
ホームページ >バックエンド開発 >PHPチュートリアル >mysqlで同じフィールドデータを持つ2つのレコードを削除するにはどうすればよいですか?
mysqlで同じフィールドデータを持つ2つのレコードを削除するにはどうすればよいですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-06-17 08:32:151738ブラウズ
たとえば、name 列と eamil 列があり、データベースにレコードが存在する場合、これら 2 つの列の値は同じです (これに対応する 2 つの列の値について話しています)値が同じである場合、他の冗長な列は自動的に削除され、最新の列 (つまり、ID が最も小さい列) が保持されます。 ID は自動インクリメントされる主キーです)
———————————————— ————
つまり、テーブルにはその名前のレコードが 2 つあります。どちらも管理者で、メールアドレスは abc@163.com です。どちらか一方だけを保持したいのですが、どうすればよいですか?
返信内容:
実際に英語で検索してみると。スタック オーバーフローに関する関連情報は簡単に見つかります。本当に CS を学びたい場合は、Baidu を使用しないでください。SQL を投稿するだけで、別の世界が見つかります。
アイデアの 1 つについてお話しましょう (良い答えがたくさんあります。自分で調べてください)
それは、グループを作成して保持することです。最大の ID を持つもの (自動インクリメントと言いました。最大の ID を持つものが最新である必要があります)
特定の SQL クエリは次のように記述できます
明確な
ID の最小値を保持したい場合は、例:
 Execute sql:select count(*) as count ,name,id from ceshi group by name
Execute sql:select count(*) as count ,name,id from ceshi group by name
削除される最後の SQL SQL は次のとおりです: ID が入っていない ceshi から削除 (名前で ceshi グループから count ,name,id として count(*) を選択)
最大値を保持したい場合id の値:
簡単な方法は次のとおりです。id が含まれていない ceshi から削除します (count (*) を count ,name,id から選択します (select * from ceshi order by id desc) group by name) 明確な 実際には非常に簡単で、テーブルを 2 つのテーブルとして扱うだけです。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id
ここに質問があります、質問者はこう言いました。最新のものを保持する どれ(つまりIDが小さいもの)が増えているので、最新のものを一番大きくすればいいのではないでしょうか?
上記のステートメントでは、p1.id もちろん、group by, count を使用すると、n 回繰り返す状況をより正確に制御できます。ただし、元の投稿者のニーズに応じて、重複したものを削除し、最新のものを保持する必要があります。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table はテーブル名、field は必要な重複フィールドを削除します。 新しいテーブルを作成し、名前と電子メールを一意のインデックスとして設定し、古いテーブル データを再挿入します。
<code class="language-sql"><span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span> <span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span> <span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span> </code>Data:
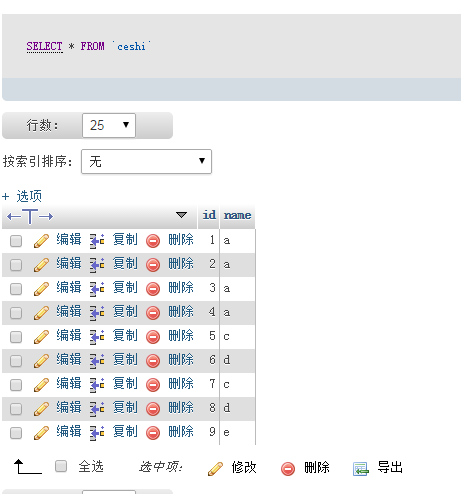
 Execute sql:select count(*) as count ,name,id from ceshi group by name
Execute sql:select count(*) as count ,name,id from ceshi group by name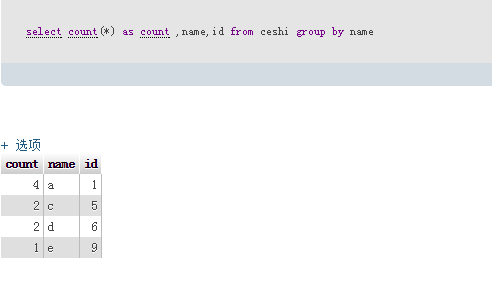 削除される最後の SQL SQL は次のとおりです: ID が入っていない ceshi から削除 (名前で ceshi グループから count ,name,id として count(*) を選択)
削除される最後の SQL SQL は次のとおりです: ID が入っていない ceshi から削除 (名前で ceshi グループから count ,name,id として count(*) を選択)最大値を保持したい場合id の値:
簡単な方法は次のとおりです。id が含まれていない ceshi から削除します (count (*) を count ,name,id から選択します (select * from ceshi order by id desc) group by name) 明確な 実際には非常に簡単で、テーブルを 2 つのテーブルとして扱うだけです。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id
ここに質問があります、質問者はこう言いました。最新のものを保持する どれ(つまりIDが小さいもの)が増えているので、最新のものを一番大きくすればいいのではないでしょうか?
上記のステートメントでは、p1.id もちろん、group by, count を使用すると、n 回繰り返す状況をより正確に制御できます。ただし、元の投稿者のニーズに応じて、重複したものを削除し、最新のものを保持する必要があります。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table はテーブル名、field は必要な重複フィールドを削除します。 新しいテーブルを作成し、名前と電子メールを一意のインデックスとして設定し、古いテーブル データを再挿入します。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。