
ホームページ >データベース >mysql チュートリアル >MySQL クエリのパフォーマンス最適化の詳細な紹介
MySQL クエリのパフォーマンス最適化の詳細な紹介

- 黄舟オリジナル
- 2017-03-15 17:22:101214ブラウズ
高性能データベースの場合: データベーステーブル構造の最適化、index最適化、query最適化を連携して行う必要があります
1. クエリ速度が遅いのはなぜですか?
クエリは実際には一連のサブタスクで構成されており、クエリの最適化とは、実際には、いくつかのサブタスクを削除するか、実行されるサブタスクの数を減らすことを意味します。
2. 遅いクエリの基本: データアクセスの最適化
(1) データベースに不要なデータが要求されているかどうか
1) 不要なデータがクエリされる:
例えば、select を通じて大量のデータをクエリします。その結果、最初の N 行を取得した後に結果セットが閉じられます。実際、クライアントはデータの一部を受信した後、残りのデータを破棄します。したがって、limit キーワード limit を使用して、前の n レコードをクエリするだけで済みます。 2) 複数のテーブルが関連付けられている場合は、すべての列を返します
mysql>select * from ……が頻繁に発生します
このようなクエリは実際にはパフォーマンスに非常に影響するため、特定のクエリを使用する必要があります フィールド名
ワイルドカード
* の代わりに使用されます 3) 常にすべての列を削除します
クエリが必要なデータのみを返すことを確認した後 (つまり、カスタマイズされたクエリの特定のフィールドで * ワイルドカードを使用しないでください)
次に注目すべきことは次のとおりです。返された結果 スキャンされたデータが多すぎるかどうか。 MySQL の 3 つの最も単純なメトリクスは次のとおりです:
(1) 応答時間
(2) スキャンされた行数
(3) 返された行数。
応答時間 応答時間: サービス時間 (実際のクエリ時間) とキュー時間 (ブロック待機時間) が含まれます。
クエリを分析する場合、クエリによってスキャンされた行数を表示すると、クエリが効率的かどうかをある程度示すことができ、非常に役立ちます。
MySQL には、結果の行を検索して返すためのいくつかのアクセス方法があります: フルテーブルスキャン、インデックススキャン、範囲スキャン、一意のインデックスクエリ、定数参照など。
インデックスを追加する役割はここで明らかになります。インデックスにより、MySQL はスキャンされる行数を最小限に抑えた最も効率的な方法でレコードを検索できるようになります。
目的は、実際に必要な結果を取得するためのより最適な方法を見つけることです。
(1) 1 つの複雑なクエリまたは複数の単純なクエリ SQL を記述するときによく考慮する必要がある質問は、「複雑なクエリを複数の単純なクエリに分割する必要があるか?」ということです。
MySQL の場合、接続と切断は非常に軽量であり、小さなクエリ結果を返す際に非常に効率的です。クエリの数はできるだけ少ないことが望ましいですが、ワークロードが大幅に軽減されるかどうかを測定した後、大きなクエリをより小さなクエリに分割することが必要になる場合があります。
分割統治の考え方。場合によっては、大量のデータが長時間ロックされるのを避けるために、大規模なクエリをいくつかの部分に分割し、部分的に実行し、ステップ間に遅延を設定する必要があります。
たとえば、データを削除する場合、削除する必要があるすべてのデータを一度に削除すると、トランザクションが長時間占有される可能性がありますが、条件付きで大規模な削除を複数の削除実行に分割して実行できます。制限をなくすことで、効率を向上させることができます。
多くの高パフォーマンスのアプリケーションは、関連するクエリを分割します。例:
mysql>select * from tag left join tag_post on tag_post.tag_id=tag.id left join post on tag_post.post_id = post.idwhere tag.tag='mysql';
は
mysql>select * from tag where tag='mysql';mysql>select * from tag_post where tag_id=1234; mysql>select * from post where post.id in (123,345,456,8933);
に分解できます。そのような分解の理由は何ですか?
