


私はコンパイラーとパーサーに常に非常に興味を持っていますが、コンパイラーの概念と全体的なフレームワークについてはよく理解していますが、詳細についてはあまり知りません。私たちが書くプログラムのソースコードは、実際には文字列です。コンパイラやインタプリタは、この文字列を直接理解して実行できます。この記事では、Python を使用して、(Python のリストに似た) 小さなリスト操作言語を解釈するための単純なパーサーを実装します。実際、コンパイラとインタプリタは、基本理論を理解していれば、それほど神秘的なものではありません (もちろん、製品レベルのコンパイラやインタプリタは依然として非常に複雑です)。
このリスト言語でサポートされている操作:
対応する出力:
コンパイラとインタプリタが入力文字ストリームを処理するとき、それらは基本的に人間が文章を理解する方法と一致します。例:
英語の学習が初めての場合は、まず各単語の意味を知り、次に各単語の品詞を分析して主語-述語-目的語の構造に一致させ、その意味を理解する必要があります。文。この文は文字列であり、字句分割により字句単位ストリームが得られ、これによって文字ストリームから字句単位ストリームへの変換が完了する。品詞を分析し、主語・動詞・目的語の構造を特定するのが英語の文法に基づくものであり、入力された語彙単位の流れに基づいて文法解析木が特定されます。最後に、単語の意味と文法構造を組み合わせて、最終的に文の意味を取得します。コンパイラーとインタープリターの処理プロセスは似ていますが、ここではインタープリターのみに焦点を当てます。
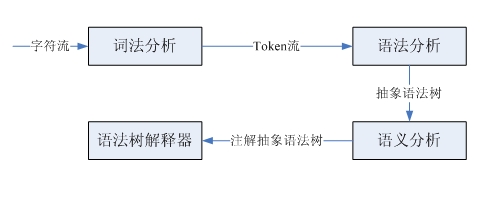
字句解析と構文解析は、それぞれ字句パーサーと構文パーサーによって実行されます。これら 2 つのパーサーは同様の構造と機能を持ち、どちらも入力シーケンスを入力として受け取り、特定の構造を識別します。字句パーサーはソース コードの文字ストリームからトークン (字句単位) を 1 つずつ解析し、構文パーサーは部分構造と字句単位を識別して何らかの処理を実行します。どちらのパーサーも、LL(1) 再帰降下パーサーによって実装できます。このタイプのパーサーによって実行されるステップは、句の型を予測し、部分構造を照合する解析関数を呼び出し、字句単位を照合してから、コードを挿入することです。必要なカスタムアクションを実行します。
ここでは LL(1) について簡単に説明します。ステートメントの構造は通常、解析ツリーと呼ばれるツリー構造で表されます。LL(1) は構文解析に解析ツリーを使用します。例: x = x +2;
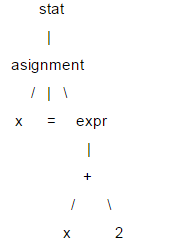 このツリーでは、x、=、2 などの葉ノードを終端ノードと呼び、それ以外を非終端ノードと呼びます。 LL(1) を解析する場合、特定のツリー データ構造を作成する必要はありません。このようにして、非終端ノードごとに解析関数を作成し、対応するノードが見つかったときにそれを呼び出すことができます。呼び出しシーケンスで関数を使用して (ツリー トラバーサルと同等)、解析ツリー情報を取得します。 LL(1) を解析する場合、ルート ノードからリーフ ノードの順序で実行されるため、これは「降順」の処理であり、解析関数は自分自身を呼び出すことができるため「再帰的」であるため、LL( 1) は再帰降下パーサーとも呼ばれます。
このツリーでは、x、=、2 などの葉ノードを終端ノードと呼び、それ以外を非終端ノードと呼びます。 LL(1) を解析する場合、特定のツリー データ構造を作成する必要はありません。このようにして、非終端ノードごとに解析関数を作成し、対応するノードが見つかったときにそれを呼び出すことができます。呼び出しシーケンスで関数を使用して (ツリー トラバーサルと同等)、解析ツリー情報を取得します。 LL(1) を解析する場合、ルート ノードからリーフ ノードの順序で実行されるため、これは「降順」の処理であり、解析関数は自分自身を呼び出すことができるため「再帰的」であるため、LL( 1) は再帰降下パーサーとも呼ばれます。
LL(1) の 2 つの L は両方とも左から右を意味します。最初の L は、パーサーが入力コンテンツを左から右の順序で解析することを意味します。左から右へ、子ノードを右に順番にたどります。1 は 1 つの先読みユニットに基づいて予測を行うことを意味します。
リストミニ言語の実装を見てみましょう。まず、言語の文法は言語を記述するために使用され、パーサーの設計仕様とみなされます。
这是用DSL描述的文法,其中大部分概念和正则表达式类似。"a|b"表示a或者b,所有以单引号括起的字符串是关键字,比如:print,=等。大写的单词是词法单元。可以看到这个小语言的文法还是很简单的。有很多解析器生成器可以自动根据文法生成对应的解析器,比如:ANTRL,flex,yacc等,这里采用手写解析器主要是为了理解解析器的原理。下面看一下这个小语言的解释器是如何实现的。
首先是词法解析器,完成字符流到token流的转换。采用LL(1)实现,所以使用1个向前看字符预测匹配的token。对于像INT、ID这样由多个字符组成的词法规则,解析器有一个与之对应的方法。由于语法解析器并不关心空白字符,所以词法解析器在遇到空白字符时直接忽略掉。每个token都有两个属性类型和值,比如整型、标识符类型等,对于整型类型它的值就是该整数。语法解析器需要根据token的类型进行预测,所以词法解析必须返回类型信息。语法解析器以iterator的方式获取token,所以词法解析器实现了next_token方法,以元组方式(type, value)返回下一个token,在没有token的情况时返回EOF。
'''''
A simple lexer of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
Created on 2012-9-26
@author: bjzllou
'''
EOF = -1
# token type
COMMA = 'COMMA'
EQUAL = 'EQUAL'
LBRACK = 'LBRACK'
RBRACK = 'RBRACK'
TIMES = 'TIMES'
ADD = 'ADD'
PRINT = 'print'
ID = 'ID'
INT = 'INT'
STR = 'STR'
class Veclexer:
'''''
LL(1) lexer.
It uses only one lookahead char to determine which is next token.
For each non-terminal token, it has a rule to handle it.
