
ホームページ >ウェブフロントエンド >jsチュートリアル >JavaScriptによるスコープ、スコープチェーン、クロージャの詳細説明(画像とテキスト)
JavaScriptによるスコープ、スコープチェーン、クロージャの詳細説明(画像とテキスト)

- 黄舟オリジナル
- 2017-03-21 14:23:371357ブラウズ
この記事では主に図Javascript - スコープ、スコープチェーン、クロージャ、その他の知識を紹介します。非常に良い基準値を持っています。以下のエディターで見てみましょう
スコープとは何ですか?
スコープとは、コードのコンパイル段階で決定され、変数と関数のアクセス可能な範囲を規定するルールです。グローバル変数にはグローバル スコープがあり、ローカル変数にはローカル スコープがあります。 js はブロックレベルのスコープを持たない言語です (if、for などのステートメントを含む中括弧のコード ブロック、または個々の中括弧のコード ブロックはローカル スコープを形成できません)。そのため、js のローカル スコープの形成は次のようになります。関数の中括弧内で定義されたコード ブロック、つまり関数スコープが形成されます。
スコープチェーンとは何ですか?
スコープ チェーンはスコープ ルールの実装です。スコープ チェーンの実装を通じて、そのスコープ内で変数にアクセスでき、そのスコープ内で関数を呼び出すことができます。
スコープチェーンは、一方向にのみアクセスできるリンクリストであり、このリンクリストの各ノードは、実行コンテキストの変数オブジェクトです(コードが実行されるときのアクティブなオブジェクト)。 -way リンク リスト (最初に訪問したノードからアクセス可能) は常に、現在呼び出され実行されている関数の変数オブジェクト (アクティブ オブジェクト) であり、末尾は常にグローバル アクティブ オブジェクトです。
スコープチェーンの形成?
コードの実行からスコープチェーンの形成プロセスを見てみましょう。
function fun01 () {
console.log('i am fun01...');
fun02();
}
function fun02 () {
console.log('i am fun02...');
}
fun01();
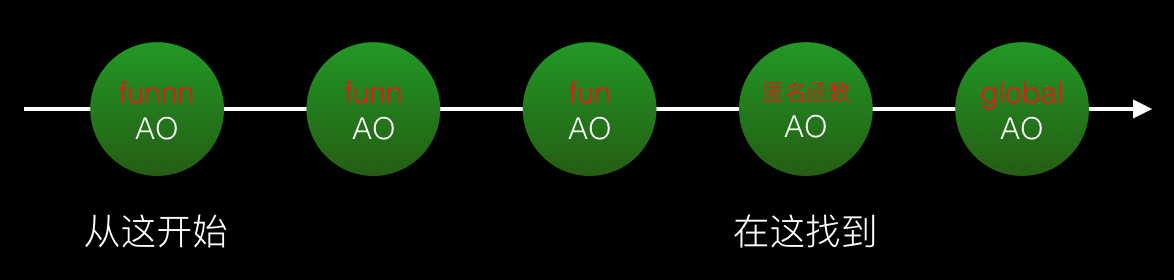
データアクセスプロセス
上の図に示すように、プログラムが変数にアクセスするとき、スコープチェーンの一方向アクセス機能に従って、最初にヘッドノードのAOを検索します。そうでない場合は、次のノードの AO に進み、最後のノード (グローバル AO) まで検索します。この処理では、見つかった場合は、未定義のエラーが報告されます。
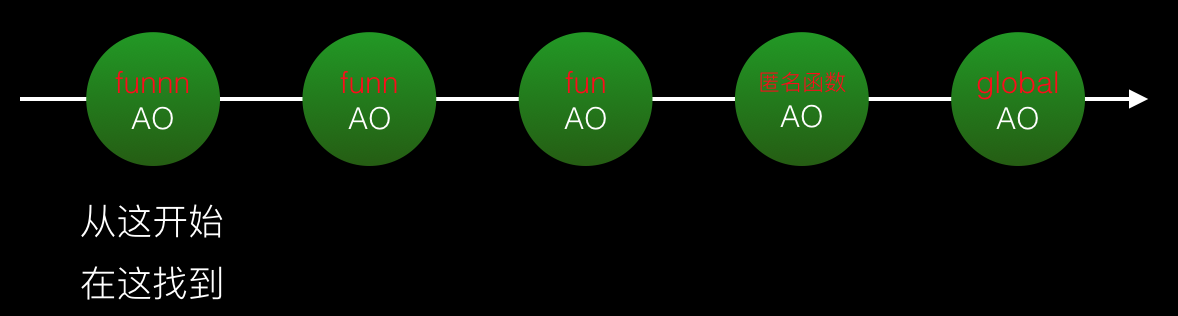
スコープ チェーンを拡張する
上記のスコープ チェーンの形成から、関数が呼び出されて実行されると、チェーン上の各ノードが現在の関数の AO をチェーン ヘッドにシフト解除することがわかります。ノードを形成するもう 1 つの方法は、「スコープ チェーンを拡張する」ことです。これは、必要なオブジェクト スコープをスコープ チェーンの先頭に挿入することを意味します。スコープチェーンを拡張するには 2 つの方法があります:
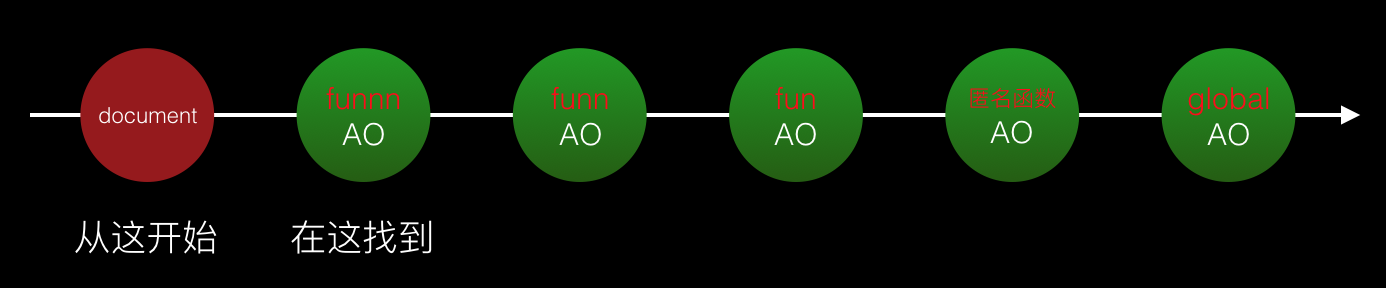
1. with ステートメント
function fun01 () {
with (document) {
console.log('I am fun01 and I am in document scope...')
}
}
fun01();
2. try-catch ステートメントの catch ブロック
