
ホームページ >ウェブフロントエンド >jsチュートリアル >誰もが知っているJavaScriptの正規表現を詳しく解説
誰もが知っているJavaScriptの正規表現を詳しく解説

- 黄舟オリジナル
- 2017-03-14 15:06:351329ブラウズ
これが 正規式 についての概要である場合、私はそれをマニュアルとして考えることを好みます。
RegExp の 3 つの主要なメソッド
この記事の RegExp では、直接数量構文: /pattern/attributes を使用します。属性には i、m、g の 3 つのオプションがあります。m (複数行のマッチング) は一般的に使用されず、直接省略できるため、パターン (マッチング パターン) は次のように表現できます:
var pattern = /hello/ig;
i (無視)は、大文字と小文字を区別しない (地面 検索 マッチング) を意味し、次の例では説明しません。 g (グローバル) は、グローバル (検索マッチング) を意味します。つまり、比較的複雑です。以下の方法で特別に紹介します。
これらは RegExp の 3 つの主要なメソッドであるため、すべて pattern.test/exec/complie の形式になります。
test
Main関数: 指定されたstringに特定の部分文字列(または一致するパターン)が含まれているかどうかを検出し、trueまたはfalseを返します。
例は次のとおりです:
var s = 'you love me and I love you'; var pattern = /you/; var ans = pattern.test(s); console.log(ans); // true
属性で g が使用されている場合、検索を続行できます。これには lastIndexattribute も含まれます (exec での g の導入を参照)。
exec
主な関数: 指定された文字列内の必要な部分文字列 (または一致するパターン) を抽出し、一致する結果を格納する array を返します。そうでない場合は、null を返します。 (独自のメソッドloopを記述して、すべてまたは指定したインデックスデータを抽出することもできます)
exec は、検出するだけでなく、検出後の結果を直接抽出することもできるため、テストのアップグレード版と言えます。
例は次のとおりです:
var s = 'you love me and I love you'; var pattern = /you/; var ans = pattern.exec(s); console.log(ans); // ["you", index: 0, input: "you love me and I love you"] console.log(ans.index); // 0 console.log(ans.input); // you love me and I love you
出力は非常に興味深いものです。この配列の 0 番目の要素は正規表現に一致するテキスト、1 番目の要素は RegExpObject の 1 番目の部分表現 (存在する場合) に一致するテキスト、2 番目の要素は正規表現に一致するテキストです。 RegExpObject の 2 番目の部分式 (存在する場合) などと一致します。
「部分式に一致するテキスト」とは何ですか?以下の例を見てください:
var s = 'you love me and I love you'; var pattern = /y(o?)u/; var ans = pattern.exec(s); console.log(ans); // ["you", "o", index: 0, input: "you love me and I love you"] console.log(ans.length) // 2
いわゆる部分式は、パターンの () 内にあるものです (詳細については、以下の部分式の概要を参照してください)。上の例の配列の長さを見ると、それは 2 です。 ! Index と input は単なる配列属性です (上記の chrome の出力は誤解を招く可能性があります)。
配列要素と長さのプロパティに加えて、exec() メソッドは 2 つのプロパティも返します。 Index 属性は、一致したテキストの最初の文字の位置を宣言します。 input 属性には、取得した文字列 string が格納されます。 非グローバル RegExp オブジェクトの exec() メソッドを呼び出した場合、返される配列は、メソッド String.match() を呼び出して返される配列と同じであることがわかります。
「g」パラメータを使用する場合、exec() は次のように動作します (上記の例は同じです ps: test で g パラメータを使用する場合も同様です):
-
最初の「you」を見つけてその位置を保存します
-
再度 exec() を実行すると、保存された位置 (lastIndex) から検索を開始し、次の「あなた」を見つけてその位置を保存します