LL(1) is a quit weak parser, it isn't appropriate for the grammar which is
left-recursive or ambiguity. For example, the rule 'T: T r' is left recursive.
However, it's rather simple and has high performance, and fits simple grammar.
'''
def __init__(self, input):
self.input = input
# current index of the input stream.
self.idx = 1
# lookahead char.
self.cur_c = input[0]
def next_token(self):
while self.cur_c != EOF:
c = self.cur_c
if c.isspace():
self.consume()
elif c == '[':
self.consume()
return (LBRACK, c)
elif c == ']':
self.consume()
return (RBRACK, c)
elif c == ',':
self.consume()
return (COMMA, c)
elif c == '=':
self.consume()
return (EQUAL, c)
elif c == '*':
self.consume()
return (TIMES, c)
elif c == '+':
self.consume()
return (ADD, c)
elif c == '\'' or c == '"':
return self._string()
elif c.isdigit():
return self._int()
elif c.isalpha():
t = self._print()
return t if t else self._id()
else:
raise Exception('not support token')
return (EOF, 'EOF')
def has_next(self):
return self.cur_c != EOF
def _id(self):
n = self.cur_c
self.consume()
while self.cur_c.isalpha():
n += self.cur_c
self.consume()
return (ID, n)
def _int(self):
n = self.cur_c
self.consume()
while self.cur_c.isdigit():
n += self.cur_c
self.consume()
return (INT, int(n))
def _print(self):
n = self.input[self.idx - 1 : self.idx + 4]
if n == 'print':
self.idx += 4
self.cur_c = self.input[self.idx]
return (PRINT, n)
return None
def _string(self):
quotes_type = self.cur_c
self.consume()
s = ''
while self.cur_c != '\n' and self.cur_c != quotes_type:
s += self.cur_c
self.consume()
if self.cur_c != quotes_type:
raise Exception('string quotes is not matched. excepted %s' % quotes_type)
self.consume()
return (STR, s)
def consume(self):
if self.idx >= len(self.input):
self.cur_c = EOF
return
self.cur_c = self.input[self.idx]
self.idx += 1
if __name__ == '__main__':
exp = '''''
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
'''
lex = Veclexer(exp)
t = lex.next_token()
while t[0] != EOF:
print t
t = lex.next_token()
运行这个程序,可以得到源代码:
veca = [1, 2, 3] print 'veca:', veca print 'veca * 2:', veca * 2 print 'veca + 2:', veca + 2
对应的token序列:
('ID', 'veca')
('EQUAL', '=')
('LBRACK', '[')
('INT', 1)
('COMMA', ',')
('INT', 2)
('COMMA', ',')
('INT', 3)
('RBRACK', ']')
('print', 'print')
('STR', 'veca:')
('COMMA', ',')
('ID', 'veca')
('print', 'print')
('STR', 'veca * 2:')
('COMMA', ',')
('ID', 'veca')
('TIMES', '*')
('INT', 2)
('print', 'print')
('STR', 'veca + 2:')
('COMMA', ',')
('ID', 'veca')
('ADD', '+')
('INT', 2)
接下来看一下语法解析器的实现。语法解析器的的输入是token流,根据一个向前看词法单元预测匹配的规则。对于每个遇到的非终结符调用对应的解析函数,而终结符(token)则match掉,如果不匹配则表示有语法错误。由于都是使用的LL(1),所以和词法解析器类似, 这里不再赘述。
'''''
A simple parser of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
example:
veca = [1, 2, 3]
vecb = veca + 4 # vecb: [1, 2, 3, 4]
vecc = veca * 3 # vecc:
Created on 2012-9-26
@author: bjzllou
'''
import veclexer
class Vecparser:
'''''
LL(1) parser.
