
ホームページ >データベース >mysql チュートリアル >MySQL 分散クラスターの MyCAT ルールの詳細分析 (3) (写真とテキスト)
MySQL 分散クラスターの MyCAT ルールの詳細分析 (3) (写真とテキスト)

- 黄舟オリジナル
- 2017-03-11 14:22:131622ブラウズ
S sは以前にSCHEMAの役割を紹介しました〜
まず、このファイルでは、シャードのさまざまなルールを定式化します。使用率は、まず設定ファイルの内容を読み取ることです
、ここでチーフエンジニアは次の4つの切断方法を紹介します〜つぶやきは騙されました〜 ------------- ------------------------ ---------------------------- ------------------------ ----------ハッシュ整数 -------- ------------------------ ---------------------------- ------------------------
------------- ------------------------ ---------------------------- ------------------------ ----------ハッシュ整数 -------- ------------------------ ---------------------------- ------------------------
ハッシュ最初 -int を見ると、このセグメンテーション ルールの下にマップファイルがあります。つまり、このセグメンテーション ルールは、partition-hash-int の内容に基づいて決定されます。次に、このテキスト ファイルを見てください
非常に単純な内容です。これは、セグメンテーションに使用されるベース列で、値が 10000 の場合は最初の DN (dn1) に配置され、値が 10010 の場合は 2 番目の DN (dn2) に配置されます結果 実際の効果を確認してください。ここに(掘削機が転がる〜) 挿入されたデータがこのファイルに記載されている値と異なります。的当当 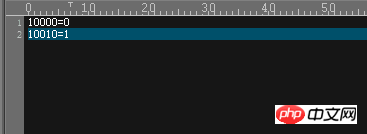

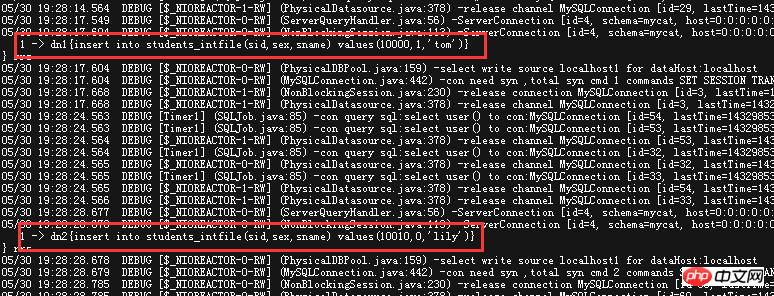
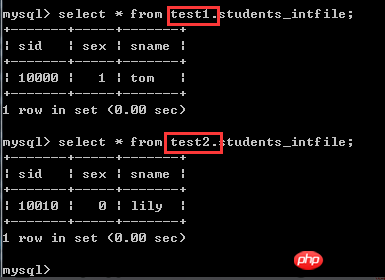
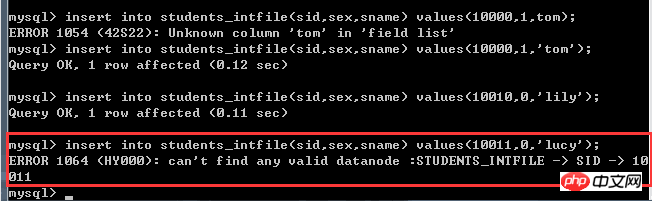
🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 この分割ルールは一般的に 🎜🎜 枚として理解できます🎜🎜 🎜🎜、固定値の方が適しています。 、性別(0,1)、都道府県(固定値、日本の都道府県は短期間では回復しません~)、チャンネルプロバイダーなど
またはさまざまなプラットフォームのID🎜🎜また、通勤分離を使用して複数の値をパーティションに配置すると、実際のデータ/フロー/アクセス量に応じて包括的に分割戦略を策定できます。)╭
----- -------------------------------------- ------- ---------------------------------------射程 -長い---- -------------------------------------------- ------ ----------------------------
2 番目の分割方法、range-long は、よく見ると hash-int と似ています。セグメンテーション戦略も特定のファイルによって決定されるため、ファイルの内容から、これが範囲セグメンテーションの値を確立する方法であることがわかります。この方法は基本的に hash-int と同じなので、スクリーンショットは撮りません (怠惰な癌の末期、時間が足りません!) この種のセグメント化戦略は、ビジネス データベースでの使用シナリオが少なくなるのではないかと個人的に感じています。このセグメント化方法では、あらかじめ決められた全体量が必要であり、無限に増加するデータに使用できないことが判明するためです。この分割戦略を変更するのは非常に面倒なので、主キーを自動増加させて一定の数に応じて均等に分割するようなビジネスにのみ使用できるように感じます。次に、事前に複数の DN (ライブラリ) を構築します。もちろん、短期間に大量の注文がある場合、各 DN (分岐) セットの数が比較的多くなる (たとえば、DN セット 1000W バー配置 1000W バー設定 1000W) という潜在的な問題もあります。バー設定 1000W バー設定 1000W バー設定 1000W ストリップ データ )、この時点で、非常に高い IO プレッシャーを持つ特定の DN (サブデータベース) が存在し、他のいくつかの DN (サブデータベース) には IO 操作がありません。これは、DB で一般的な熱の発生と同様の
を引き起こし、MySQL は自動インクリメント主キーを使用することが多いため、MySQL テーブルに多数の「シーケンシャル」挿入が行われる機会がさらに多くなります。 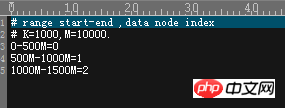 。