function fun01 () {
try {
console.log('Some exceptions will happen...')
} catch (e) {
console.log(e)
}
}
fun01();
ps:ステートメントの使用要件はそれほど多くはありませんが、try-catch の使用も要件に依存します。私は個人的にこれら 2 つをあまり使用しませんが、この部分を整理する過程で、スコープ チェーン レベルでの未熟な パフォーマンス最適化 のヒントをいくつか思いつきました。
スコープチェーンによるパフォーマンスの最適化に関する少し未熟な提案
1. 変数のスコープチェーンのアクセスノードを減らします
ここでは、変数の数を示す「検索距離」と呼ばれるランキングを定義します。未定義の変数にアクセスするときにプログラムが通過するスコープ チェーン内のノード。現在のノードで変数が見つからない場合は次のノードに飛んで検索するため、検索中の変数が次のノードに存在するかどうかも判断する必要があるためです。 「探索距離」が長くなると、より多くの「ジャンプ」動作や「判断」動作が必要となり、リソースのオーバーヘッドが大きくなり、パフォーマンスに影響を与えます。このパフォーマンスのギャップは、少数の変数検索操作ではそれほど大きなパフォーマンス上の問題を引き起こすことはありませんが、変数検索操作が複数回実行される場合、パフォーマンスの比較はより明確になります。(function(){
console.time()
var find = 1 //这个find变量需要在4个作用域链节点进行查找
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
while(i <= 100000000){
if(find){
i++
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
(function(){
console.time()
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
var find = 1 //这个find变量只在当前节点进行查找
while(i <= 100000000){
if(find){
i++
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
2. スコープチェーン内のノード AO で変数定義が多すぎることを避ける
変数定義が多すぎるとパフォーマンスの問題が発生する主な理由は、変数を見つけるプロセスでの「判断」操作のオーバーヘッドが高いことです。 。パフォーマンスの比較には with を使用します。(function(){
console.time()
function fun () {
function funn () {
var funnv = 1;
var funnvv = 2;
function funnn () {
var i = 0
var find = 10
with (document) {
while(i <= 1000000){
if(find){
i++
}
}
}
}
funnn()
}
funn()
}
fun()
console.timeEnd()
})()
在mac pro的chrome浏览器下做实验,进行100万次查找运算,借助with使用document进行的延长作用域链,因为document下的变量属性比较多,可以测试在多变量作用域链节点下进行查找的性能差异。
实验结果:5次平均耗时558.802ms,而如果删掉with和document,5次平均耗时0.956ms。
当然,这两个实验是在我们假设的极端环境下进行的,结果仅供参考!
关于闭包
1.什么是闭包?