'''
def __init__(self, lexer):
self.lexer = lexer
# lookahead token. Based on the lookahead token to choose the parse option.
self.cur_token = lexer.next_token()
# similar to symbol table, here it's only used to store variables' value
self.symtab = {}
def statlist(self):
while self.lexer.has_next():
self.stat()
def stat(self):
token_type, token_val = self.cur_token
# Asignment
if token_type == veclexer.ID:
self.consume()
# For the terminal token, it only needs to match and consume.
# If it's not matched, it means that is a syntax error.
self.match(veclexer.EQUAL)
# Store the value to symbol table.
self.symtab[token_val] = self.expr()
# print statement
elif token_type == veclexer.PRINT:
self.consume()
v = str(self.expr())
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v += ' ' + str(self.expr())
print v
else:
raise Exception('not support token %s', token_type)
def expr(self):
token_type, token_val = self.cur_token
if token_type == veclexer.STR:
self.consume()
return token_val
else:
v = self.multipart()
while self.cur_token[0] == veclexer.ADD:
self.consume()
v1 = self.multipart()
if type(v1) == int:
v.append(v1)
elif type(v1) == list:
v = v + v1
return v
def multipart(self):
v = self.primary()
while self.cur_token[0] == veclexer.TIMES:
self.consume()
v1 = self.primary()
if type(v1) == int:
v = [x*v1 for x in v]
elif type(v1) == list:
v = [x*y for x in v for y in v1]
return v
def primary(self):
token_type = self.cur_token[0]
token_val = self.cur_token[1]
# int
if token_type == veclexer.INT:
self.consume()
return token_val
# variables reference
elif token_type == veclexer.ID:
self.consume()
if token_val in self.symtab:
return self.symtab[token_val]
else:
raise Exception('undefined variable %s' % token_val)
# parse list
elif token_type == veclexer.LBRACK:
self.match(veclexer.LBRACK)
v = [self.expr()]
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v.append(self.expr())
self.match(veclexer.RBRACK)
return v
def consume(self):
self.cur_token = self.lexer.next_token()
def match(self, token_type):
if self.cur_token[0] == token_type:
self.consume()
return True
raise Exception('expecting %s; found %s' % (token_type, self.cur_token[0]))
if __name__ == '__main__':
prog = '''''
veca = [1, 2, 3]
vecb = [4, 5, 6]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
print 'veca + vecb:', veca + vecb
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb
print 'veca:', veca
print 'vecb:', vecb
'''
lex = veclexer.Veclexer(prog)
parser = Vecparser(lex)
parser.statlist()
运行代码便会得到之前介绍中的输出内容。这个解释器极其简陋,只实现了基本的表达式操作,所以不需要构建语法树。如果要为列表语言添加控制结构,就必须实现语法树,在语法树的基础上去解释执行。