。
------------------------------------------------ -------------------------------------------------- mod-long--- -------------------------------------------- ------ -----------------------------
.これを見る具体的な設定情報を見てみましょう Count & lt; dn の数は問題ありません) 実際の効果を見てみましょう mycat のデバッグログを見てみましょうMYCAT がどのように DN (ライブラリ) に処理されるかを確認すると、連続して挿入すると、データが複数の DN (ライブラリ) に均等に分散されることがわかります。上記の範囲方法と比較すると、このセグメント化戦略はデータベース書き込みの負荷をより分散します。しかし、問題も明らかです。 データ量が増加すると、MyCAT は結果をマージする必要があります。この種のデータベース間のクエリとマージされた結果によって消費される時間は、特に順序付けが発生した場合に大幅に増加する可能性があります。
による。したがって、この種のカットアウト戦略は、単一ポイントのクエリ シーンにより適しています 、たとえば...わかりません...本当にわかりません。おそらく銀行で、個人口座情報を確認してください。場合によっては、ユーザー情報を含む一部のテーブルを冗長化し、この方法を使用してより効率的なクエリを提供することができます (結局のところ、銀行には多数のユーザーがいるのですからね~)
------ -------------------------------------------------- -----------------------長さによるパーティション----------- -------------------------------------------------- ---------- レンジ-ロング間のわずかに妥協したパーティショニング戦略および mod-long の場合、具体的なパーティショニング状況は以下のとおりです:
1024 をユニットごとに、DN2 の DN1,256-511 に、partitionLength データの数と、partitionCount %1024 = 0-255 を格納し、オフセット値として 128 を使用して 8 つのデータを挿入してみます。mycat のログを直接見てください。これら 4 つの DN に均等に分散されます~この分割戦略は不均一な分布もサポートしています ~ 2 つの図は基本的に、この不均一な分布の分割戦略を示していますが、依然として 2x256+1x512=1024~ に焦点が当てられています。
この分割戦略には 1 つの要素が必要ですrange-long と mod-long の間。同時に、妥協点は比較的柔軟で、さまざまな状況に応じて不均一に分割できます。実際には、もう少し多くのシナリオやその他のシナリオに適用できます。つまり、多くのシナリオで使用でき、クロスオーバーが比較的減少します。DN の場合、データは比較的均等に分割されるため、シングルポイント クエリはそれほど遅くなりません。 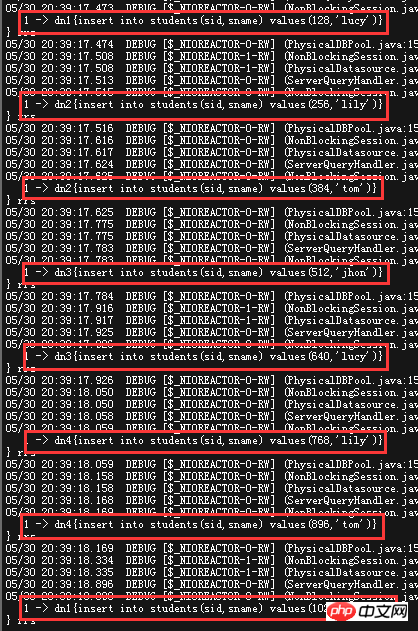
 ------------------------------------------ ----- -------------------------------------- 最後に書きます------ -------------------------------------------- ------ ----------------------------
------------------------------------------ ----- -------------------------------------- 最後に書きます------ -------------------------------------------- ------ ----------------------------
実際、MyCAT は次のような多くのセグメンテーション方法をサポートしています。セグメント化戦略は、月、日などで分けることができます。すべての戦略をここにまとめるのは不可能です、申し訳ありませんo( ̄ヘ ̄o#)実際、個人的な観点からは、時間はありませんデータベース自体のパーティショニング戦略に従って分割する際の問題は、半期および四半期のデータを引き続きクエリする必要があります...PS: _(:з ∠)_私は本当に怠け者ではありません... それは可能です。基本的には、MyCAT のデータベースとテーブルの分割のポイントがこのルールに反映されており、テーブルを分割するかどうか、テーブル データをどのように分割するかは、実際のビジネスに基づいて決定する必要があります。ビジネスの特徴について〜
以上がMySQL 分散クラスターの MyCAT ルールの詳細分析 (3) (写真とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。