
ホームページ >バックエンド開発 >Python チュートリアル >Python の詳細な学習のメモリ管理
Python の詳細な学習のメモリ管理

- WBOYオリジナル
- 2016-06-16 08:42:121032ブラウズ
言語メモリ管理は言語設計の重要な側面です。これは言語のパフォーマンスを決定する重要な要素です。 C 言語での手動管理であれ、Java でのガベージ コレクションであれ、それらは言語の最も重要な機能となっています。ここでは、動的に型付けされたオブジェクト指向言語のメモリ管理方法を説明するために、Python 言語を例に挙げます。
オブジェクトのメモリ使用量
代入ステートメントは、この言語の最も一般的な機能です。しかし、最も単純な代入ステートメントであっても、非常に意味のあるものになる可能性があります。 Python の代入ステートメントは研究する価値があります。
a = 1
整数 1 はオブジェクトです。そして、aは参考資料です。代入ステートメントを使用して、オブジェクト 1 を指す a を参照します。 Python は動的型付け言語 (動的型付けを参照) であり、オブジェクトと参照は分離されています。 Python は「箸」を使用して、参照を通じて実際の食べ物 (オブジェクト) に触れたりひっくり返したりします。

参照とオブジェクト
メモリ内のオブジェクトのストレージを調査するには、Python の組み込み関数 id() を使用します。オブジェクトの ID を返すために使用されます。実際、ここでのいわゆるアイデンティティは、オブジェクトのメモリ アドレスです。
a = 1 print(id(a)) print(hex(id(a)))
私のコンピュータでは次のように返されます:
11246696
'0xab9c68'
は、それぞれメモリ アドレスの 10 進数と 16 進数の表現です。
Python では、Python は再利用のために整数と短い文字をキャッシュします。 1 に等しい複数の参照を作成すると、実際にはこれらすべての参照が同じオブジェクトを指すようになります。
a = 1 b = 1 print(id(a)) print(id(b))
上記のプログラムは戻ります
11246696
11246696
a と b は実際には同じオブジェクトを指す 2 つの参照であることがわかります。
2 つの参照が同じオブジェクトを指していることを確認するには、is キーワードを使用できます。 is は、2 つの参照が指すオブジェクトが同じかどうかを判断するために使用されます。
# True a = 1 b = 1 print(a is b) # True a = "good" b = "good" print(a is b) # False a = "very good morning" b = "very good morning" print(a is b) # False a = [] b = [] print(a is b)
上記のコメントは、対応する実行結果です。ご覧のとおり、Python は整数と短い文字列をキャッシュするため、各オブジェクトのコピーは 1 つだけ保存されます。たとえば、整数 1 へのすべての参照は同じオブジェクトを指します。代入ステートメントを使用する場合でも、オブジェクト自体ではなく、新しい参照を作成するだけです。長い文字列やその他のオブジェクトには複数の同一オブジェクトを含めることができ、代入ステートメントを使用して新しいオブジェクトを作成できます。
Python では、各オブジェクトには、そのオブジェクトを指す参照の総数、つまり参照カウントがあります。
sys パッケージの getrefcount() を使用して、オブジェクトの参照カウントを表示できます。参照がパラメータとして getrefcount() に渡されると、そのパラメータは実際には一時的な参照を作成することに注意してください。したがって、getrefcount() によって得られる結果は予想より 1 多くなります。
from sys import getrefcount a = [1, 2, 3] print(getrefcount(a)) b = a print(getrefcount(b))
上記の理由により、両方の getrefcounts は、予期された 1 と 2 ではなく、2 と 3 を返します。
オブジェクト参照オブジェクト
Python のコンテナ オブジェクト (コンテナ) (テーブル、ディクショナリなど) には、複数のオブジェクトを含めることができます。実際、コンテナ オブジェクトに含まれるのは要素オブジェクトそのものではなく、各要素オブジェクトへの参照です。
オブジェクトをカスタマイズして他のオブジェクトを参照することもできます:
class from_obj(object):
def __init__(self, to_obj):
self.to_obj = to_obj
b = [1,2,3]
a = from_obj(b)
print(id(a.to_obj))
print(id(b))
ご覧のとおり、a はオブジェクト b を参照します。
オブジェクト参照オブジェクトは、Python を構造化する最も基本的な方法です。代入メソッド a = 1 でも、実際には辞書のキー値「a」を持つ要素が整数オブジェクト 1 を参照します。この辞書オブジェクトは、すべてのグローバル参照を記録するために使用されます。ディクショナリは整数オブジェクト 1 を参照します。この辞書は、組み込み関数 globals() を通じて表示できます。
オブジェクト A が別のオブジェクト B によって参照されると、A の参照カウントが 1 増加します。
from sys import getrefcount a = [1, 2, 3] print(getrefcount(a)) b = [a, a] print(getrefcount(a))
オブジェクト b は a を 2 回参照するため、a の参照数は 2 増加します。
コンテナ オブジェクトへの参照は、非常に複雑なトポロジ構造を形成する場合があります。 objgraph パッケージを使用して、
などの参照関係を描画できます。x = [1, 2, 3] y = [x, dict(key1=x)] z = [y, (x, y)] import objgraph objgraph.show_refs([z], filename='ref_topo.png')
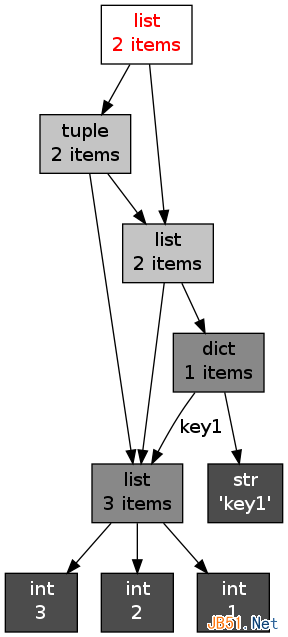
objgraph は、Python 用のサードパーティ パッケージです。インストール前に xdot をインストールする必要があります。
sudo apt-get install xdot sudo pip install objgraph
objgraph 公式ウェブサイト
2 つのオブジェクトは相互に参照し、いわゆる参照サイクルを形成することがあります。
a = [] b = [a] a.append(b)
それ自体を参照するだけでよいオブジェクトでも、参照サイクルを形成できます。
a = [] a.append(a) print(getrefcount(a))
参照リングはガベージ コレクション メカニズムに多くの問題を引き起こす可能性がありますが、これについては後ほど詳しく説明します。
見積もりの削減
オブジェクトの参照カウントが削減される可能性があります。たとえば、del キーワードを使用して参照を削除できます。
from sys import getrefcount a = [1, 2, 3] b = a print(getrefcount(b)) del a print(getrefcount(b))
del は、次のようなコンテナ要素内の要素を削除するためにも使用できます。
a = [1,2,3] del a[0] print(a)
如果某个引用指向对象A,当这个引用被重新定向到某个其他对象B时,对象A的引用计数减少:
from sys import getrefcount a = [1, 2, 3] b = a print(getrefcount(b)) a = 1 print(getrefcount(b))
垃圾回收
吃太多,总会变胖,Python也是这样。当Python中的对象越来越多,它们将占据越来越大的内存。不过你不用太担心Python的体形,它会乖巧的在适当的时候“减肥”,启动垃圾回收(garbage collection),将没用的对象清除。在许多语言中都有垃圾回收机制,比如Java和Ruby。尽管最终目的都是塑造苗条的提醒,但不同语言的减肥方案有很大的差异。

