


モデレーター、また助けが必要です。 。 。これは、Web ページによって返された XML データです。simplexml で読み取れない理由はわかりません。var_dump は false を示します
echo '#########################'.'</br></br>'; var_dump($xml); echo '#########################'; echo '<br>'.'<br>'.'<br>'.$xml->xsm->nickname;
上記の段落を使用して直接印刷すると、次のようになります。
echo '#########################'.'</br></br>'; var_dump(simplexml_load_string($xml); echo '#########################'; echo '<br>'.'<br>'.'<br>'.$xml->xsm->nickname;
このコードを使用して表示します bool (false)
解決策を求める
ディスカッションに返信 (解決策)
$xml = preg_replace('/!|--/', '', $xml);var_dump(simplexml_load_string($xml));
$xml = preg_replace('/!|--/', '', $xml);var_dump(simplexml_load_string($xml));
//$xml='<!--?xml version="1.0" encoding="gbk"?-->'; $xml = preg_replace('/!--\?|--/','', $xml); var_dump($xml); これを試してみましたが、一行でできます正しく一致しますが、このコードでは無効です。 Web 要素ビューアでは、戻り値にまだコメント文字が含まれていることがわかります なぜ賢くする必要があるのですか?分かりましたので、別の方法を考えたのですが、やはり失敗しました、理由を教えていただけますか?
$xml = preg_replace('/!|--/', '', $xml);var_dump(simplexml_load_string($xml)); XML ファイル タグの行を追加するために文字列演算子を使用しましたが、simplexml_load_string を使用しても失敗しました
では、なぜ賢くなろうとしているのですか
渡してください コードを貼り付けてもロードできません...
それは、あなたが私にデータを渡さないからです
それから、なぜあなたはそんなに賢くなければなりません
これは私の後ですコードを直接コピーして貼り付けて実行すると、結果は...
ダンプするには、simplexml の読み込みステートメントを削除する必要があります
スクリーンショットを撮るだけでは役に立ちません。
印刷できない文字が含まれていないことをどのようにして確認できますか?
それはあなたが私にデータを渡さないからです
$xml = '<xml version="1.0" encoding="gbk"?>'.$xml; var_dump(simplexml_load_string($xml));これは fwrite を使用して書いた $xml の値です
コメントアウトされたファイルマークはありませんが、なぜロードできないのかわかりません
スクリーンショットを撮るだけでは意味がありません!
印刷できない文字が含まれていないことをどのようにして確認できますか?IE で表示すると、
終了タグ 'xsm' が開始タグ 'comShort' と一致しません。
<?xml version="1.0" encoding="gbk"?><xsm code="0000" msg="验证成功abc" trans_time="20140808162708"><userId>114</userId><nickName>wedc</nickName><userType>2</userType><comId>116</comId><saledptId>11601</saledptId><refId>1062014</refId><comName></comName><domainUrl>v=2014080600</domainUrl><comType>02</comType><comShort></comShort><parentComId>11620001</parentComId><expirationTime>1407488228735</expirationTime><planText>10116226011162288228735</planText><signatureValue>c6959b4eacf7b2f</signatureValue></xsm>これでいいんじゃないの?
スクリーンショットに表示されている文字列の長さは 984 バイトですが、投稿した文字列の長さはわずか 509 バイトです。
400 バイト以上はどこへ行ったのでしょうか?
スクリーンショットを撮るだけではダメです!
印刷できない文字が含まれていないことをどのようにして確認できますか?
モデレーターさん、原因は中国語が含まれているため読み込めないことですが、どうすれば解決できますか?自分のデータではないので変更できません
SimpleXMLElement Object( [@attributes] => Array ( [code] => 0000 [msg] => 验证成功abc [trans_time] => 20140808162708 ) [userId] => 114 [nickName] => wedc [userType] => 2 [comId] => 116 [saledptId] => 11601 [refId] => 1062014 [comName] => SimpleXMLElement Object ( ) [domainUrl] => v=2014080600 [comType] => 02 [comShort] => SimpleXMLElement Object ( ) [parentComId] => 11620001 [expirationTime] => 1407488228735 [planText] => 10116226011162288228735 [signatureValue] => c6959b4eacf7b2f)これでいいんじゃないでしょうか?
スクリーンショットに表示されている文字列の長さは 984 バイトですが、投稿した文字列の長さはわずか 509 バイトです。
400 バイト以上はどこへ行ったのでしょうか?
残りの400バイトは長い文字列だったので半分削除しました ありがとうございます、原因が分かりました、PHPがutf8でエンコードされていて、取得したxmlデータがgbkなので、Changing gbkをutf8に入れてください問題は解決します
SimpleXMLElement Object( [@attributes] => Array ( [code] => 0000 [msg] => 验证成功abc [trans_time] => 20140808162708 ) [userId] => 114 [nickName] => wedc [userType] => 2 [comId] => 116 [saledptId] => 11601 [refId] => 1062014 [comName] => SimpleXMLElement Object ( ) [domainUrl] => v=2014080600 [comType] => 02 [comShort] => SimpleXMLElement Object ( ) [parentComId] => 11620001 [expirationTime] => 1407488228735 [planText] => 10116226011162288228735 [signatureValue] => c6959b4eacf7b2f)これは不可能ですか?
スクリーンショットに表示されている文字列の長さは 984 バイトですが、投稿した文字列の長さはわずか 509 バイトです。 400 バイト以上はどこへ行ったのでしょうか?
成功 ~~~~~~[]

 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
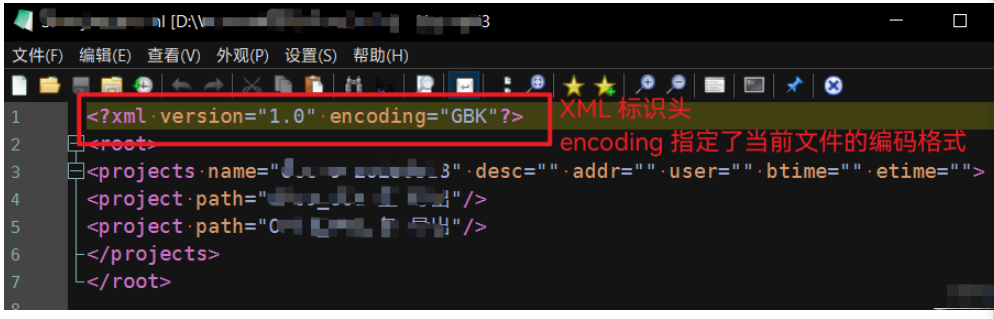 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境
ホットトピック
 7430
7430 15135952
15135952