
ホームページ >データベース >mysql チュートリアル >MySQLの基礎知識を詳しく紹介(写真)
MySQLの基礎知識を詳しく紹介(写真)

- 黄舟オリジナル
- 2017-03-17 14:18:101246ブラウズ
この記事では主にmysqlに関する超基礎的な知識を紹介します。非常に良い基準値を持っています。以下のエディターで見てみましょう
この記事では主に、その後の SQL 最適化に備えて、mysql に関する非常に基礎的な知識を紹介します。
1: mysql に接続します
ここでは、mysql のダウンロードとインストールについては詳しく説明しません。最初のステップは、mysql サーバーに接続し、cmd コマンドを開き、保存されている bin ディレクトリに切り替えることです。 MySQL サーバーをインストールし、「mysql -h localhost -u root -p」と入力します。ここで、-h はホスト アドレスを表します (このマシンはローカルホストです。ポート番号は含めないでください) -u は
データベースに接続する名を意味します-p は接続パスワードです。次の図が表示されます。これは、接続が成功したことを意味します

2.1: データベースの作成 create database データベース名
2.2: データベースの削除drop データベース データベース名
2.3: クエリを実行しますシステム内のデータベース show databases
2.4: データベースを使用します use データベース名
2.5: データベースのテーブルをクエリします show tables
2.6: テーブル構造をクエリします desc + テーブル名
2.7: SQL ステートメントをクエリして、 table show create table + テーブル名
2.8: テーブル削除 + テーブル名
2.9: 複数のテーブルレコードを一度に削除: delete t1,t2 from t1,t2[where 条件] from の後にエイリアスが使用されている場合、削除後にエイリアスを使用する必要があります
3.0: 1 回限りの更新複数のテーブル更新 t1,t2...tn set t1.field=expr1,tn.exprn=exprn;
Three: Query3.1:通常のクエリを選択します
ここではデータを作成し、2つのAテーブルを配置しました。下の図を見てください
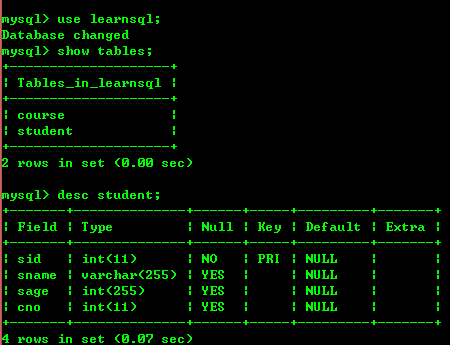
 3.2: 一意のレコードをクエリします
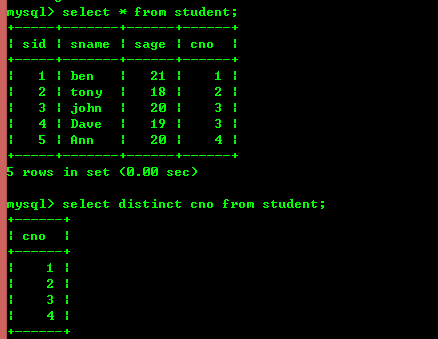
3.2: 一意のレコードをクエリします
以下に示すように、キーワードdistinctを使用します
 3.3:並べ替えと制限
3.3:並べ替えと制限
キーワード order by を使用して、desc降順 asc 昇順で並べ替えます
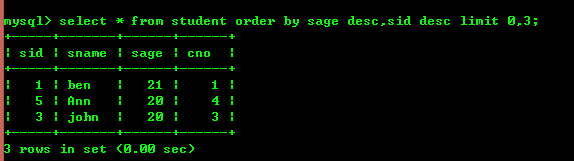 order by の後にフィールドが続きます (order by は、最初のフィールドを最初に並べ替えるために 1 回だけ書かれます)次に 2 番目というようになります。limit の後の最初の数値は単純で、2 は出力の数です)。
order by の後にフィールドが続きます (order by は、最初のフィールドを最初に並べ替えるために 1 回だけ書かれます)次に 2 番目というようになります。limit の後の最初の数値は単純で、2 は出力の数です)。
4:
集計操作 多くの場合、ユーザーは会社全体の人数や部門の人数を数えるなど、何らかの統計を実行する必要があります。この場合、集計操作が使用されます。 。集計操作の構文が登場します
select [field1, field2...fieldn] fun_name from table name