从基本原理上,当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。比如下面的表:
a = [1, 2, 3] del a
del a后,已经没有任何引用指向之前建立的[1, 2, 3]这个表。用户不可能通过任何方式接触或者动用这个对象。这个对象如果继续待在内存里,就成了不健康的脂肪。当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
然而,减肥是个昂贵而费力的事情。垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。如果内存中的对象不多,就没有必要总启动垃圾回收。所以,Python只会在特定条件下,自动启动垃圾回收。当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
我们可以通过gc模块的get_threshold()方法,查看该阈值:
import gc print(gc.get_threshold())
返回(700, 10, 10),后面的两个10是与分代回收相关的阈值,后面可以看到。700即是垃圾回收启动的阈值。可以通过gc中的set_threshold()方法重新设置。
我们也可以手动启动垃圾回收,即使用gc.collect()。
分代回收
Python同时采用了分代(generation)回收的策略。这一策略的基本假设是,存活时间越久的对象,越不可能在后面的程序中变成垃圾。我们的程序往往会产生大量的对象,许多对象很快产生和消失,但也有一些对象长期被使用。出于信任和效率,对于这样一些“长寿”对象,我们相信它们的用处,所以减少在垃圾回收中扫描它们的频率。

小家伙要多检查
Python将所有的对象分为0,1,2三代。所有的新建对象都是0代对象。当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。垃圾回收启动时,一定会扫描所有的0代对象。如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
这两个次数即上面get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。
同样可以用set_threshold()来调整,比如对2代对象进行更频繁的扫描。
import gc gc.set_threshold(700, 10, 5)
孤立的引用环
引用环的存在会给上面的垃圾回收机制带来很大的困难。这些引用环可能构成无法使用,但引用计数不为0的一些对象。
a = [] b = [a] a.append(b) del a del b
上面我们先创建了两个表对象,并引用对方,构成一个引用环。删除了a,b引用之后,这两个对象不可能再从程序中调用,就没有什么用处了。但是由于引用环的存在,这两个对象的引用计数都没有降到0,不会被垃圾回收。
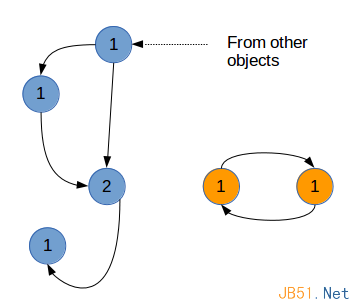
孤立的引用环
このような参照サイクルを再利用するために、Python は各オブジェクトの参照カウントをコピーします。これは gc_ref として記録できます。各オブジェクト i のカウントが gc_ref_i であるとします。 Python はすべてのオブジェクトを反復処理します。オブジェクト i によって参照される各オブジェクト j について、対応する gc_ref_j を 1 ずつ減分します。
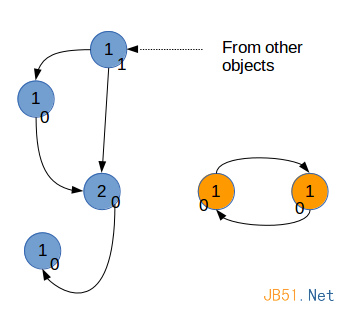
トラバース後の結果
トラバーサル終了後、gc_ref が 0 ではないオブジェクト、そのオブジェクトが参照するオブジェクト、下流で参照され続けるオブジェクトを保持する必要があります。他のオブジェクトはガベージ コレクションされます。
概要
Python は動的型付け言語として、オブジェクトと参照を分離します。これは、以前のプロセス指向言語とは大きく異なります。メモリを効果的に解放するために、Python にはガベージ コレクション サポートが組み込まれています。 Python は比較的単純なガベージ コレクション メカニズム、つまり参照カウントを採用しているため、孤立参照リングの問題を解決する必要があります。 Python には、他の言語との共通点と特別な機能の両方があります。このメモリ管理メカニズムを理解することは、Python のパフォーマンスを向上させるための重要なステップです。