます。上で述べたように、Entry は HashMap のキーと値のペアを実装するための基本的な Bean であることがわかります。この配列は Entry[] であり、Map の内容は に格納されます。 Entry[] 内 /**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
線形配列なので、なぜランダムにアクセスできるのでしょうか? ここで、HashMap は次のように実装されています: // 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1) put 質問: hash%Entry[].length を通じて 2 つのキーによって取得されたインデックスが同じ場合、上書きされるリスクはありますか?
ここでHashMapには連鎖データ構造の概念が使われています。 Entry クラスには次の Entry を指す next 属性があると上で述べました。たとえば、最初のキーと値のペア A が入ってくると、そのキーのハッシュを計算して得られたインデックス = 0 が Entry[0] = A として記録されます。しばらくすると、別のキーと値のペア B が入ってきます。計算により、そのインデックスは 0 に等しくなります。どうすればよいでしょうか。 HashMap はこれを実行します: B.next = A, Entry[0] = B。C が再び入ってくると、インデックスも 0 に等しく、
C.next = B, Entry[0] = C;このようにして、index =0 に実際には 3 つのキーと値のペア A、B、および C が格納されていることがわかります。これらは次の属性を通じて相互にリンクされています。ご質問があってもご心配なく。
つまり、最後に挿入された要素が配列に格納されます。この時点で、HashMap の一般的な実装について明確に理解しているはずです。 public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
} もちろん、HashMap にはいくつかの最適化実装も含まれており、それについてもここで説明します。例: Entry[] の長さが固定された後、マップ内のデータがますます長くなるにつれて、同じインデックスのチェーンが非常に長くなります。パフォーマンスに影響しますか? HashMap には係数が設定されます。マップのサイズが大きくなるにつれて、Entry[] は一定の規則に従って長くなります。
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
} 3) Null キーへのアクセス Null キーは常に Entry[] 配列の最初の要素に格納されます。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}4) 配列インデックスを決定します: hashcode % table.length modulo
HashMap にアクセスするときは、現在のキーが Entry[] 配列のどの要素に対応するかを計算する必要があります。つまり、配列の添字を計算する必要があります。 ; アルゴリズムは次のとおりです:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
} ビット単位の結合は、剰余 % を取得することと同等です。 これは配列の添え字が同じであることを意味しますが、ハッシュコードが同じであることを意味するわけではありません。
5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列) 再哈希法 链地址法 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}以上がJavaにおけるHashMapの実装原理を深く理解する(写真)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。