RegExpObject がグローバル正規表現の場合、exec() の 動作 はもう少し複雑です。 RegExpObject の lastIndex プロパティで指定された文字から文字列 string の取得を開始します。 exec() は、式に一致するテキストを見つけると、一致した後、RegExpObject の lastIndex プロパティを、一致するテキストの最後の文字の隣の位置に設定します。これは、 exec() メソッドを繰り返し呼び出すことで、文字列内の一致するすべてのテキストを反復処理できることを意味します。 exec() は一致するテキストが見つからなくなると、null を返し、lastIndex プロパティを 0 にリセットします。ここでは lastIndex 属性が導入されていますが、これは g と test (または g と exec) と組み合わせた場合にのみ機能します。これはパターンの属性、整数で、次のマッチングが始まる文字位置を示します。
例は次のとおりです。
var s = 'you love me and I love you';
var pattern = /you/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
console.log(pattern.lastIndex);
}
while (ans !== null)結果は次のとおりです。

3 回目のループでは、「you」が見つからないため、null が返され、 lastIndex の値が 0 になります。
如果在一个字符串中完成了一次模式匹配之后要开始检索新的字符串(仍然使用旧的pattern),就必须手动地把 lastIndex 属性重置为 0。
compile
主要功能:改变当前匹配模式(pattern)
这货是改变匹配模式时用的,用处不大,略过。详见JavaScript compile() 方法
String 四大护法
和RegExp三大方法分庭抗礼的是String的四大护法,四大护法有些和RegExp三大方法类似,有的更胜一筹。
既然是String家族下的四大护法,所以肯定是string在前,即str.search/match/replace/split形式。
既然是String的方法,当然参数可以只用字符串而不用pattern。
search
主要功能:搜索指定字符串中是否含有某子串(或者匹配模式),如有,返回子串在原串中的初始位置,如没有,返回-1。
是不是和test类似呢?test只能判断有木有,search还能返回位置!当然test()如果有需要能继续找下去,而search则会自动忽略g(如果有的话)。实例如下:
var s = 'you love me and I love you'; var pattern = /you/; var ans = s.search(pattern); console.log(ans); // 0
话说和String的indexOf方法有点相似,不同的是indexOf方法可以从指定位置开始查找,但是不支持正则。
match
主要功能:和exec类似,从指定字符串中查找子串或者匹配模式,找到返回数组,没找到返回null
match是exec的轻量版,当不使用全局模式匹配时,match和exec返回结果一致;当使用全局模式匹配时,match直接返回一个字符串数组,获得的信息远没有exec多,但是使用方式简单。
实例如下:
var s = 'you love me and I love you'; console.log(s.match(/you/)); // ["you", index: 0, input: "you love me and I love you"] console.log(s.match(/you/g)); // ["you", "you"]
replace
主要功能:用另一个子串替换指定字符串中的某子串(或者匹配模式),返回替换后的新的字符串 str.replace(‘搜索模式’,'替换的内容’) 如果用的是pattern并且带g,则全部替换;否则替换第一处。
实例如下:
var s = 'you love me and I love you'; console.log(s.replace('you', 'zichi')); // zichi love me and I love you console.log(s.replace(/you/, 'zichi')); // zichi love me and I love you console.log(s.replace(/you/g, 'zichi')); // zichi love me and I love zichi
如果需要替代的内容不是指定的字符串,而是跟匹配模式或者原字符串有关,那么就要用到$了(记住这些和$符号有关的东东只和replace有关哦)。

怎么用?看个例子就明白了。
var s = 'I love you'; var pattern = /love/; var ans = s.replace(pattern, '$`' + '$&' + "$'"); console.log(ans); // I I love you you
没错,’$`’ + ‘$&’ + “$’”其实就相当于原串了!
