
ホームページ >バックエンド開発 >PHPチュートリアル >PHP Redisのメモリ使用量を削減する方法(画像とテキスト)
PHP Redisのメモリ使用量を削減する方法(画像とテキスト)

- 黄舟オリジナル
- 2017-03-24 09:34:522753ブラウズ
この記事では主にPHP Redisのメモリ使用量を削減する方法を紹介します。非常に良い基準値を持っています。エディターで見てみましょう
1. Redisのメモリ使用量を削減するメリット
1. スナップショットの作成と読み込みにかかる時間を短縮できます
2. AOFファイルの読み込みとAOFファイルの書き換えの効率が向上します
3. サーバーからの同期に必要な時間を短縮します
4. Redis は追加のハードウェアを追加することなく、より多くのデータを保存できます
2. 短い構造
Redis はリストであり、Set、ハッシュ、および順序付きセットがセットを提供しますRedis がより経済的な方法で短い構造を保存できるようにする構成オプション。
2.1、ziplist圧縮リスト(リスト、ハッシュ、続編付き)
通常使用される保存方法

リスト、ハッシュ、順序付きセットの場合長さが短い場合やボリュームが小さい場合、redis は ziplist と呼ばれるコンパクトな保存方法を使用してこれらの構造を保存します。
Ziplist は、リスト、ハッシュ、順序付きセットという 3 つの異なるタイプのオブジェクトの非構造化表現であり、これらのシリアル化されたデータが読み取られるたびに、データが書き込まれるたびにデコードおよびエンコードされる必要があります。 。
双方向リストと圧縮リストの違い:
圧縮リストが他のデータ構造よりも多くのメモリを節約することを理解するために、詳細な研究のための例としてリスト構造を取り上げます。
典型的な双方向リスト
典型的な双方向リストでは、各値はノードによって表されます。各ノードは、リンクされたリストの前のノードと次のノードへのポインターと、ノードに含まれる string 値へのポインターを持ちます。
各ノードに含まれる文字列値は、保存のために 3 つの部分に分割されます。文字列の長さ、文字列値に残っている利用可能なバイト数、および NULL で終了する文字列自体が含まれます。
例:
特定のノードが文字列「abc」を格納する場合、32 ビット プラットフォームでは 21 バイトの追加オーバーヘッドが必要になると控えめに見積もられます (3 つのポインター + 2 つの int + null 文字、つまり: 3*4) +2*4+1=21)
例からわかるように、3 バイトの文字列を保存するには、少なくとも 21 バイトの追加のオーバーヘッドが必要です。
ziplist
ziplist はノードのシーケンスであり、それぞれに 2 つの長さと文字列が含まれます。最初の長さは前のノードの長さを記録します (圧縮リストを後ろから前に移動するために使用されます)。2 番目の長さは、格納された文字列内の現在のポイントの長さです。
例:
文字列 'abc' を格納すると、どちらの長さも 1 バイトで格納できるため、追加のオーバーヘッドは 2 バイトになります (2 つの長さは 1+1=2)
結論:
圧縮リストは、追加のポインターやメタデータの保存を回避することで、追加のオーバーヘッドを削減します。
設定:
#list list-max-ziplist-entries 512 #表示允许包含的最大元素数量 list-max-ziplist-value 64 #表示压缩节点允许存储的最大体积 #hash #当超过任一限制后,将不会使用ziplist方式进行存储 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 #zset zset-max-ziplist-entries 128 zset-max-ziplist-value 64
テストリスト:
1. test.phpファイルを作成します
#test.php
<?php
$redis=new Redis();
$redis->connect('192.168.95.11','6379');
for ($i=0; $i<512 ; $i++)
{
$redis->lpush('test-list',$i.'-test-list'); #往test-list推入512条数据
}
?>
この時点のtest-listには512個のデータが含まれており、設定には余分なものはありません。ファイル 制限事項
2. 別のデータを test-list にプッシュする

この時点で、test-list には 513 個のデータが含まれており、これは設定ファイルで制限されている 512 個よりも大きくなります。 Indexはziplist保存方法を放棄し、他の元のリンクリスト保存方法
ハッシュを使用します。順序付きセットと同じです。2.2, intsetintegerSet (set)
前提条件として、セットに含まれるすべてのメンバーは 10 進整数として解析できます。 順序付けられたarray 方式でコレクションを保存すると、メモリ消費が削減されるだけでなく、コレクション操作の実行速度も向上します。
設定:
set-max-intset-entries 512 #限制集合中member个数,超出则不采取intset存储
テスト:
test.phpファイルを作成します#test.php
<?php
$redis=new Redis();
$redis->connect('192.168.95.11','6379');
for ($i=0; $i<512 ; $i++)
{
$redis->sadd('test-set',$i); #给集合test-set插入512个member
}
?>