 Pythonの学習:2時間の毎日の研究で十分ですか?Apr 18, 2025 am 12:22 AM
Pythonの学習:2時間の毎日の研究で十分ですか?Apr 18, 2025 am 12:22 AMPythonを1日2時間学ぶだけで十分ですか?それはあなたの目標と学習方法に依存します。 1)明確な学習計画を策定し、2)適切な学習リソースと方法を選択します。3)実践的な実践とレビューとレビューと統合を練習および統合し、統合すると、この期間中にPythonの基本的な知識と高度な機能を徐々に習得できます。
 Web開発用のPython:主要なアプリケーションApr 18, 2025 am 12:20 AM
Web開発用のPython:主要なアプリケーションApr 18, 2025 am 12:20 AMWeb開発におけるPythonの主要なアプリケーションには、DjangoおよびFlaskフレームワークの使用、API開発、データ分析と視覚化、機械学習とAI、およびパフォーマンスの最適化が含まれます。 1。DjangoandFlask Framework:Djangoは、複雑な用途の迅速な発展に適しており、Flaskは小規模または高度にカスタマイズされたプロジェクトに適しています。 2。API開発:フラスコまたはdjangorestFrameworkを使用して、Restfulapiを構築します。 3。データ分析と視覚化:Pythonを使用してデータを処理し、Webインターフェイスを介して表示します。 4。機械学習とAI:Pythonは、インテリジェントWebアプリケーションを構築するために使用されます。 5。パフォーマンスの最適化:非同期プログラミング、キャッシュ、コードを通じて最適化
 Python vs. C:パフォーマンスと効率の探索Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索Apr 18, 2025 am 12:20 AMPythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Python in Action:実世界の例Apr 18, 2025 am 12:18 AM
Python in Action:実世界の例Apr 18, 2025 am 12:18 AMPythonの実際のアプリケーションには、データ分析、Web開発、人工知能、自動化が含まれます。 1)データ分析では、PythonはPandasとMatplotlibを使用してデータを処理および視覚化します。 2)Web開発では、DjangoおよびFlask FrameworksがWebアプリケーションの作成を簡素化します。 3)人工知能の分野では、TensorflowとPytorchがモデルの構築と訓練に使用されます。 4)自動化に関しては、ファイルのコピーなどのタスクにPythonスクリプトを使用できます。
 Pythonの主な用途:包括的な概要Apr 18, 2025 am 12:18 AM
Pythonの主な用途:包括的な概要Apr 18, 2025 am 12:18 AMPythonは、データサイエンス、Web開発、自動化スクリプトフィールドで広く使用されています。 1)データサイエンスでは、PythonはNumpyやPandasなどのライブラリを介してデータ処理と分析を簡素化します。 2)Web開発では、DjangoおよびFlask Frameworksにより、開発者はアプリケーションを迅速に構築できます。 3)自動化されたスクリプトでは、Pythonのシンプルさと標準ライブラリが理想的になります。
 Pythonの主な目的:柔軟性と使いやすさApr 17, 2025 am 12:14 AM
Pythonの主な目的:柔軟性と使いやすさApr 17, 2025 am 12:14 AMPythonの柔軟性は、マルチパラダイムサポートと動的タイプシステムに反映されていますが、使いやすさはシンプルな構文とリッチ標準ライブラリに由来しています。 1。柔軟性:オブジェクト指向、機能的および手続き的プログラミングをサポートし、動的タイプシステムは開発効率を向上させます。 2。使いやすさ:文法は自然言語に近く、標準的なライブラリは幅広い機能をカバーし、開発プロセスを簡素化します。
 Python:汎用性の高いプログラミングの力Apr 17, 2025 am 12:09 AM
Python:汎用性の高いプログラミングの力Apr 17, 2025 am 12:09 AMPythonは、初心者から上級開発者までのすべてのニーズに適した、そのシンプルさとパワーに非常に好まれています。その汎用性は、次のことに反映されています。1)学習と使用が簡単、シンプルな構文。 2)Numpy、Pandasなどの豊富なライブラリとフレームワーク。 3)さまざまなオペレーティングシステムで実行できるクロスプラットフォームサポート。 4)作業効率を向上させるためのスクリプトおよび自動化タスクに適しています。
 1日2時間でPythonを学ぶ:実用的なガイドApr 17, 2025 am 12:05 AM
1日2時間でPythonを学ぶ:実用的なガイドApr 17, 2025 am 12:05 AMはい、1日2時間でPythonを学びます。 1.合理的な学習計画を作成します。2。適切な学習リソースを選択します。3。実践を通じて学んだ知識を統合します。これらの手順は、短時間でPythonをマスターするのに役立ちます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

ドリームウィーバー CS6
ビジュアル Web 開発ツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