replace的第二个参数还能是函数,看具体例子前先看一段介绍:
注意:第一个参数是匹配到的子串,接下去是子表达式匹配的值,如果要用子表达式参数,则必须要有第一个参数(表示匹配到的串),也就是说,如果要用第n个参数代表的值,则左边参数都必须写出来。最后两个参数跟exec后返回的数组的两个属性差不多。
var s = 'I love you';
var pattern = /love/;
var ans = s.replace(pattern, function(a) { // 只有一个参数,默认为匹配到的串(如还有参数,则按序表示子表达式和其他两个参数)
return a.toUpperCase();
});
console.log(ans); // I LOVE yousplit
主要功能:分割字符串
字符串分割成字符串数组的方法(另有数组变成字符串的join方法)。直接看以下例子:
var s = 'you love me and I love you'; var pattern = 'and'; var ans = s.split(pattern); console.log(ans); // ["you love me ", " I love you"]
如果你嫌得到的数组会过于庞大,也可以自己定义数组大小,加个参数即可:
var s = 'you love me and I love you'; var pattern = /and/; var ans = s.split(pattern, 1); console.log(ans); // ["you love me "]
RegExp 字符
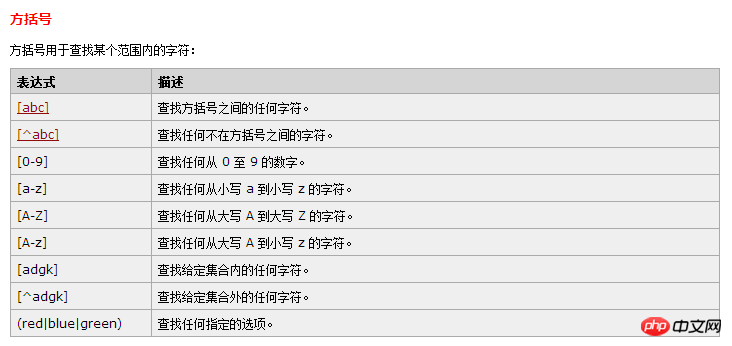
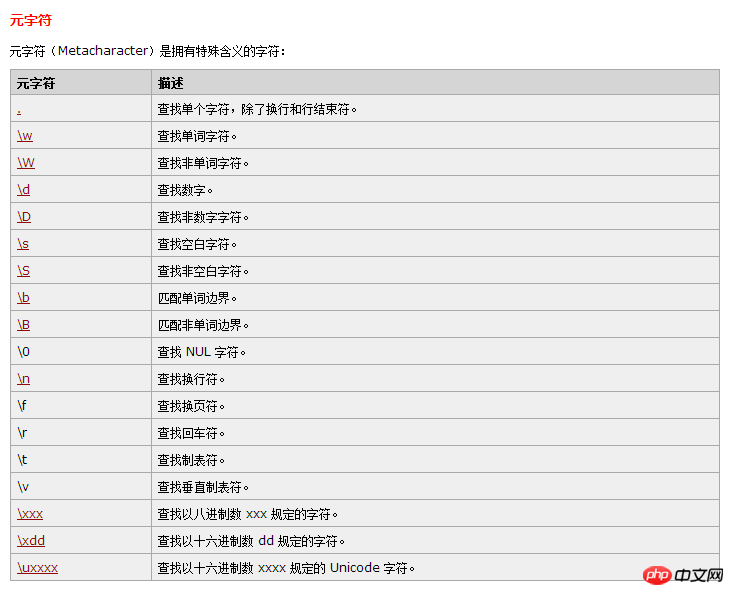
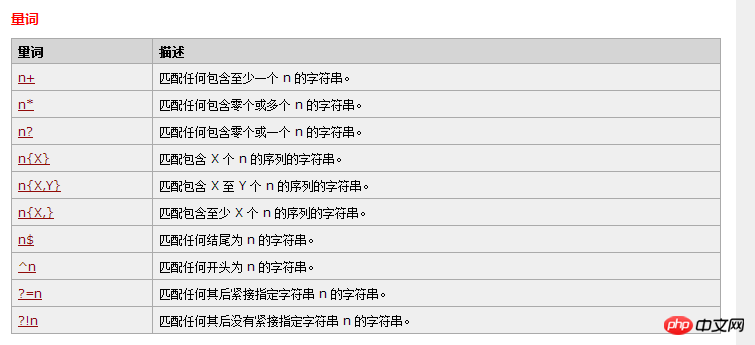
\s 任意空白字符 \S相反 空白字符可以是: 空格符 (space character) 制表符 (tab character) 回车符 (carriage return character) 换行符 (new line character) 垂直换行符 (vertical tab character) 换页符 (form feed character)
\b是正则表达式规定的一个特殊代码,代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。(和^ $ 以及零宽断言类似)
\w 匹配字母或数字或下划线 [a-z0-9A-Z_]完全等同于\w
贪婪匹配和懒惰匹配
什么是贪婪匹配?贪婪匹配就是在正则表达式的匹配过程中,默认会使得匹配长度越大越好。
var s = 'hello world welcome to my world'; var pattern = /hello.*world/; var ans = pattern.exec(s); console.log(ans) // ["hello world welcome to my world", index: 0, input: "hello world welcome to my world"]
以上例子不会匹配最前面的Hello World,而是一直贪心的往后匹配。
那么我需要最短的匹配怎么办?很简单,加个‘?’即可,这就是传说中的懒惰匹配,即匹配到了,就不往后找了。
var s = 'hello world welcome to my world'; var pattern = /hello.*?world/; var ans = pattern.exec(s); console.log(ans) // ["hello world", index: 0, input: "hello world welcome to my world"]
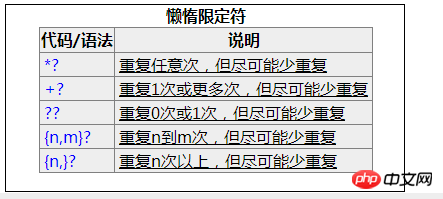
懒惰限定符(?)添加的场景如下:
子表达式
表示方式
用一个小括号指定:
var s = 'hello world'; var pattern = /(hello)/; var ans = pattern.exec(s); console.log(ans);
子表达式出现场景
在exec中数组输出子表达式所匹配的值:
var s = 'hello world'; var pattern = /(h(e)llo)/; var ans = pattern.exec(s); console.log(ans); // ["hello", "hello", "e", index: 0, input: "hello world"]
