
ホームページ >バックエンド開発 >Python チュートリアル >Python は Srapy フレームワーク クローラーを使用してログインをシミュレートし、Zhihu コンテンツをクロールします
Python は Srapy フレームワーク クローラーを使用してログインをシミュレートし、Zhihu コンテンツをクロールします

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-07-22 08:56:301894ブラウズ
1. クッキーの原則
HTTPはステートレスな接続指向プロトコルであり、接続状態を維持するためにCookieメカニズムが導入されています
。
Cookie は http メッセージ ヘッダーの属性であり、次のものが含まれます:
- Cookie名(Name) Cookie値(Value)
- Cookieの有効期限(Expires/Max-Age)
- Cookieアクションパス(パス)
- Cookie が配置されているドメイン名 (Domain)、安全な接続に Cookie を使用する (Secure)
最初の 2 つのパラメータは、Cookie の適用に必要な条件です。さらに、Cookie のサイズも含まれます (サイズ、ブラウザごとに Cookie の数とサイズの制限が異なります)。
2. 模擬ログイン
今回クロールしたメインWebサイトはZhihuです
Zhihu をクロールするにはログインする必要があります。以前の組み込み Python ライブラリを通じて、フォーム送信を簡単に実装できます。
それでは、Scrapy を介してフォーム送信を実装する方法を見てみましょう。
まずはログイン時にフォームの結果を確認します。先ほどの手法と同様に、意図的に間違ったパスワードを入力し、ログインページのヘッダーとフォームをキャプチャしました(Chrome付属の開発者ツールのネットワーク機能を使用しました)
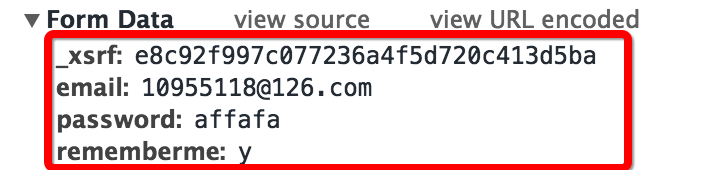
キャプチャされたフォームを見ると、4 つの部分があることがわかります:
- メールアドレスとパスワードは個人ログイン用のメールアドレスとパスワードです