2.3、性能问题
不管列表、散列、有序集合、集合,当超出限制的条件后,就会转换为更为典型的底层结构类型。因为随着紧凑结构的体积不断变大,操作这些结构的速度将会变得越来越慢。
测试:
#将采用list进行代表性测试
测试思路:
1、在默认配置下往test-list推入50000条数据,查看所需时间;接着在使用rpoplpush将test-list数据全部推入到新列表list-new中,查看所需时间
2、修改配置,list-max-ziplist-entries 100000,再执行上面的同样操作
3、对比时间,得出结论
默认配置下测试:
1、插入数据,查看时间
#test1.php
<?php
header("content-type: text/html;charset=utf8;");
$redis=new Redis();
$redis->connect('192.168.95.11','6379');
$start=time();
for ($i=0; $i<50000 ; $i++)
{
$redis->lpush('test-list',$i.'-aaaassssssddddddkkk');
}
$end=time();
echo "插入耗时为:".($end-$start).'s';
?>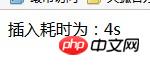

结果耗时4秒
2、执行相应命令,查看耗时
#test2.php
<?php
header("content-type: text/html;charset=utf8;");
$redis=new Redis();
$redis->connect('192.168.95.11','6379');
$start=time();
$num=0;
while($redis->rpoplpush('test-list','test-new'))
{
$num+=1;
}
echo '执行次数为:'.$num."<br/>";
$end=time();
echo "耗时为:".($end-$start).'s';
?>
更改配置文件下测试
1、先修改配置文件
list-max-ziplist-entries 100000 #将这个值修改大一点,可以更好的凸显对性能的影响
list-max-ziplist-value 64 #此值可不做修改
2、插入数据
执行test1.php
结果为:耗时12s