在replace中作为替换值引用:
var s = 'hello world'; var pattern = /(h\w*o)\s*(w\w*d)/; var ans = s.replace(pattern, '$2 $1') console.log(ans); // world hello
后向引用 & 零宽断言
子表达式的序号问题
简单地说:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
复杂地说:分组0对应整个正则表达式实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号。可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
后向引用
如果我们要找连续两个一样的字符,比如要找两个连续的c,可以这样/c{2}/,如果要找两个连续的单词hello,可以这样/(hello){2}/,但是要在一个字符串中找连续两个相同的任意单词呢,比如一个字符串hellohellochinaworldworld,我要找的是hello和world,怎么找?
这时候就要用后向引用。看具体例子:
var s = 'hellohellochinaworldworld'; var pattern = /(\w+)\1/g; var a = s.match(pattern); console.log(a); // ["hellohello", "worldworld"]
这里的\1就表示和匹配模式中的第一个子表达式(分组)一样的内容,\2表示和第二个子表达式(如果有的话)一样的内容,\3 \4 以此类推。(也可以自己命名,详见参考文献)
或许你觉得数组里两个hello两个world太多了,我只要一个就够了,就又要用到子表达式了。因为match方法里是不能引用子表达式的值的,我们回顾下哪些方法是可以的?没错,exec和replace是可以的!
exec方式:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
} while(ans !== null);
// result
// ["hellohello", "hello", index: 0, input: "hellohellochinaworldworld"] index.html:69
// ["worldworld", "world", index: 15, input: "hellohellochinaworldworld"] index.html:69
// null如果输出只要hello和world,console.log(ans[1])即可。
replace方式:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans = [];
s.replace(pattern, function(a, b) {
ans.push(b);
});
console.log(ans); // ["hello", "world"]如果要找连续n个相同的串,比如说要找出一个字符串中出现最多的字符:
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9如果需要引用某个子表达式(分组),请认准后向引用!
零宽断言
别被名词吓坏了,其实解释很简单。
它们用于查找在某些内容(但并不包括这些内容)之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言)
(?=exp)
零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
// 获取字符串中以ing结尾的单词的前半部分 var s = 'I love dancing but he likes singing'; var pattern = /\b\w+(?=ing\b)/g; var ans = s.match(pattern); console.log(ans); // ["danc", "sing"]
(?!exp)
零宽度负预测先行断言,断言此位置的后面不能匹配表达式exp
// 获取第五位不是i的单词的前四位
var s = 'I love dancing but he likes singing';
var pattern = /\b\w{4}(?!i)/g;
var ans = s.match(pattern);
console.log(ans); // ["love", "like"]javascript正则只支持前瞻,不支持后瞻((?<=exp)和(?