ここで、条件
フィールド1、フィールド2...フィールドnでグループ化
ロールアップあり
条件を持っています
fun_nameは集計関数または集計操作と呼ばれ、一般的なものには、sum (合計)、count (*) レコード数、max (最大値)、min (最小値) などがあります。
group by は、分類および集計するフィールドを示します。たとえば、部門分類に従ってカウントされる部門を、group by の後に記述する必要があります。
with rollup は、その後の組み合わせを集計するかどうかを示すオプションの構文です。分類と集計
は分類された結果をフィルタリングする手段を持っています
4.1: コース番号に従ってクラスの人数を数えます
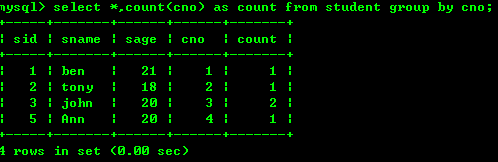 4.2: 学年ごとに人数を数え、総人数を数えます
4.2: 学年ごとに人数を数え、総人数を数えます
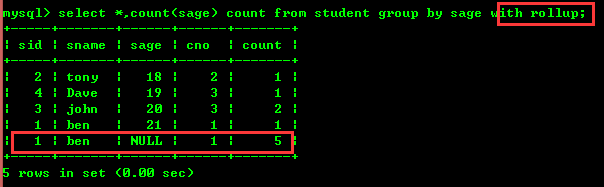 ロールアップは人数を集計するもので、図からわかります。
ロールアップは人数を集計するもので、図からわかります。
4.3: 20歳以上の人の数を数えます
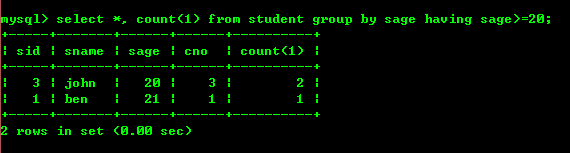 havingとwhereの違い:havingは集計結果をフィルタリングすることですが、whereは集計後のレコードをフィルタリングすることです ロジックが許せば、試してみてください。できる限り最初にレコードをフィルタリングする場所を使用します。これにより、結果セットが減り、集計の効率が大幅に向上します。その後、所有権に基づいてフィルタリングします。
havingとwhereの違い:havingは集計結果をフィルタリングすることですが、whereは集計後のレコードをフィルタリングすることです ロジックが許せば、試してみてください。できる限り最初にレコードをフィルタリングする場所を使用します。これにより、結果セットが減り、集計の効率が大幅に向上します。その後、所有権に基づいてフィルタリングします。
複数のテーブルのフィールドを同時に表示する必要がある場合、テーブル接続を使用してそのような機能を実現できます。大まかに言うと、
内部結合と外部結合に分類できます。それらの主な違いは、内部結合は 2 つのテーブル内の一致するレコードのみを除外するのに対し、外部結合は他の一致しないレコードを除外することです。参加する。 5.1: 学生が選択したコースをクエリする
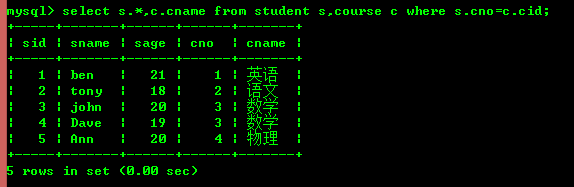
外部結合は左結合と右結合に分かれます。
左結合 (右のテーブルに一致するレコードがない場合でも、左のテーブルのすべてのレコードが含まれます)
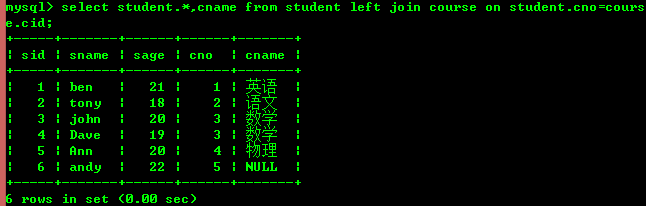
右結合 (左のテーブルに一致するレコードがない場合でも、右のテーブルのすべてのレコードが含まれます) table)
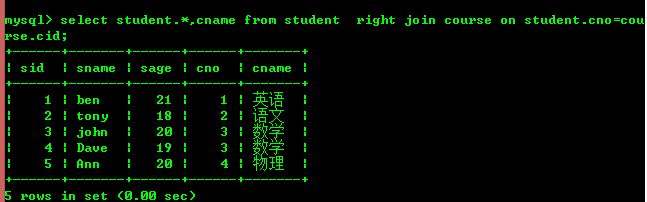
左結合は左側のテーブルに基づいており、右結合は右側のテーブルに基づいていることがわかります。
6: サブクエリ
クエリを実行する場合、必要な条件が別の select ステートメントの結果である場合があります。このとき、サブクエリに使用されるキーワードは主に、in、=、! ではありません。 =、存在する、存在しないなど
クエリに in を使用する場合
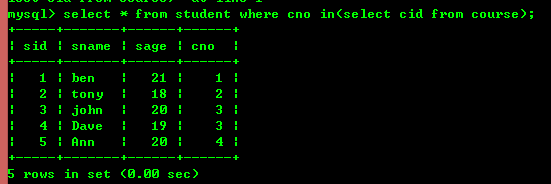
ただし、内部結合を使用すると上記の効果を達成することもできます
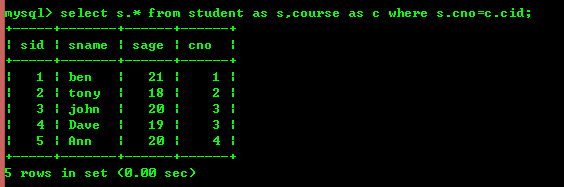