3、执行相应命令,查看耗时
执行test2.php
结果为:执行次数:50000,耗时12s
结论:
在本机中执行测试50000条数据就相差8s,若在高并发下,长压缩列表和大整数集合将起不到任何的优化,反而使得性能降低。
3、片结构
分片的本质就是基于简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据发送到哪个位置上。很多数据库使用这种技术来扩展存储空间,并提高自己所能处理的负载量。
结合前面讲到的,我们不难发现分片结构对于redis的重要意义。因此我们需要在配置文件中关于ziplist以及intset的相关配置做出适当的调整。
3.1、分片式散列
#ShardHash.class.php
<?php
class ShardHash
{
private $redis=''; #存储redis对象
/**
* @desc 构造函数
*
* @param $host string | redis主机
* @param $port int | 端口
*/
public function construct($host,$port=6379)
{
$this->redis=new Redis();
$this->redis->connect($host,$port);
}
/**
* @desc 计算某key的分片ID
*
* @param $base string | 基础散列
* @param $key string | 要存储到分片散列里的键名
* @param $total int | 预计非数字分片总数
*
* @return string | 返回分片键key
*/
public function shardKey ($base,$key,$total)
{
if(is_numeric($key))
{
$shard_id=decbin(substr(bindec($key),0,5)); #取$key二进制高五位的十进制值
}
else
{
$shard_id=crc32($key)%$shards; #求余取模
}
return $base.'_'.$shard_id;
}
/**
* @desc 分片式散列hset操作
*
* @param $base string | 基础散列
* @param $key string | 要存储到分片散列里的键名
* @param $total int | 预计元素总数
* @param $value string/int | 值
*
* @return bool | 是否hset成功
*/
public function shardHset($base,$key,$total,$value)
{
$shardKey=$this->shardKey($base,$key,$total);
return $this->redis->hset($shardKey,$key,$value);
}
/**
* @desc 分片式散列hget操作
*
* @param $base string | 基础散列
* @param $key string | 要存储到分片散列里的键名
* @param $total int | 预计元素总数
*
* @return string/false | 成功返回value
*/
public function shardHget($base,$key,$total)
{
$shardKey=$this->shardKey($base,$key,$total);
return $this->redis->hget($shardKey,$key);
}
}
$obj=new ShardHash('192.168.95.11');
echo $obj->shardHget('hash-','key',500);
?>散列分片主要是根据基础键以及散列包含的键计算出分片键ID,然后再与基础键拼接成一个完整的分片键。在执行hset与hget以及大部分hash命令时,都需要先将key(field)通过shardKey方法处理,得到分片键才能够进行下一步操作。
3.2、分片式集合
如何构造分片式集合才能够让它更节省内存,性能更加强大呢?主要的思路就是,将集合里面的存储的数据尽量在不改变其原有功能的情况下转换成可以被解析为十进制的数据。根据前面所讲到的,当集合中的所有成员都能够被解析为十进制数据时,将会采用intset存储方式,这不仅能够节省内存,而且还可以提高响应的性能。
例子:
假若要某个大型网站需要存储每一天的唯一用户访问量。那么就可以使用将用户的唯一标识符转化成十进制数字,再存入分片式set中。
#ShardSet.class.php
<?php
class ShardSet
{
private $redis=''; #存储redis对象
/**
* @desc 构造函数
*
* @param $host string | redis主机
* @param $port int | 端口
*/
public function construct($host,$port=6379)
{
$this->redis=new Redis();
$this->redis->connect($host,$port);
}
/**
* @desc 根据基础键以及散列包含的键计算出分片键
*
* @param $base string | 基础散列
* @param $key string | 要存储到分片散列里的键名
* @param $total int | 预计分片总数
*
* @return string | 返回分片键key
*/
public function shardKey ($base,$member,$total=512)
{
$shard_id=crc32($member)%$shards; #求余取模
return $base.'_'.$shard_id;
}
/**
* @desc 计算唯一用户日访问量
*
* @param $member int | 用户唯一标识符
*
* @return string | ok表示count加1 false表示用户今天已经访问过不加1
*/
public function count($member)
{
$shardKey=$this->shardKey('count',$member,$total=10); #$totla调小一点用于测试
$exists=$this->redis->sismember($shardKey,$member);
if(!$exists) #判断member今天是否访问过
{
$this->redis->sadd($shardKey,$member);
$this->redis->incr('count');
$ttl1=$this->redis->ttl('count');
if($ttl1===-1)
$this->redis->expireat('count',strtotime(date('Y-m-d 23:59:59'))); #设置过期时间
$ttl2=$this->redis->ttl($shardKey);
if($ttl2===-1)
{
$this->redis->expireat("$shardKey",strtotime(date('Y-m-d 23:59:59'))); #设置过期时间
#echo $shardKey; #测试使用
}
#echo $shardKey; #测试使用
return 'ok';
}
return 'false';
}
}
$str=substr(md5(uniqid()), 0, 8); #取出前八位
#将$str作为客户的唯一标识符
$str=hexdec($str); #将16进制转换为十进制
$obj=new ShardSet('192.168.95.11');
$obj->count($str);
?>4、将信息打包转换成存储字节
结合前面所讲的分片技术,采用string分片结构为大量连续的ID用户存储信息。
使用定长字符串,为每一个ID分配n个字节进行存储相应的信息。
接下来我们将采用存储用户国家、省份的例子进行讲解:
假若某个用户需要存储中国、广东省这两个信息,采用utf8字符集,那么至少需要消耗5*3=15个字节。如果网站的用户量大的话,这样的做法将会占用很多资源。接下来我们采用的方法每个用户仅仅只需要占用两个字节就可以完成存储信息。
具体思路步骤:
1、首先我们为国家、以及各国家的省份信息建立相应的'信息表格'
2、将'信息表格'建好后,也意味着每个国家,省份都有相应的索引号
3、看到这里大家应该都想到了吧,对就是使用两个索引作为用户存储的信息,不过需要注意的是我们还需要对这两个索引进行相应的处理
4、将索引当做ASCII码,将其转换为对应ASCII(0~255)所指定的字符