函数对象可以通过作用域链相互关联起来,函数体内的数据(变量和函数声明)都可以保存在函数作用域内,这种特性在计算机科学文献中被称为“闭包”。既函数体内的数据被隐藏于作用于链内,看起来像是函数将数据“包裹”了起来。从技术角度来说,js的函数都是闭包:函数都是对象,都关联到作用域链,函数内数据都被保存在函数作用域内。
2.闭包的几种实现方式
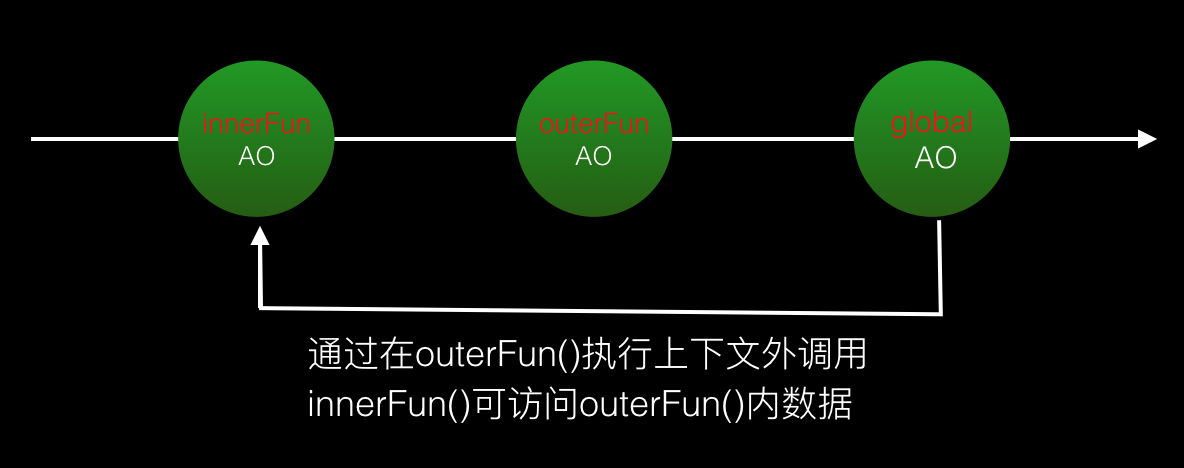
实现方式就是函数A在函数B的内部进行定义了,并且当函数A在执行时,访问了函数B内部的变量对象,那么B就是一个闭包。如下:


如上两图所示,是在chrome浏览器下查看闭包的方法。两种方式的共同点是都有一个外部函数outerFun(),都在外部函数内定义了内部函数innerFun(),内部函数都访问了外部函数的数据。不同的是,第一种方式的innerFun()是在outerFun()内被调用的,既声明和被调用均在同一个执行上下文内。而第二种方式的innerFun()则是在outerFun()外被调用的,既声明和被调用不在同一个执行上下文。第二种方式恰好是js使用闭包常用的特性所在:通过闭包的这种特性,可以在其他执行上下文内访问函数内部数据。
我们更常用的一种方式则是这样的:
//闭包实例
function outerFun () {
var outerV1 = 10
function outerF1 () {
console.log('I am outerF1...')
}
function innerFun () {
var innerV1 = outerV1
outerF1()
}
return innerFun //return回innerFun()内部函数
}
var fn = outerFun() //接到return回的innerFun()函数
fn() //执行接到的内部函数innerFun()此时它的作用域链是这样的:
3.闭包的好处及使用场景
js的垃圾回收机制可以粗略的概括为:如果当前执行上下文执行完毕,且上下文内的数据没有其他引用,则执行上下文pop出call stack,其内数据等待被垃圾回收。而当我们在其他执行上下文通过闭包对执行完的上下文内数据仍然进行引用时,那么被引用的数据则不会被垃圾回收。就像上面代码中的outerV1,放我们在全局上下文通过调用innerFun()仍然访问引用outerV1时,那么outerFun执行完毕后,outerV1也不会被垃圾回收,而是保存在内存中。另外,outerV1看起来像不像一个outerFun的私有内部变量呢?除了innerFun()外,我们无法随意访问outerV1。所以,综上所述,这样闭包的使用情景可以总结为:
(1)进行变量持久化。
(2)使函数对象内有更好的封装性,内部数据私有化。
进行变量持久化方面举个栗子:
我们假设一个需求时写一个函数进行类似id自增或者计算函数被调用的功能,普通青年这样写:
var count = 0
function countFun () {
return count++
}这样写固然实现了功能,但是count被暴露在外,可能被其他代码篡改。这个时候闭包青年就会这样写:
function countFun () {
var count = 0
return function(){
return count++
}
}
var a = countFun()
a()这样count就不会被不小心篡改了,函数调用一次就count加一次1。而如果结合“函数每次被调用都会创建一个新的执行上下文”,这种count的安全性还有如下体现:
function countFun () {
var count = 0
return {
count: function () {
count++
},
reset: function () {
count = 0
},
printCount: function () {
console.log(count)
}
}
}
var a = countFun()
var b = countFun()
a.count()
a.count()
b.count()
b.reset()
a.printCount() //打印:2 因为a.count()被调用了两次
b.printCount() //打印出:0 因为调用了b.reset()以上便是闭包提供的变量持久化和封装性的体现。
4.闭包的注意事项
クロージャ内の変数は他の通常の変数のようにガベージ コレクションされず、常にメモリ内に存在するため、クロージャを多用するとパフォーマンスの問題が発生する可能性があります。
以上がJavaScriptによるスコープ、スコープチェーン、クロージャの詳細説明(画像とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。