
ホームページ >バックエンド開発 >Python チュートリアル >Python コーディングのピットクライミングガイド (必読)
Python コーディングのピットクライミングガイド (必読)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-06-16 08:47:571294ブラウズ
私は最近 Python を勉強しています。これは非常に短く簡潔な言語であり、その簡潔さの背後にある強力な関数ライブラリがとても気に入っています。しかし、それに触ってすぐに、コーディングに関する厄介な問題に遭遇しました。インターネットで多くの情報を調べたので、将来の兄弟姉妹にも役立つようにここにまとめておきます。少しでもあなたの時間を節約できれば、Ben Lu に大変光栄に存じます。
まず現象を説明しましょう:
import os
for i in os.listdir("E:\Torchlight II"):
print i
コードは非常に単純です。OS の listdir 関数を使用してディレクトリ E:Torchlight II (Torchlight?!:)) を検索します。このディレクトリ内の一部のファイルは中国語で名前が付けられているため、印刷時に表示されます。最終結果は次のように文字化けします:
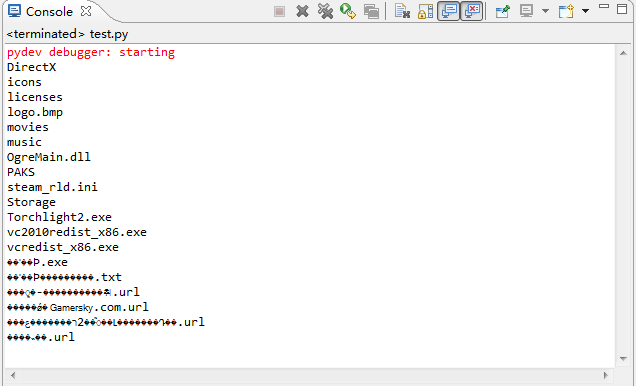
それで、何が問題なのでしょうか? 心配しないで、少しずつ分析してみましょう。
ここ と ここ から、問題は次のとおりであることがほぼ確実にわかります:
This means that the python console app can't write the given character to the console's encoding. More specifically, the python console app created a _io.TextIOWrapperd instance with an encoding that cannot represent the given character. sys.stdout --> _io.TextIOWrapperd --> (your console)
これを見て、あなたも私と同じ考えだと思いますが、コンソールのエンコードを中国語が理解できるものに設定していただければ、正常に中国語を表示できるのではないでしょうか?待って、しばらく Google で調べてみましょう、
Python determines the encoding of stdout and stderr based on the value of the LC_CTYPE variable, but only if the stdout is a tty. So if I just output to the terminal, LC_CTYPE (or LC_ALL) define the encoding. However, when the output is piped to a file or to a different process, the encoding is not defined, and defaults to 7-bit ASCII.
さらに詳しい手順は次のとおりです:
1). When Python finds its output attached to a terminal, it sets the sys.stdout.encoding attribute to the terminal's encoding. The print statement's handler will automatically encode unicode arguments into str output. 2). When Python does not detect the desired character set of the output, it sets sys.stdout.encoding to None, and print will invoke the "ascii" codec.
ほほう、今のアイデアは実現可能ですが、システム設定を変更する必要があるため、あまり洗練されていないようです。実際、上記の説明は Linux 環境に基づいています。Windows の場合、コンソールのエンコード設定は地域の設定に基づきます。関連するオペレーティング システム。たとえば、中国の win7 環境では、コンソールのデフォルトのエンコーディングは GBK (cp936) です。次のコードを試してみてください:
import locale print locale.getdefaultlocale()[1]
コンソールのエンコードを設定するのは簡単ではありません。目的を達成するために stdout.out.encoding を設定できますか?残念ながら、答えはノーです。この男は読み取り専用です:

他に方法はないのでしょうか?いいえ、実際、私たちは成功に非常に近づいています。上記で取得した情報を分析して整理し、現在の状況を確認してください。
1). console不能正常显示中文,console的编码是由操作系统决定的(windows环境下); 2). 我的操作系统是win7中文版(GBK),enc = locale.getdefaultlocale()[1]; 3). console的编码决定了sys.stdout.encoding的取值,sys.stdout.encoding = utf-8; 4). 从操作系统枚举目录(E:\Torchlight II)列表返回的字符串也是GBK编码
問題を見たことがありますか?上のスクリーンショットにある奇妙な疑問符と鋭い角は、文字列自体が gbk に従ってエンコードされているためですが、sys.stdout.encoding = utf-8 であるため、print は入力データを utf-8 に従ってエンコードし、unicode に変換します。文字。もちろん、これは間違いです。理由は明らかです。コードを変更しましょう:
import os
for i in os.listdir("E:\Torchlight II"):
print i.decode('gbk')
コードでは、読み取った文字列を gbk エンコーディングに従ってデコードするように Python に手動で指示しています。このアクションの後、データはすでに標準 Unicode 文字になっており、出力のために安全に渡すことができます。この時点では sys.stdout.encoding = utf-8 であっても):
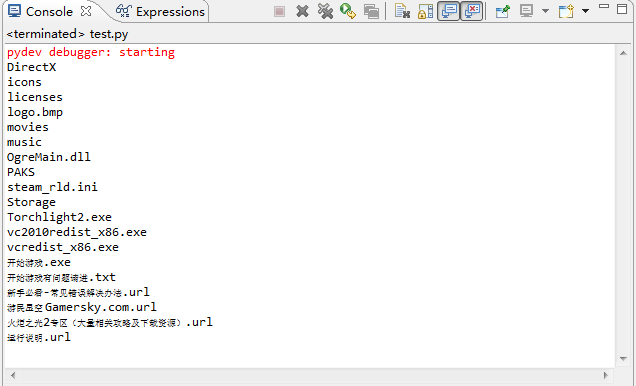
ps:
実際、関連する同様のコーディングの問題を Google で多数見つけました。たとえば、 は であり、 は です。問題の外観は常に変化しており、解決策は多様であり、ここ など、Python 独自の特定の解決策さえあります。しかし、これらの問題の本質はすべて文字のエンコードとデコードに関するものであり、本質を理解すれば、すべての問題は簡単に解決できます。
Python コーディングの穴を登るための上記のガイド (必読) は、編集者によって共有されたすべての内容です。参考にしていただければ幸いです。また、Script Home をさらにサポートしていただければ幸いです。