5、使用前面所讲的分片技术,定长分片string结构,将用户的存储位置找出来(redis中一个string不能超过512M)
6、实现信息的写入以及取出(getrange、setrange)
实现代码:
#PackBytes.class.php
<?php
#打包存储字节
#存储用户国家、省份信息
class PackBytes
{
private $redis=''; #存储redis对象
/**
* @desc 构造函数
*
* @param $host string | redis主机
* @param $port int | 端口
*/
public function construct($host,$port=6379)
{
$this->redis=new Redis();
$this->redis->connect($host,$port);
}
/**
* @desc 处理并缓存国家省份数据
* @param $countries string | 第一类数据,国家字符串
* @param $provinces 二维array | 第二类数据,各国省份数组
* @param $cache 1/0 | 是否使用缓存,默认0不使用
*
* @return array | 返回总数据
*/
public function dealData($countries,$provinces,$cache=0)
{
if($cache)
{
$result=$this->redis->get('cache_data');
if($result)
return unserialize($result);
}
$arr=explode(' ',$countries);
$areaArr[]=$arr;
$areaArr[]=$provinces;
$cache_data=serialize($areaArr);
$this->redis->set('cache_data',$cache_data);
return $areaArr;
}
/**
* @desc 将具体信息按表索引转换成编码信息
*
* @param $countries,$provinces,$cache| 参考dealData方法
* @param $country string | 具体信息--国家
* @param $province string | 具体信息--省份
*
* @return string | 返回转换的编码信息
*/
public function getCode($countries,$provinces,$country,$province,$cache=0)
{
$dataArr=$this->dealData($countries,$provinces,$cache=0);
$result=array_search($country, $dataArr[0]); #查找数组中是否含有data1
if($result===false) #判断是否存在
return chr(0).chr(0); #不存在则返回初始值
$code=chr($result);
$result=array_search($province, $dataArr[1][$country]); #查找数组中是否含有data2
if($result===false)
return $code.chr(0);
return $code.chr($result); #返回对应ASCII(0~255)所指定的字符
}
/**
* @desc 计算用户存储编码数据的相关位置信息
*
* @param $userID int | 用户的ID
*
* @return array | 返回一个数组 包含数据存储时的分片ID、以及属于用户的存储位置(偏移量)
*/
public function savePosition($userID)
{
$shardSize=pow(2, 3); #每个分片的大小
$position=$userID*2; #user的排位
$arr['shardID']=floor($position/$shardSize); #分片ID
$arr['offset']=$position%$shardSize; #偏移量
return $arr;
}
/**
* @desc | 整合方法,将编码信息存入redis中string相应的位置
*
* @param $userID int | 用户ID
* @param $countries string | 第一类数据,国家字符串
* @param $provinces 二维array | 第二类数据,各国省份数组
* @param $country string | 具体信息--国家
* @param $province string | 具体信息--省份
* @param $cache 1/0 | 是否使用缓存,默认0不使用
*
* @return 成功返回写入位置/失败false
*/
public function saveCode($userID,$countries,$provinces,$country,$province,$cache=0)
{
$code=$this->getCode($countries,$provinces,$country,$province,$cache=0);
$arr=$this->savePosition($userID); #存储相关位置信息
return $this->redis->setrange('save_code_'.$arr['shardID'],$arr['offset'],$code);
}
/**
* @desc 获取用户的具体国家与省份信息
*
* @param $userID int | 用户ID
*
* @return array | 返回包含国家和省份信息的数组
*/
public function getMessage($userID)
{
$position=$this->savePosition($userID);
$code=$this->redis->getrange('save_code_'.$position['shardID'],$position['offset'],$position['offset']+1);
$arr=str_split($code);
$areaArr=$this->dealData('', '',$cache=1); #使用缓存数据
$message['country']=$areaArr[0][ord($arr[0])];
$message['province']=$areaArr[1][$message['country']][ord($arr[1])];
return $message;
}
}
header("content-type: text/html;charset=utf8;");
$countries="无 中国 日本 越南 朝鲜 俄罗斯 巴基斯坦 美国";
$provinces=array(
'无'=>array('无'),
'中国'=>array('无','广东','湖南','湖北','广西','云南','湖南','河北'),
'日本'=>array('无','龟孙子区','王八区','倭国鬼区','鬼子区','萝卜头区'),
);
$obj=new PackBytes('192.168.95.11');
/*
#数据处理,并将其缓存到redis中
$b=$obj->dealData($countries,$provinces);
echo "<pre class="brush:php;toolbar:false">";
print_r($b);
echo "";die;
*/
/*
#存储用户国家省份信息
$country='中国';
$province='广东';
$result=$obj->saveCode(0,$countries,$provinces,$country,$province);
echo ""; print_r($result); echo ""; */ /* #取出用户国家省份信息 $a=$obj->getMessage(15); echo "
"; print_r($a); echo "";die; */ ?>
测试:
1、dealData处理后的信息,即为'信息表表格'

2、saveCode()
| userID | 国家 | 省份 |
| 0 | 中国 | 广东 |
| 13 | 日本 | 龟孙子区 |
| 15 | 日本 | 王八区 |

3、getMessage()

以上がPHP Redisのメモリ使用量を削減する方法(画像とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。