(1)キャッシュ
をより効率的にします (たとえば、上記でクエリされたタグがキャッシュされている場合、アプリケーションは最初のクエリをスキップできます)。 (2) クエリを分解した後、単一のクエリを実行します。 ロックを減らすことができます。論争。
(3) 場合によっては、上記の分解後に in キーワード クエリを使用する方が効率的です。
4. クエリ実行の基礎
まず、クエリ実行パスの概略図を見てみましょう: 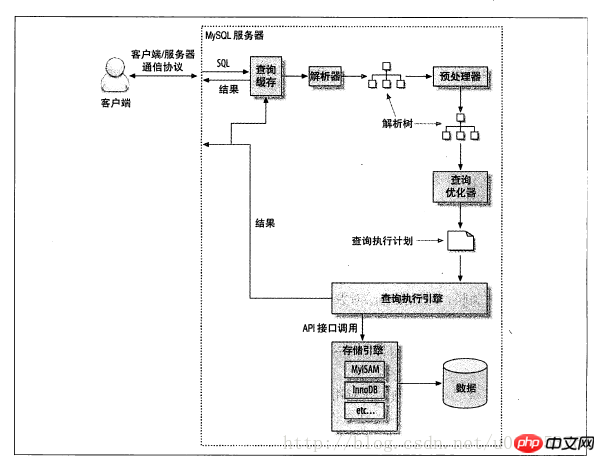
手順は次のとおりです:
(1) クライアントがサーバーにクエリを送信します。 ;
(2) サーバーは最初にクエリ キャッシュをチェックし、キャッシュがヒットした場合はキャッシュに保存されている結果がすぐに返され、そうでない場合は次のステップに進みます。
(3) サーバーは SQL を解析して前処理し、その後オプティマイザーが対応する実行プランを生成します。
(4) MySQL は、オプティマイザーによって生成された実行プランに基づいてクエリを実行し、ストレージ エンジンの API を呼び出します。
(5) 結果をクライアントに返します。
(1) MySQL クライアント/サーバー通信プロトコル
通信プロトコルが内部でどのように実装されているかを理解する必要はありません。通信プロトコルがどのように機能するかを理解することだけが必要です。
MySQL のクライアントとサーバーの通信プロトコルは半二重です。これは、一方の当事者だけが同時に他方の当事者にデータを送信できることを意味します。
(2) クエリキャッシュ
SQL ステートメントを解析する前に、キャッシュがオンになっている場合、MySQL はクエリがクエリ キャッシュ内のデータにヒットするかどうかを優先的にチェックします。キャッシュがヒットすると、結果セットがキャッシュから直接取得され、クライアントに返されます。キャッシュがヒットしなかった場合は、次の段階に進みます。
(3) クエリ オプティマイザー
この部分で最も重要なのは、クエリ ステートメントはさまざまな方法で実行でき、最終的には同じ結果が返されます。最も効率的な実行計画を見つけるために。
MySQL クエリ オプティマイザーが自動的に処理できる最適化タイプは次のとおりです:
(1) アソシエーション テーブルの順序を再定義します。データ テーブルのアソシエーション順序は、クエリで指定された順序とは限りません。これはオプティマイザに関係します。(2) 外部結合を 内部結合 に変換します。
(3) 同等の変換ルールを使用します。一部の比較を減らしたり、一部の同一性判断を削除したりできます。たとえば、(5=5 および a>5) は (a>5) と書き換えられます。
(4) COUNT()、MIN()、および MAX() 関数の最適化: インデックスと列を空にすることが許可されているかどうかは、このタイプの式の最適化に役立ちます。たとえば、最小値を見つけるには、B-ツリー構造の特徴は、B -Tree の左端のレコードをクエリするだけでOKです。 max() 関数を見つける場合にも同じことが当てはまります。ただし、COUNT(*) 関数の場合、MyISAM ストレージ タイプは、テーブル内のレコード行の合計数を具体的に格納するための 変数 を維持します。
(5) カバード インデックス スキャン: インデックス内の列にクエリで使用する必要があるすべての列が含まれている場合、MySQL は対応するデータ行をクエリすることなく、インデックスを直接使用して必要なデータを返すことができます。
(6) サブクエリの最適化
(8) クエリを早期に終了: MySQL は、クエリ要件が満たされたと判断した場合、常にクエリを直ちに終了できます。たとえば、キーワードを制限します。
(9) OR ではなく IN リストの比較: MySQL はまず IN ステートメント内のデータをソートし、次に 二分検索 を使用してリスト内のデータが要件を満たしているかどうかを判断します。これは O( の複雑さです。ログオン)操作します。 等価的にORに変換するとO(n)時間になります。
(4) 並べ替えの最適化
いずれにしても、並べ替えは非常にコストのかかる操作であり、ビッグデータの並べ替えは避けなければなりません。したがって、ソートにはインデックス列を使用する必要があります。インデックスを使用してソート結果を生成できない場合、データ量が膨大になるため、テーブルに戻ってレコードをクエリする必要があります。使用されます。
以上がMySQL クエリのパフォーマンス最適化の詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。