- rememberme フィールドはアカウントを記憶するかどうかを示します
- 最初のフィールドは _xsrf です。これは検証メカニズムだと思われます
- あとは _xsrf だけが知りません。Web ページをリクエストするときにこの検証フィールドが必ず送信されると思いますので、現在の Web ページのソース コードを確認してみましょう (マウスを右クリックして Web ページのソース コードを表示するか、ショートカットキーを直接使用してください)
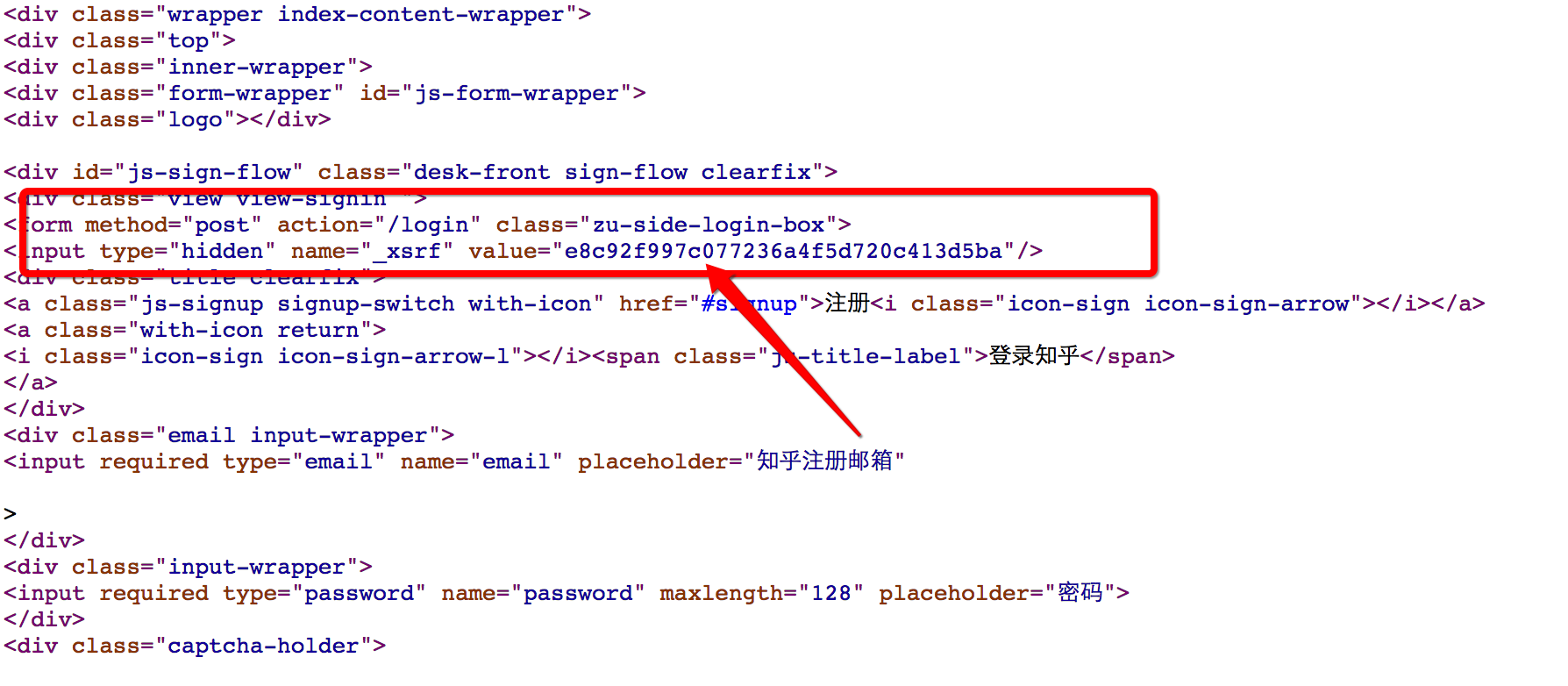
私たちの推測が正しかったかどうかを確認してください
これでフォームログイン関数を書くことができます
主な機能は機能のコメントで説明しています
3. クッキーの保存
同じ状態を使用してウェブサイトを継続的にクロールするには、Cookie を保存し、Cookie を使用して状態を保存する必要があります。Scrapy は、直接使用できる Cookie 処理ミドルウェアを提供します。
この Cookie ミドルウェアは、Web サーバーによって送信された Cookie を保存および追跡し、次のリクエストでこの Cookie を送信します
Scrapy の公式ドキュメントには次のコード例が記載されています:
リーリー
4. 頭を変装する
Web サイトにログインするには、ホットリンクを防ぐためのヘッダーの追加やサーバー ログインのシミュレートなど、ヘッダーの偽装が必要になる場合があります
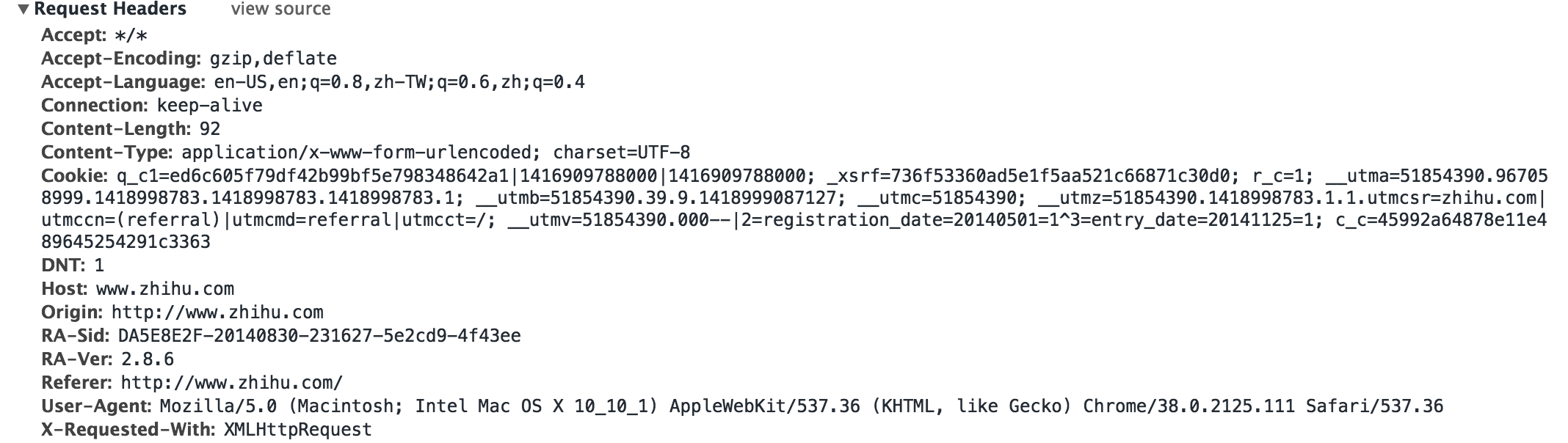
保険の場合、次のようにヘッダーにさらに多くのフィールドを入力できます
リーリー
ログイン関数の最終バージョンを形成する
リーリー
Zhihu クローラー コードの完全なリンク
リーリー
詳細な設定については、公式ドキュメントをご覧ください
リーリー
ルール設計では Web サイトの完全なクロールを実現することはできませんが、簡単な質問のクロールのみを設定します
- Xpath 設定は厳密ではないため、再検討する必要があります
- Unicode エンコードは UTF-8 に変換する必要があります