关于零宽断言的具体应用可以参考综合应用一节给字符串加千分符。
其他
字符转义
因为某些字符已经被正则表达式用掉了,比如. * ( ) / \ [],所以需要使用它们(作为字符)时,需要用\转义
var s = 'http://www.cnblogs.com/zichi/'; var pattern = /http:\/\/www\.cnblogs\.com\/zichi\//; var ans = pattern.exec(s); console.log(ans); // ["http://www.cnblogs.com/zichi/", index: 0, input: "http://www.cnblogs.com/zichi/"]
分支条件
如果需要匹配abc里的任意字母,可以用[abc],但是如果不是单个字母那么简单,就要用到分支条件。
分支条件很简单,就是用|表示符合其中任意一种规则。
var s = "I don't like you but I love you"; var pattern = /I.*(like|love).*you/g; var ans = s.match(pattern); console.log(ans); // ["I don't like you but I love you"]
答案执行了贪婪匹配,如果需要懒惰匹配,则:
var s = "I don't like you but I love you"; var pattern = /I.*?(like|love).*?you/g; var ans = s.match(pattern); console.log(ans); // ["I don't like you", "I love you"]
综合应用
去除字符串首尾空格(replace)
String.prototype.trim = function() {
return this.replace(/(^\s*)|(\s*$)/g, "");
};
var s = ' hello world ';
var ans = s.trim();
console.log(ans.length); // 12给字符串加千分符(零宽断言)
String.prototype.getAns = function() {
var pattern = /(?=((?!\b)\d{3})+$)/g;
return this.replace(pattern, ',');
}
var s = '123456789';
console.log(s.getAns()); // 123,456,789找出字符串中出现最多的字符(后向引用)
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9常用匹配模式(持续更新)
只能输入汉字:/^[\u4e00-\u9fa5]{0,}$/
概要
テスト: 指定された文字列に特定の部分文字列 (または一致するパターン) があるかどうかを確認し、必要に応じて true または false を返し、グローバル パターン検索を実行できます。
exec: 指定された文字列に特定の部分文字列 (または一致するパターン) があるかどうかを確認し、存在する場合は配列を返します (配列には情報が豊富です。ない場合は、上記の概要を参照してください)。グローバル検索では、すべての部分文字列 (または一致するパターン) の情報が検索され、その情報には、一致するパターン内の部分式に対応する文字列が含まれます。
- compile
: 正規表現のパターンを変更します。
- search
: 指定された文字列に特定の部分文字列 (または一致するパターン) があるかどうかを確認し、存在する場合は部分文字列 (または一致するパターン) を返します。 pattern) オリジナルの文字列内の開始位置。そうでない場合は、-1 が返されます。グローバル検索はできません。
- match
: 指定された文字列に特定の部分文字列 (または一致するパターン) があるかどうかを確認します。グローバル検索が実行される場合、非グローバル モードで返される情報は exec と一致します。直接。 (各一致に関する詳細情報が必要ない場合は、exec の代わりに match を使用することをお勧めします)
- replace
: 指定された文字列に特定の部分文字列 (または一致するパターン) があるかどうかを確認し、それを置換します。別の部分文字列と (部分文字列は元の文字列または検索された部分文字列に関連付けることができます)、g が有効な場合はグローバルに置換され、それ以外の場合は最初の部分文字列のみが置換されます。 replace メソッドは部分式に対応する値を参照できます。
- split
- 部分式
: かっこで囲まれた正規一致式。後方参照で参照でき、実際の一致値を取得するために exec または replace で使用することもできます。
- 後方参照
: 部分式が配置されているグループを参照します。
- ゼロ幅アサーション
: b ^ と $ に似た位置概念。
以上が誰もが知っているJavaScriptの正規表現を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。