しかし、内部結合の効率は多くの場合、すべてサブクエリより上位であるため、ビジネス ロジックに影響を与えない場合はインライン化が推奨されます。
7: Union
特定のルールに従って 2 つのテーブルのデータをクエリし、結果をマージして一緒に表示します。現時点では、union または Union all を使用できます。具体的な構文は次のとおりです
select * from t1 Unionunion all select * from t2 Unionunion all select * from tn;
union と Union all の違いは、union はフィルターされた結果セットから重複レコードを削除することです。
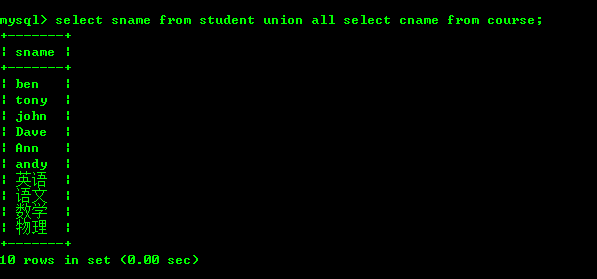
次のように、2 つのテーブルが一致しない場合は結合しないように注意してください

各テーブルの 2 つのフィールドをクエリした場合
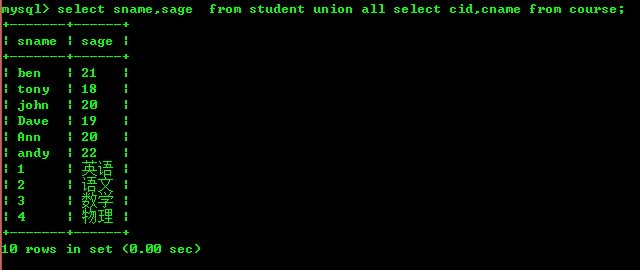
8: 共通関数
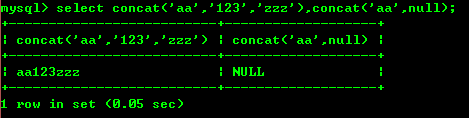
8.1: concat
cancat 関数: 受信パラメータを string に連結します。以下に示すように、任意の文字列を null と連結した結果は null になります
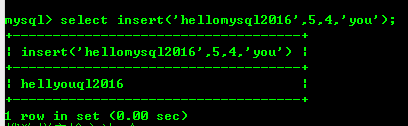
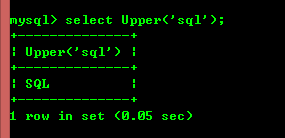
8.2: insert(str,x,y, instr) 関数、replace Lower(Str) および Upper(Str) で始まる文字列 str は、文字列を小文字または大文字に変換します。
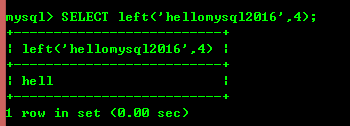
8.4: left(str,x) と right(str,x) は、それぞれ文字列の左端の x 文字と右端の x 文字を返します。2 番目のパラメーターが null の場合、文字は返されません。
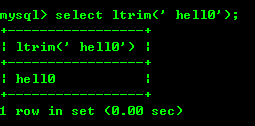
 8.5: ltrim(str) と rtrim(str) は文字列の左側または右側の文字を削除します
8.5: ltrim(str) と rtrim(str) は文字列の左側または右側の文字を削除します
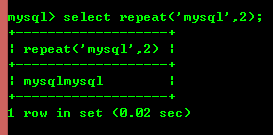
 8.6:repeat(str,x):str を x 回繰り返した結果を返します
8.6:repeat(str,x):str を x 回繰り返した結果を返します
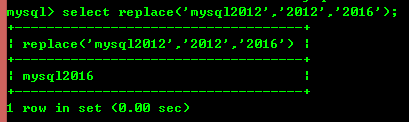
 8.7: replace(str, a, b) は、文字列 str 内の文字列 a をすべて文字列 b に置き換えます。
8.7: replace(str, a, b) は、文字列 str 内の文字列 a をすべて文字列 b に置き換えます。
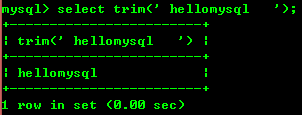
 8.8: Trim(str) は先頭と末尾のスペースを削除します
8.8: Trim(str) は先頭と末尾のスペースを削除します
 8.9: substring(str,x,y): 文字列 str String の x 番目の位置から始まる y 文字列の長さを返します。
8.9: substring(str,x,y): 文字列 str String の x 番目の位置から始まる y 文字列の長さを返します。
以上がMySQLの基礎知識を詳しく紹介(写真)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。